Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 69
resultados
69
resultados
 Última actualización
01/05/2026 [08:56:00]
Última actualización
01/05/2026 [08:56:00]



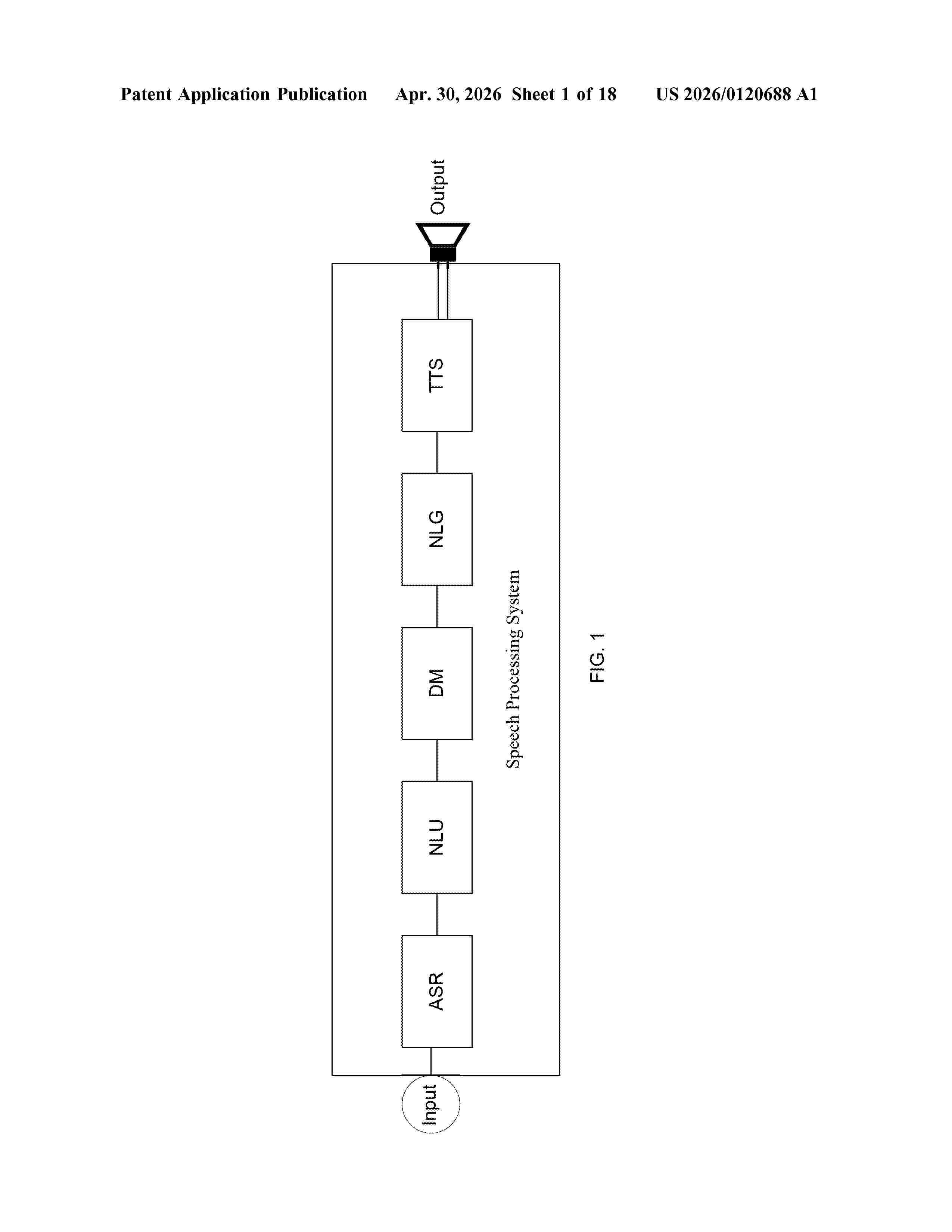
Resumen de: US20260120688A1
A method and speech processing system for communicating with a user is provided. A speech signal may be received. The received speech signal may be processed by a first unified neural network to extract one or more of intents and entities. The one or more of intents and entities may be analyzed to generate a dialogue response. A second unified neural network may generate a speech output corresponding to the dialogue response for the user. In another example, a single unified neural network may process the received speech signal to extract one or more of intents and entities. The one or more of intents and entities may be analyzed, by the single unified neural network, to generate a dialogue response. The single unified neural network may generate a speech output corresponding to the dialogue response for the user.

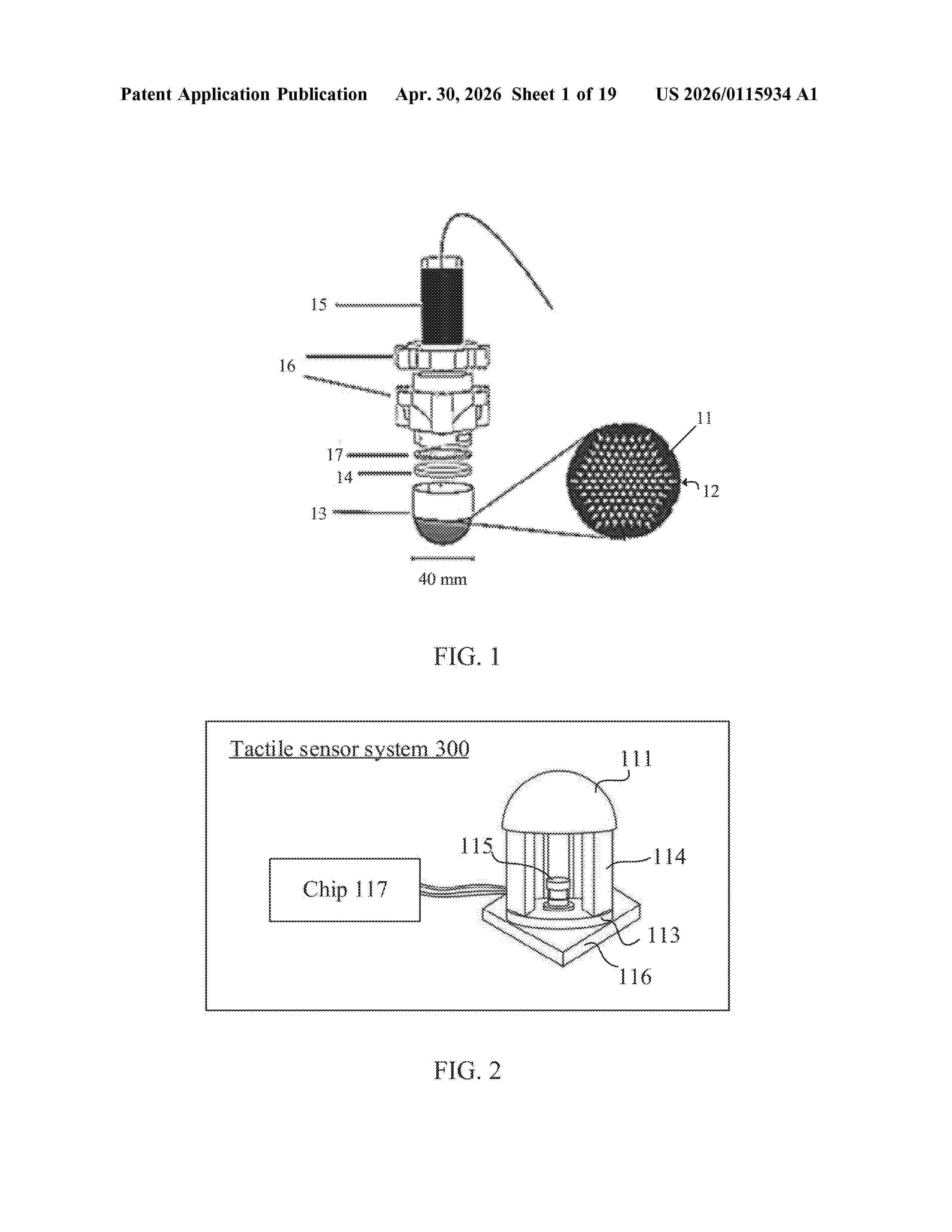
Resumen de: US20260115934A1
A vision-based tactile measurement method is provided, performed by a computer device (e.g., a chip) connected to a tactile sensor, the tactile sensor including a sensing face and an image sensing component, and the sensing face being provided with a marking pattern. The method includes: obtaining an image sequence of marking patterns distributed on a tactile sensor in physical contact with an object, wherein the marking patterns comprise a plurality of grid points connected by a plurality of grid lines; calculating a difference feature of the marking patterns between adjacent images of the image sequence, where the difference feature of the marking patterns corresponds to a displacement of the plurality of grid points and a deformation of the plurality of grid lines; and processing the difference feature of the marking patterns using a feedforward neural network to obtain a tactile measurement result of the tactile sensor.
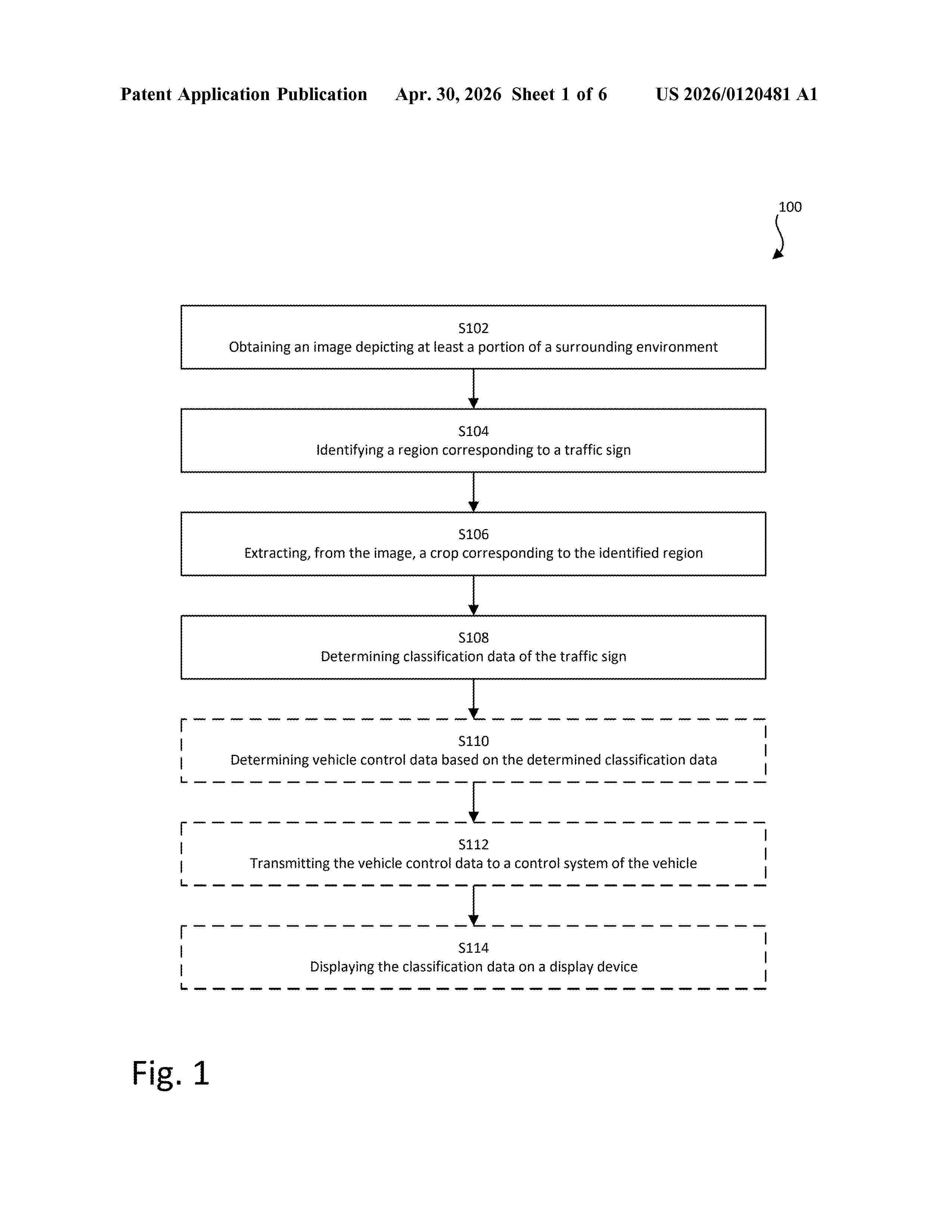
Resumen de: US20260120481A1
A computer-implemented method for classifying a traffic sign in an image, a computing device and vehicle thereof is disclosed. The method includes obtaining the image depicting at least a portion of a surrounding environment of the vehicle; identifying a region in the image corresponding to a traffic sign, by processing the image through a first machine learning model configured to output detections of traffic signs in input images; extracting a crop corresponding to the identified region, wherein the crop has a native resolution based on a size of the identified region in relation to the obtained image; and determining classification data of the traffic sign by processing the crop, at the native resolution, through a second machine learning model, wherein the second machine learning model is an attention-based neural network, trained to process input images of traffic signs of varying resolution and to generate corresponding classification data.
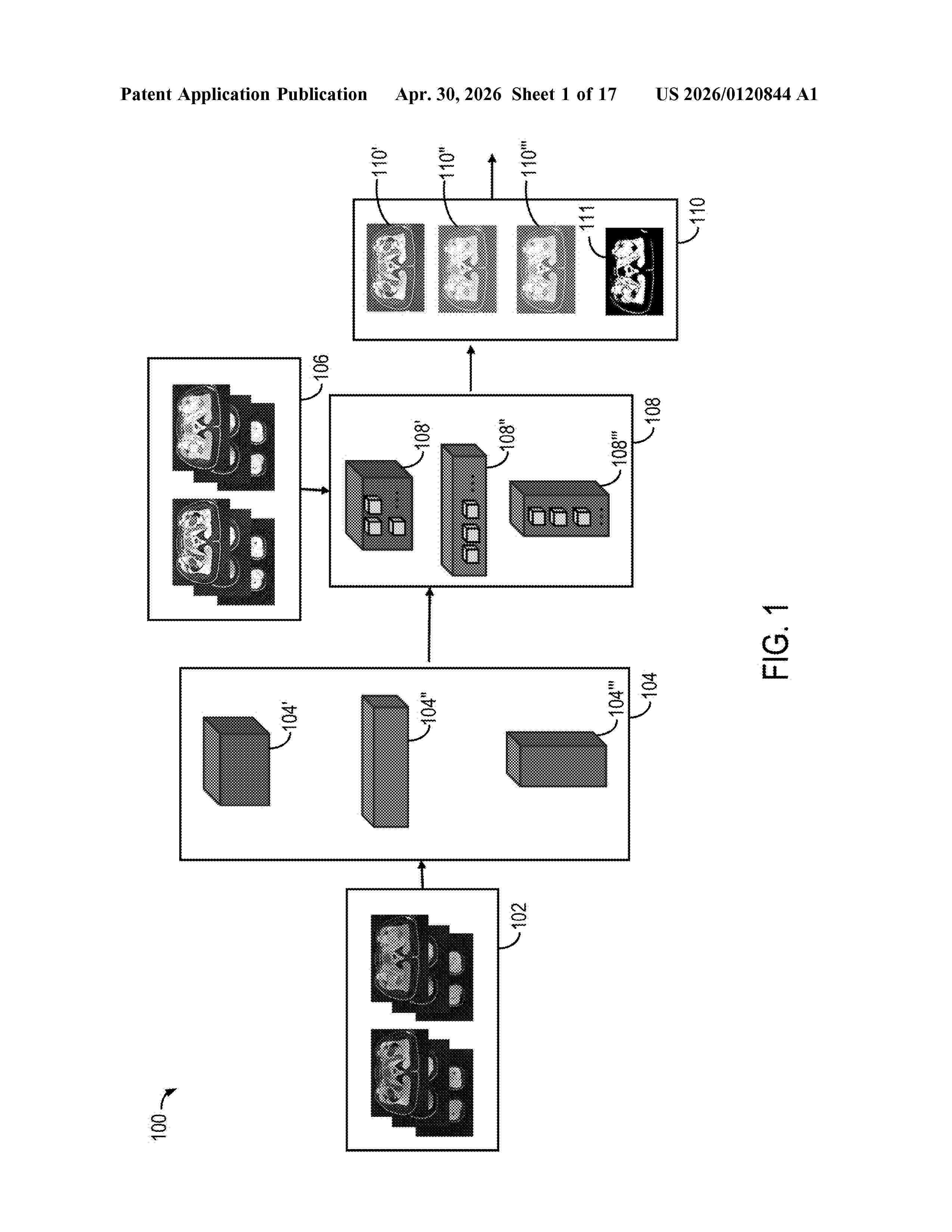
Resumen de: US20260120844A1
The present disclosure relates to systems and methods for segmenting one or more regions of interest (ROI) in medical image data. These include segmenting a plurality of medical images by inputting the plurality of medical images into each of a plurality of trained convolutional neural networks (CNNs) to identify a group of the plurality of voxels belonging to one or more ROI; calculating a plurality of variables from each of the segmented plurality of medical images on a voxel-by-voxel basis or on a ROI-by-ROI basis; generating a segmentation accuracy score from the calculated variables; and outputting a label for the one or more ROI.
Resumen de: US20260120518A1
A method performed by a data processing device, for generating a biometric encoding matrix, the method taking, as input data, a vector, of an activation map of a neural network applied to at least one image of at least one biometric datum relating to an individual, and supplying, as output datum, an encoding matrix, the method comprising generating, from the activation map, a projection matrix along a reference direction; generating a rotation matrix that leaves the reference direction invariant; and computing a composite matrix from the projection matrix and the rotation matrix, the composite matrix being the encoding matrix.
Resumen de: US20260119836A1
A method and device for interpreting a graph neural network based on FPGA acceleration propose to use FPGA hardware to accelerate interpretation process of the graph neural network oriented to node classification in parallel, and improve node traversal and shortest path search of BFS, thereby optimizing requirements of algorithm calculation and storage, and accelerating generation of interpretation results. During calculating HN values, the present disclosure optimizes multiplication operation using the matrix characteristics, transforms the dense matrix multiplication into sparse-dense matrix multiplication, and optimizes the resource occupation using multi-PE parallel processing, greatly improving performance of graph neural network interpretation acceleration. Moreover, an overall architecture based on FIFO storage calculation task distribution is designed to reduce calculation difference between nodes, solving the difficulty of high time complexity of the graph neural network interpretation method based on node classification in actual data applications and improving the time efficiency of interpretation.
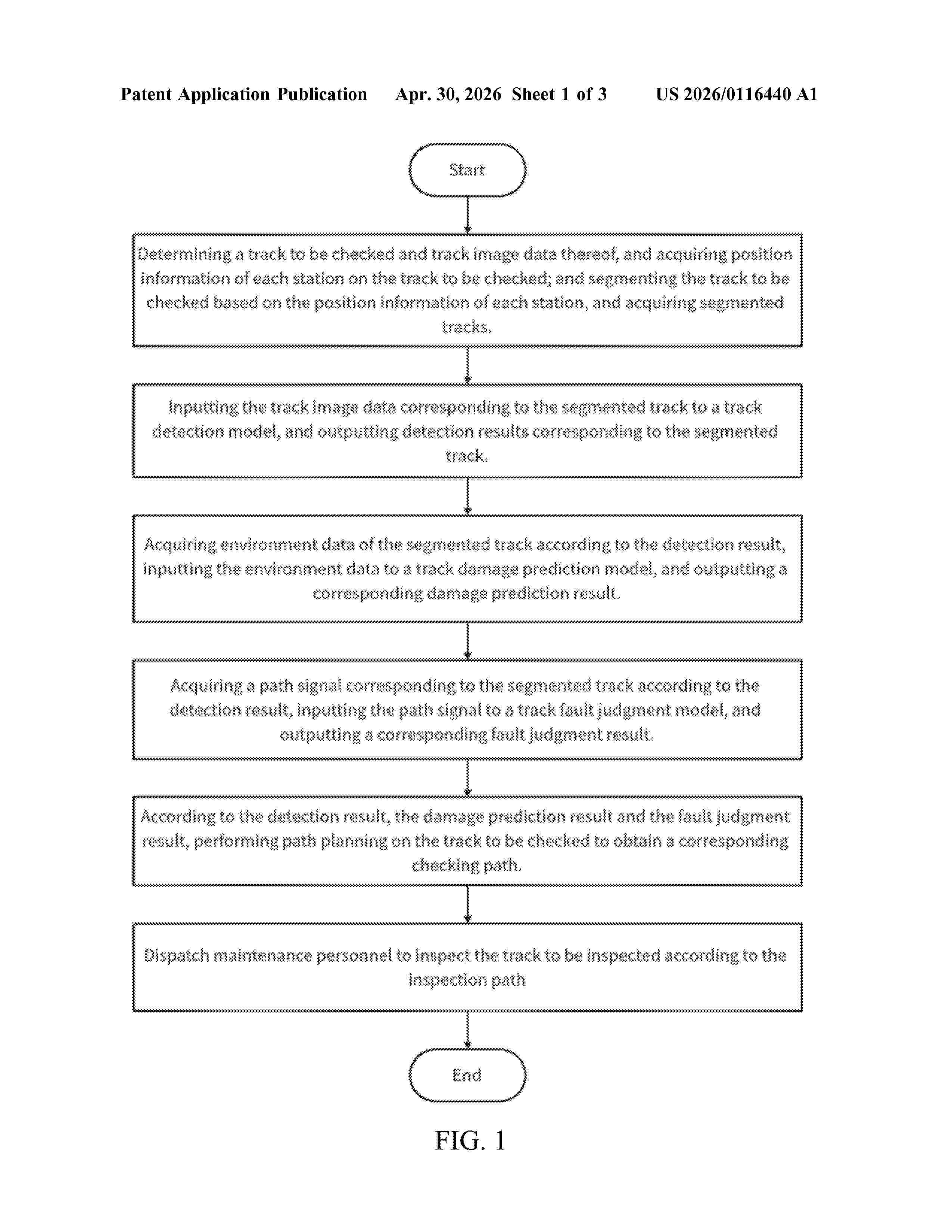
Resumen de: US20260116440A1
The invention discloses a method and system for identifying track risks based on big data analysis. The invention uses the YOLO model and SVM classifier to detect the track, extracts the multi-scale features of the track image, and can quickly and effectively detect the deformation and damage positions in the track. Based on the detection results, the RF model and BP neural network are used to further analyze the fault points of the track, and the output of each model is combined to accurately determine the fault points in the track, thereby reducing the misjudgment and omission of the fault points and providing effective support for subsequent inspection path planning. According to the fault points, the inspection path is formulated in combination with the greedy algorithm and the ant algorithm, which can effectively reduce inspection time, improve efficiency and safety of the train operation, and assist in train operation management.
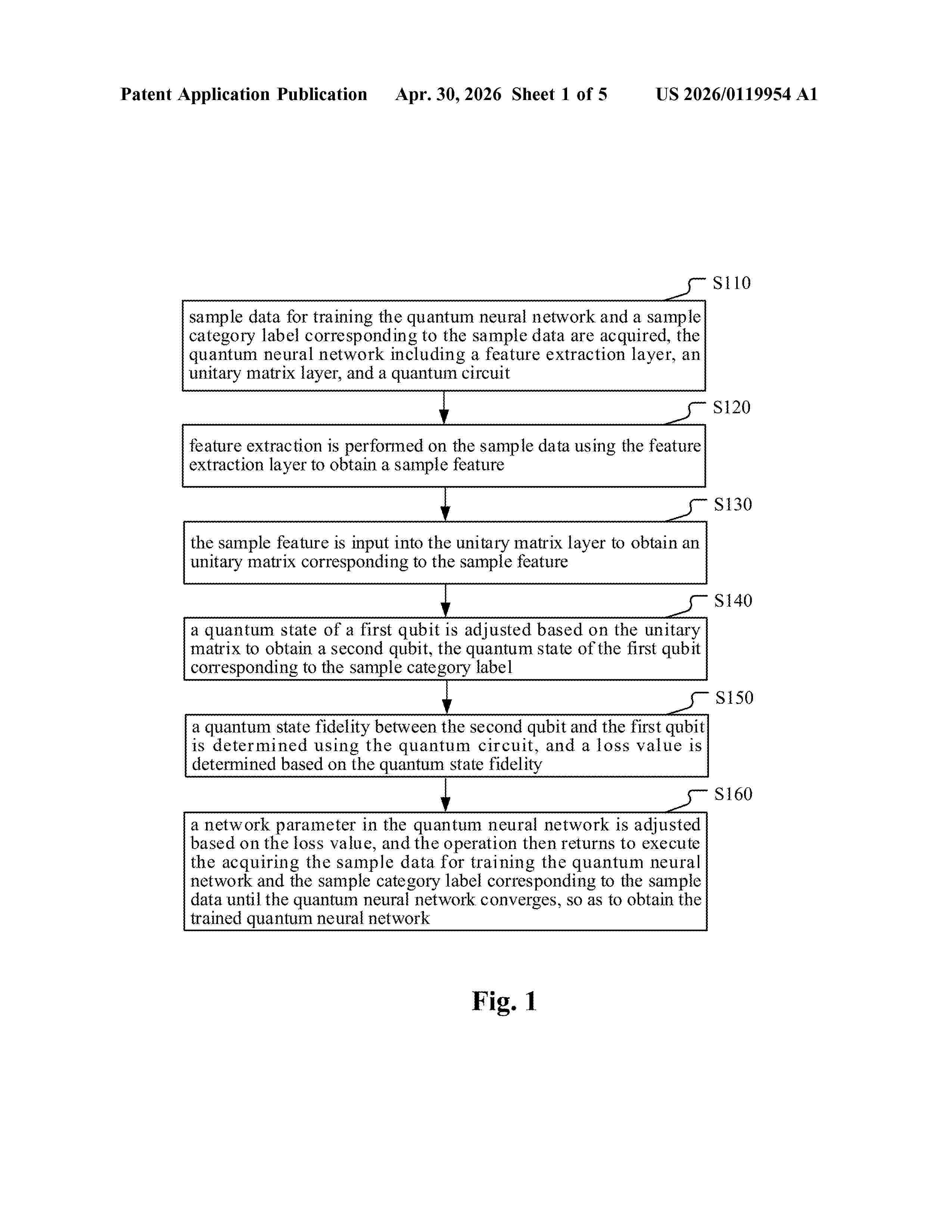
Resumen de: US20260119954A1
A method for training a quantum neural network and a method for classifying data are disclosed in the present disclosure. The method for training the quantum neural network includes acquiring sample data and a sample category label corresponding to the sample data, performing feature extraction on the sample data using a feature extraction layer of the quantum neural network, inputting the sample feature obtained by extracting into a unitary matrix layer to obtain a unitary matrix corresponding to the sample feature, adjusting a quantum state of a first qubit based on the unitary matrix to obtain a second qubit, the quantum state of the first qubit corresponds to the sample category label; determining a quantum state fidelity between the second qubit and the first qubit using the quantum circuit and then determining a loss value.
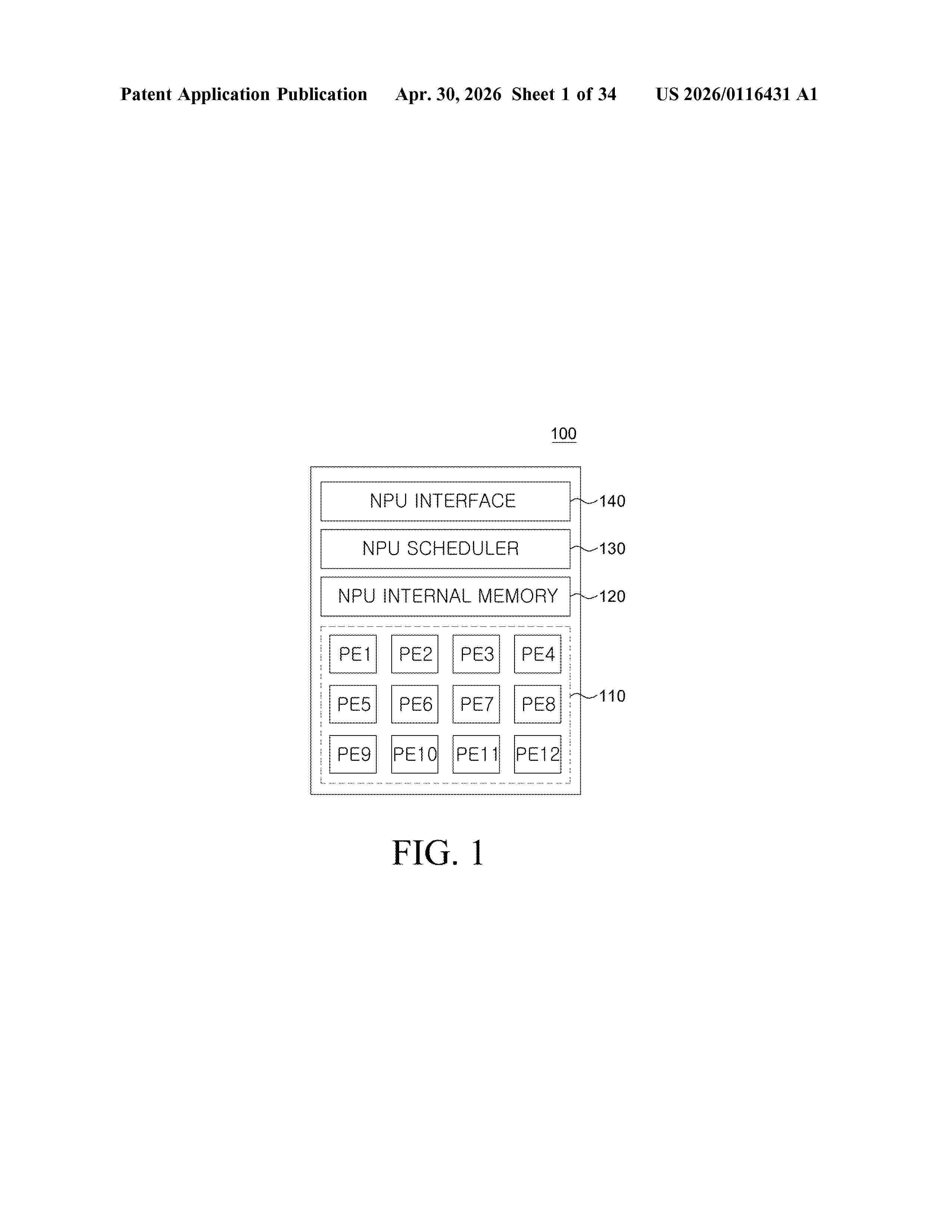
Resumen de: US20260116431A1
A neural processing unit (NPU) includes a controller including a scheduler, the controller configured to receive from a compiler a machine code of an artificial neural network (ANN) including a fusion ANN, the machine code including data locality information of the fusion ANN, and receive heterogeneous sensor data from a plurality of sensors corresponding to the fusion ANN; at least one processing element configured to perform fusion operations of the fusion ANN including a convolution operation and at least one special function operation; a special function unit (SFU) configured to perform a special function operation of the fusion ANN; and an on-chip memory configured to store operation data of the fusion ANN, wherein the schedular is configured to control the at least one processing element and the on-chip memory such that all operations of the fusion ANN are processed in a predetermined sequence according to the data locality information.
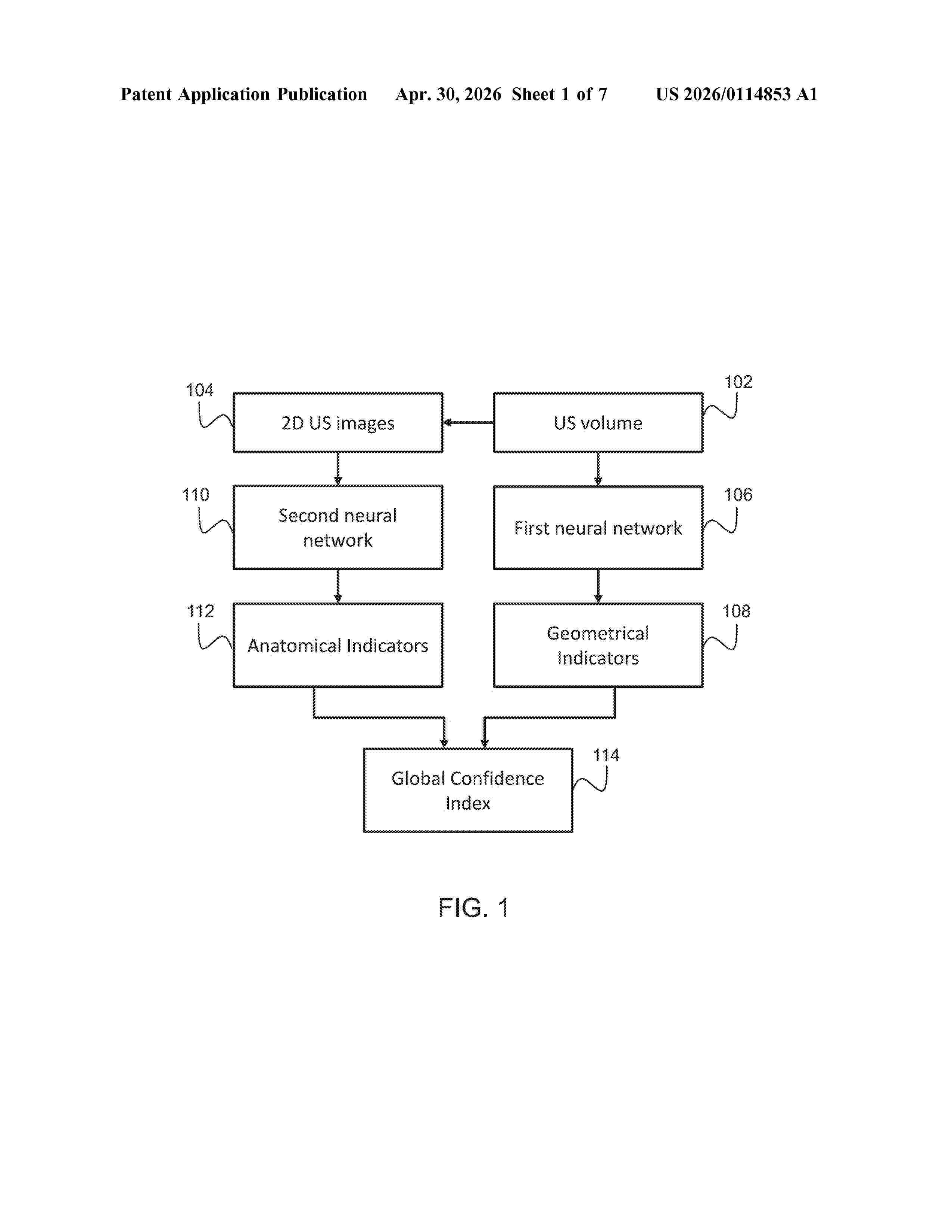
Resumen de: US20260114853A1
The invention provides a method for determining a global confidence index for a 2D ultrasound image extracted from a 3D ultrasound volume, wherein the global confidence index indicates the suitability of the 2D ultrasound image for medical measurements. The method comprises obtaining a 3D ultrasound volume of a subject and extracting a set of at least one 2D ultrasound image from the 3D ultrasound volume. A set of geometrical indicators is obtained with a previously trained first neural network, and a set of 2D ultrasound images is processed with a second neural network, wherein the output of the second neural network is a set of anatomical indicators and wherein the anatomical indicators indicate at least the presence of anatomical landmarks. A global confidence index is then determined for each one of the set of 2D ultrasound images based on the geometrical indicators and the anatomical indicators.
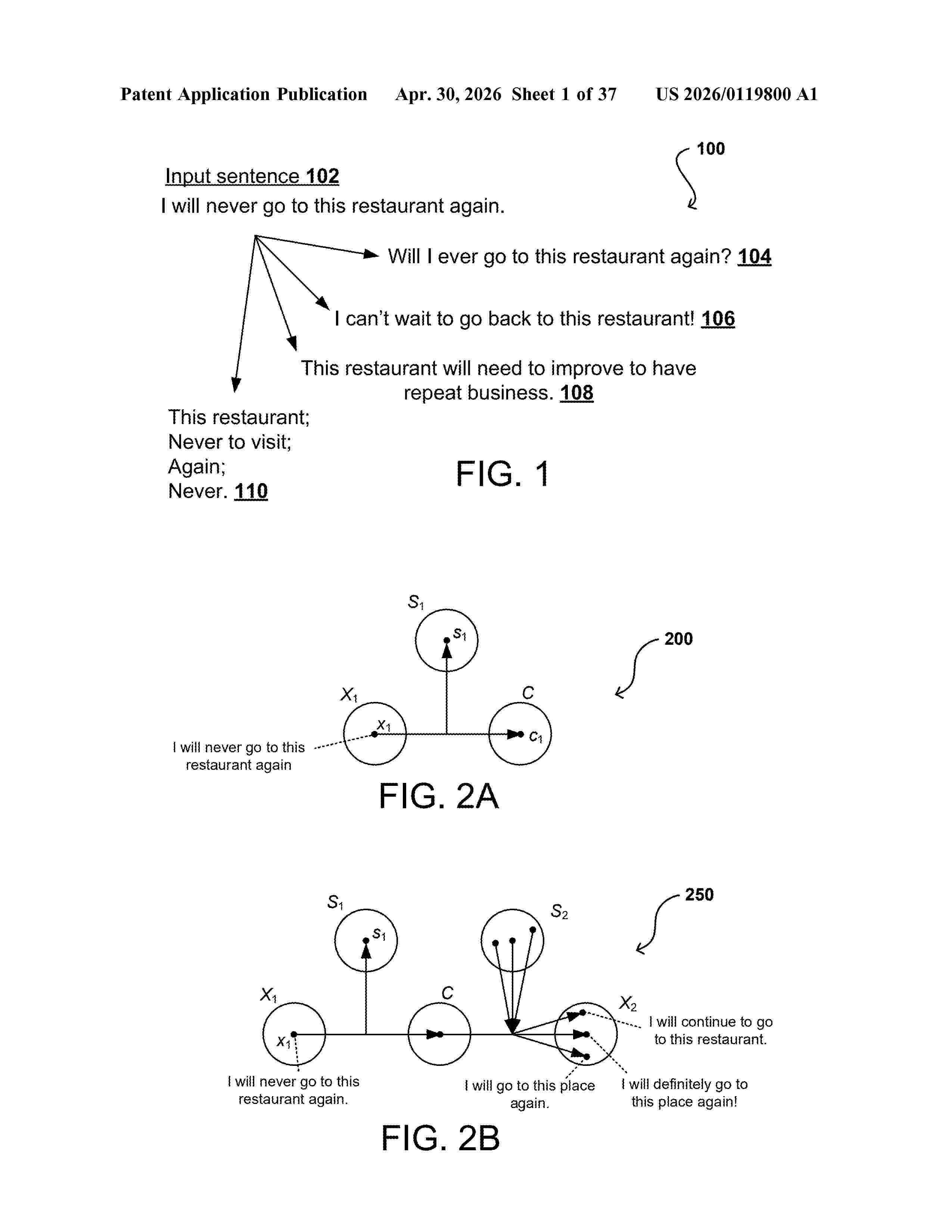
Resumen de: US20260119800A1
Apparatuses, systems, and techniques to transfer grammar between sentences. In at least one embodiment, one or more first sentences are translated into one or more second sentences having different grammar using one or more neural networks.
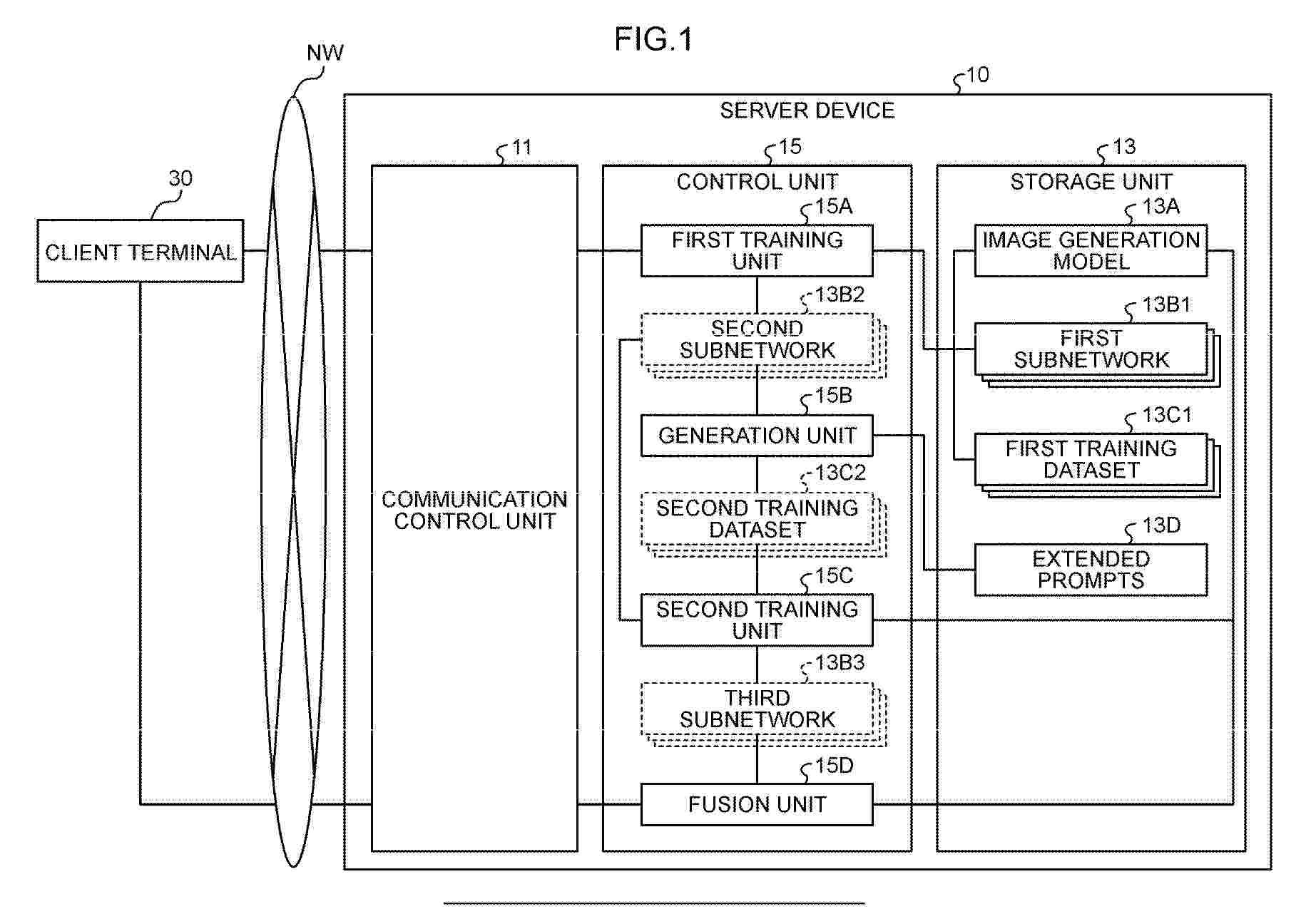
Resumen de: EP4733990A1
A generation program of a neural network is used as a subnetwork to be added to an image generation AI, the generation program causes a computer to execute a process including: training each of a plurality of neural networks using a training dataset that includes a plurality of pieces of training data where image data corresponding to specific concepts different for each of the neural networks is associated with a specific token and part of a plurality of tokens different from the specific token; and fusing the neural networks after the training to generate a subnetwork that corresponds to a plurality of concepts.
Resumen de: WO2025240481A1
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for generating an audio signal. One of the methods includes receiving an input image; processing, using one or more generative neural networks, the input image to generate a music caption describing one or more audio features corresponding to the input image; and processing, using an audio generative neural network, the music caption to generate an audio signal described by the music caption.
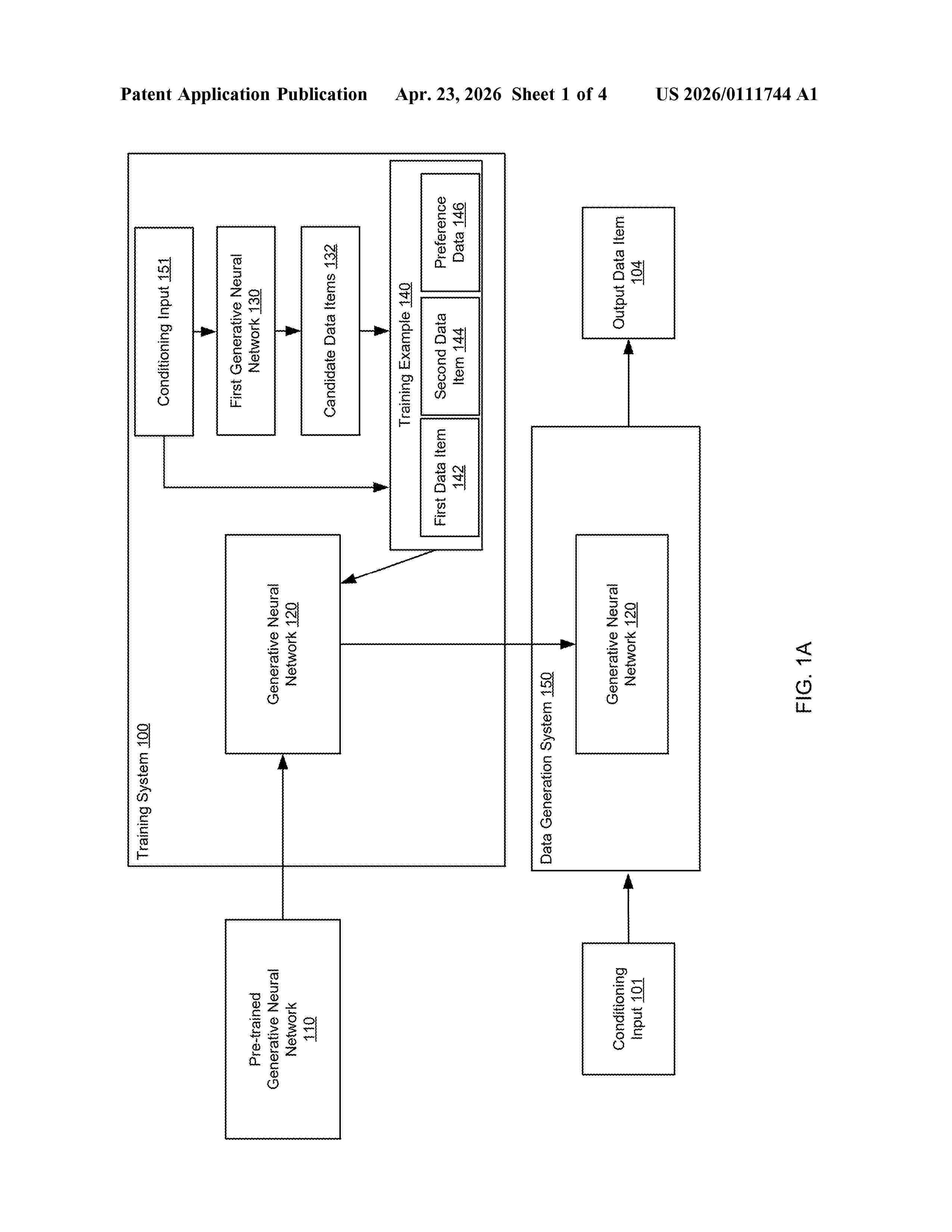
Resumen de: US20260111744A1
0000 Methods, systems, and apparatus, including computer programs encoded on computer storage media, for fine-tuning a generative neural network. For example, the system can fine-tune the generative neural network to more effectively generate data items that have a target property.
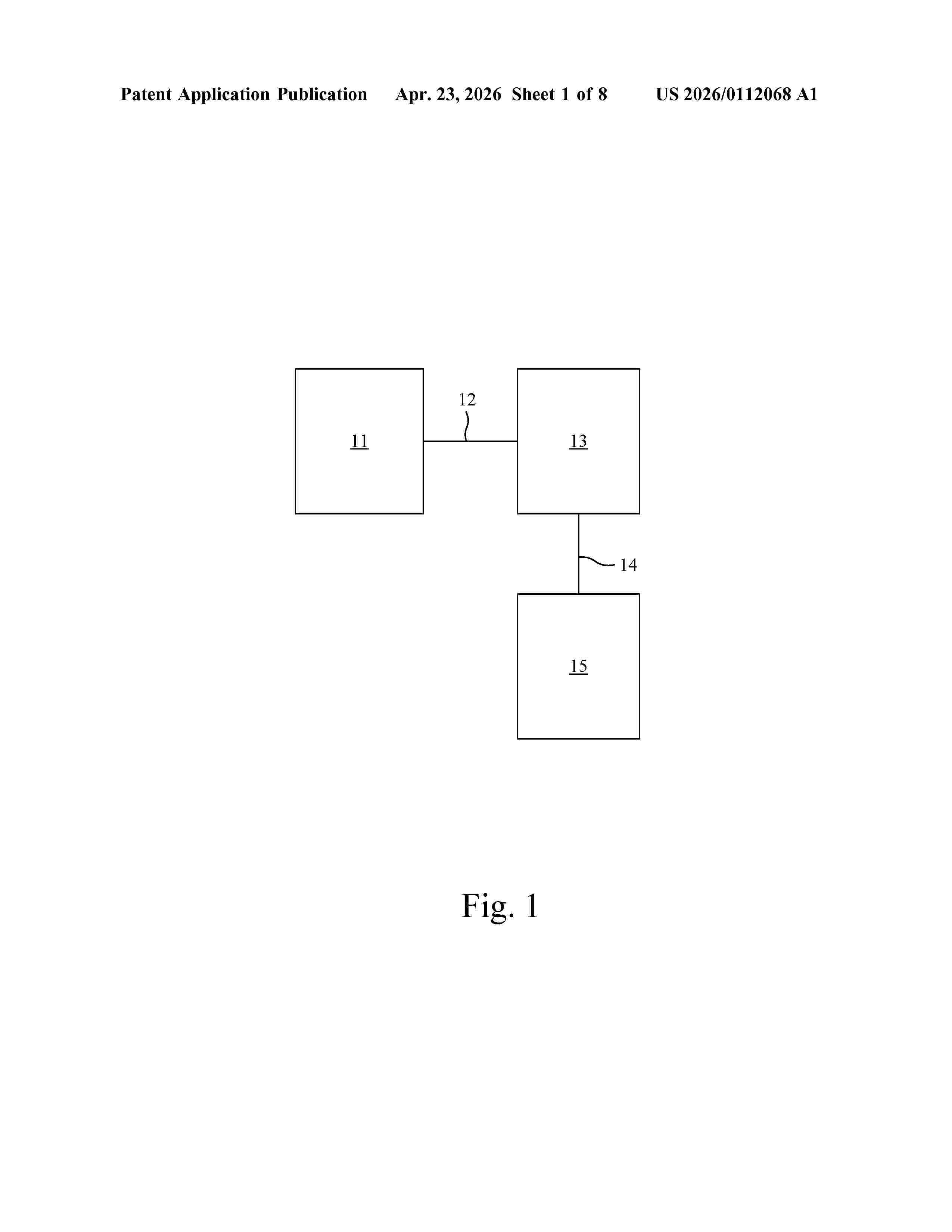
Resumen de: US20260112068A1
A deep neural network based video compression system in which gradients of entropies with respect to side and main latents are used on decoding side to improve compression efficiency.
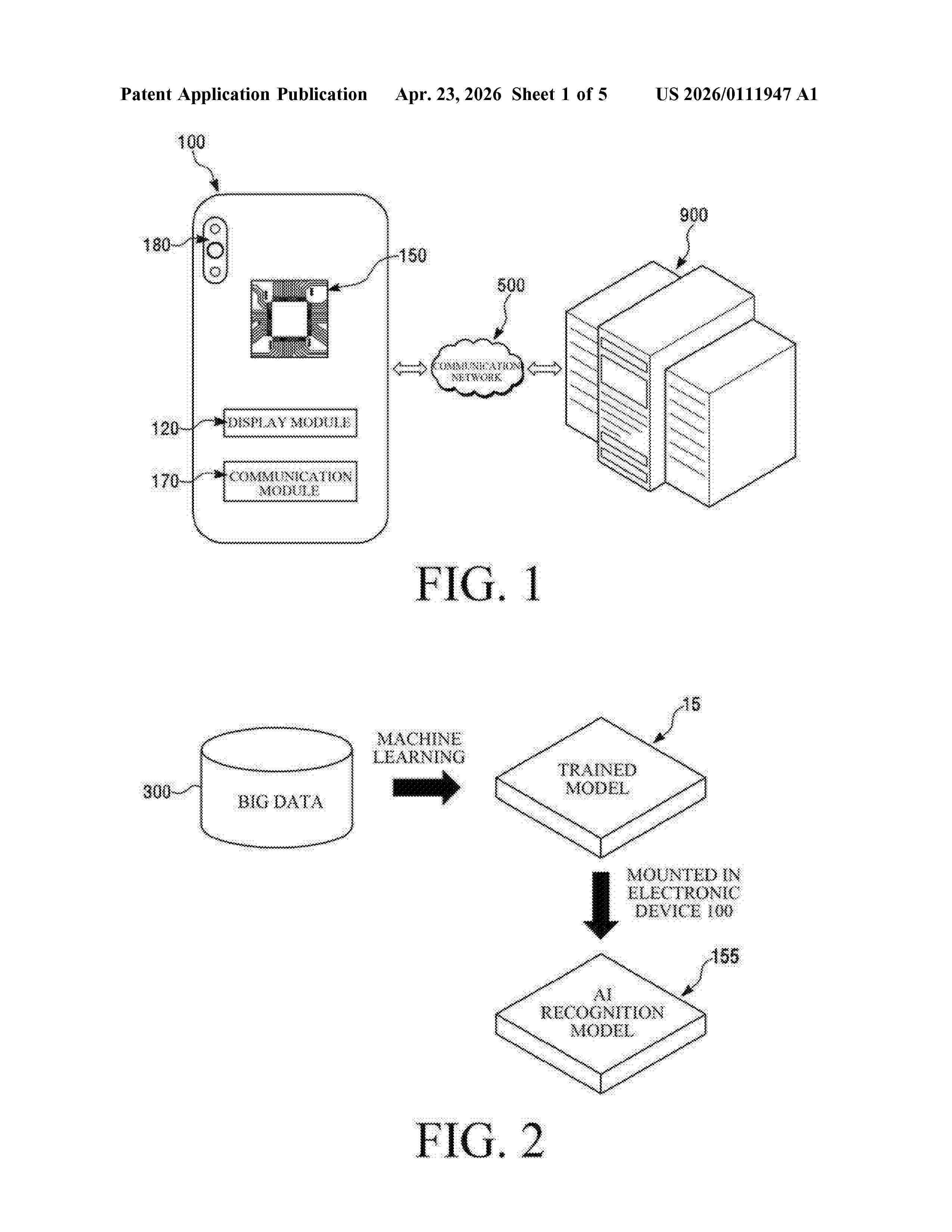
Resumen de: US20260111947A1
0000 A method for providing shopping information using an electronic device is disclosed. The method includes inputting a product image acquired via a camera module into an AI recognition model including an artificial neural network to obtain recognition results, and determining whether product information is recognized from the product image. When the AI recognition model fails to recognize the product information, a user input interface is displayed together with recognition failure information on a display module. User input data is received through the user input interface, and the product information is determined based on the received user input data. A query based on the product information is transmitted to a server via a communication module, and shopping information corresponding to the transmitted query is received from the server and displayed on the display module.
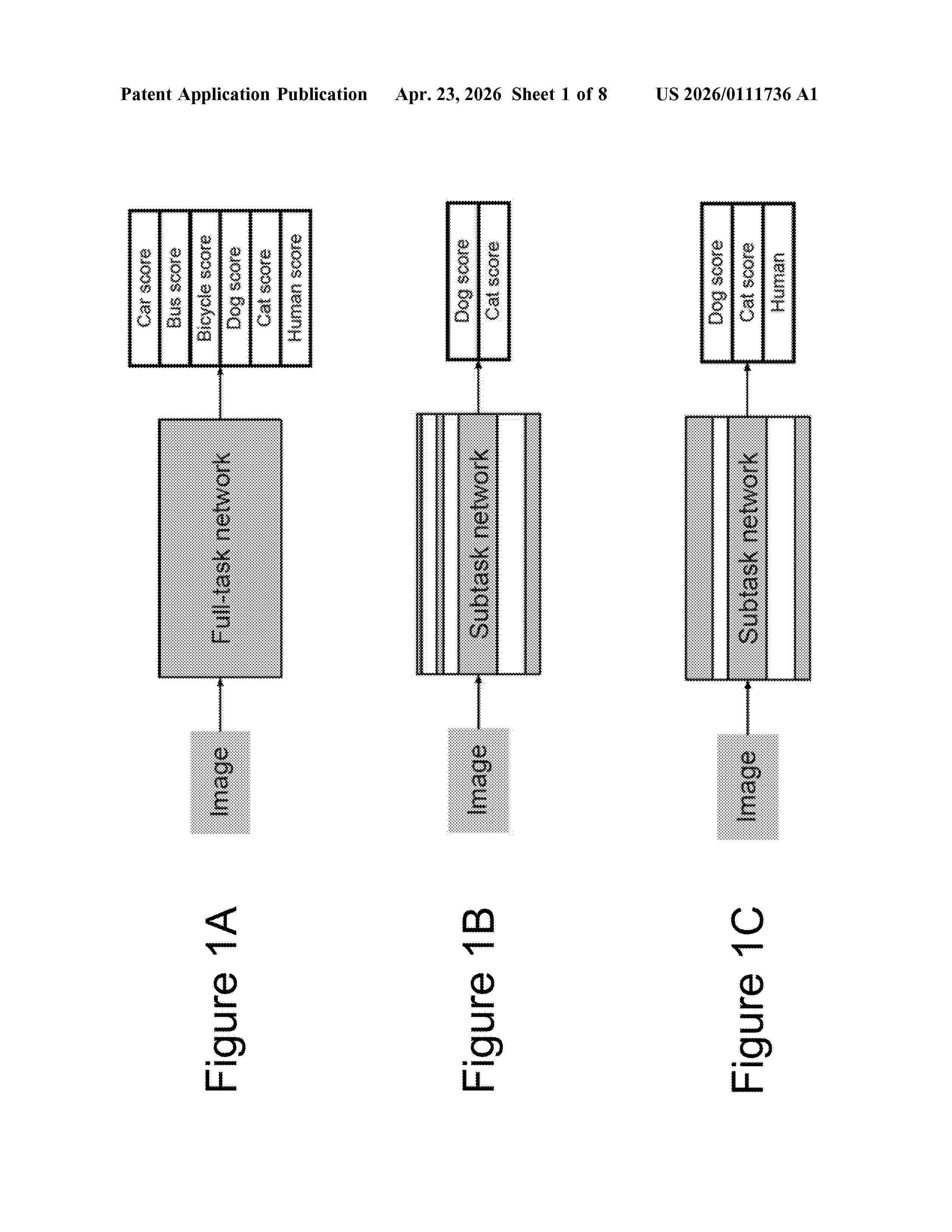
Resumen de: US20260111736A1
0000 At training time, a base neural network can be trained to perform each of a plurality of basis subtasks included in a total set of basis subtasks (e.g., individually or some combination thereof). Next, a description of a desired combined subtask can be obtained. Based on the description of the combined subtask, a mask generator can produce a pruning mask which is used to prune the base neural network into a smaller combined-subtask-specific network that performs only the two or more basis subtasks included in the combined subtask.
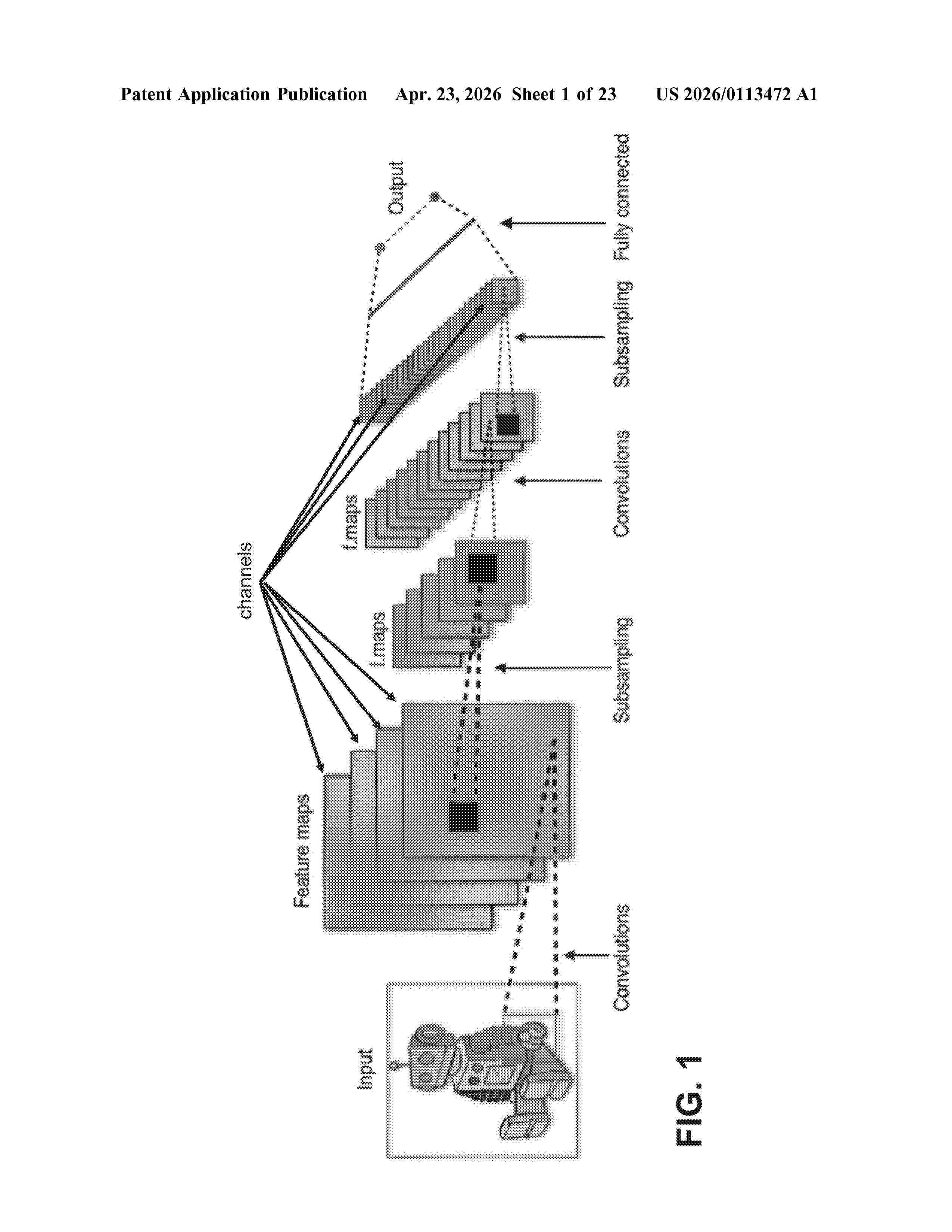
Resumen de: US20260113472A1
The present disclosure relates to an efficient signaling of feature map information for a system employing a neural network. In particular, at the decoder side, a presence indicator is obtained based on information parsed from a bitstream. Based on the value of the obtained presence indicator, further data related to a feature map region are parsed or the parsing is bypassed. The presence indicator may be, for instance a region presence indicator indicating whether feature map data is included in the bitstream, or may be a side information presence indicator indicating whether a side information related to the feature map data is included in the bitstream. Similarly, an encoding method, as well as encoding and decoding devices are provided. Accordingly, the feature map data may be processed more efficiently, including reduction of decoding complexity as well as reduction of the amount of transmitted data by applying the bypassing.
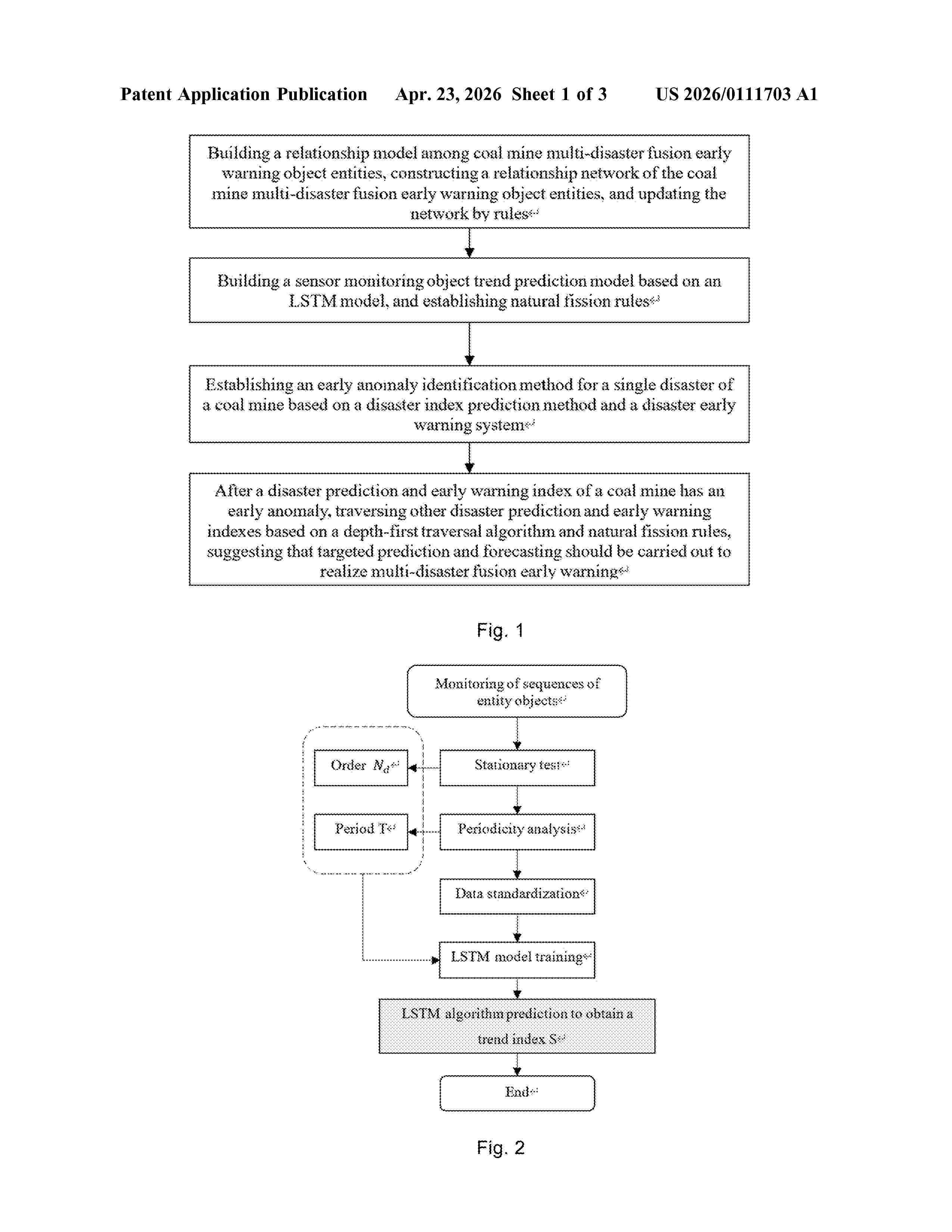
Resumen de: US20260111703A1
The present invention discloses a coal mine multi-disaster fusion early warning method and system, applicable in coal mine safety disaster analysis. First, it builds a model and relationship network among multi-disaster early warning entities, updating the network by specific rules. A trend prediction model using an LSTM artificial neural network is then developed for monitoring object trends, along with natural fission analysis rules. Next, a method for identifying anomalies in single disaster events is established through a disaster index prediction and early warning system. Upon detecting an anomaly in an early warning index, other disaster indexes are assessed using a depth-first traversal algorithm and natural fission rules, facilitating targeted forecasting. This invention builds a predictive relationship chain among early warning indexes through correlation analysis, providing advantages in multi-dimensional analysis and advanced trend prediction.
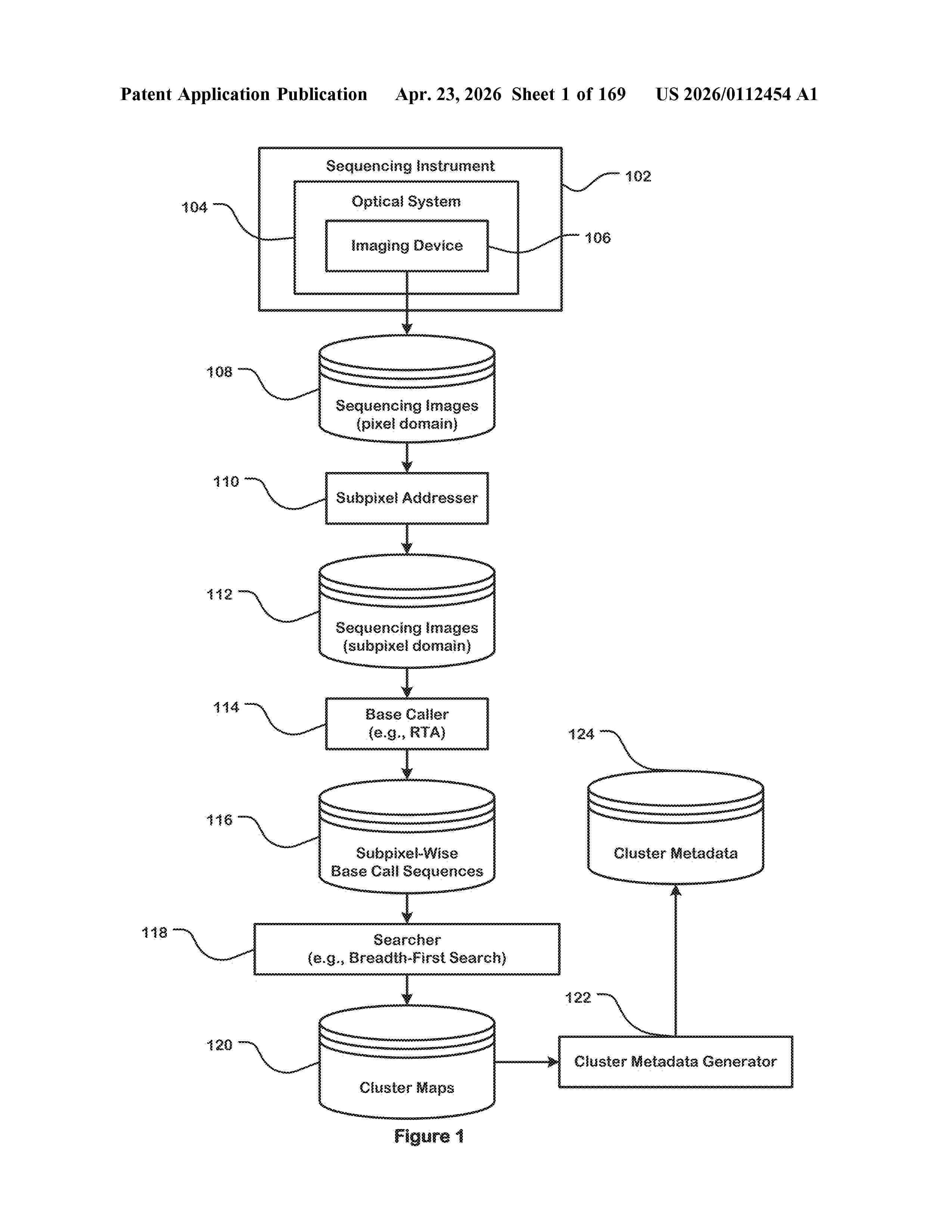
Resumen de: US20260112454A1
A system, a method and a non-transitory computer readable storage medium for base calling are described. The base calling method includes processing through a neural network first image data comprising images of clusters and their surrounding background captured by a sequencing system for one or more sequencing cycles of a sequencing run. The base calling method further includes producing a base call for one or more of the clusters of the one or more sequencing cycles of the sequencing run.
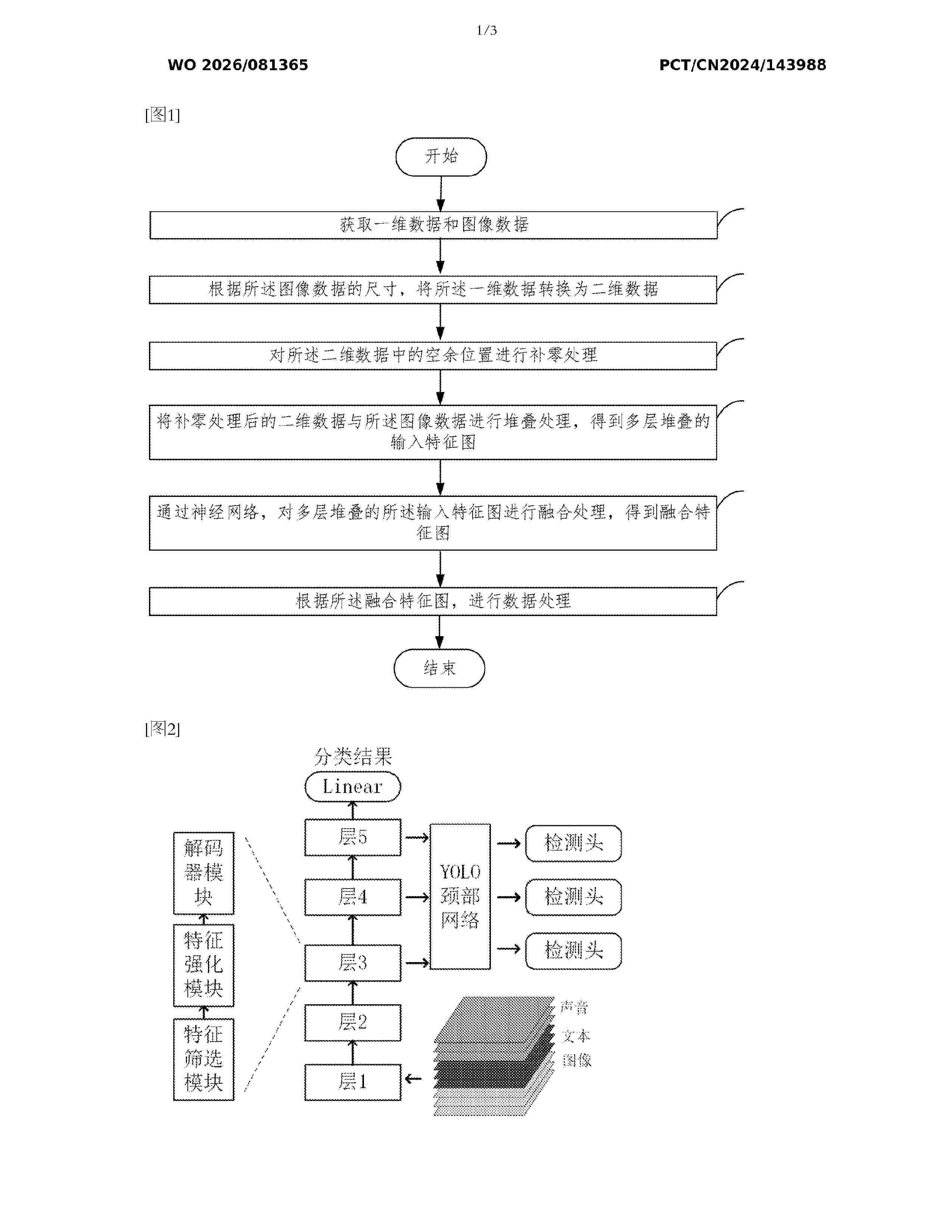
Resumen de: WO2026081365A1
The present application belongs to the technical field of data processing. Provided are a data processing method and apparatus based on multi-modal fusion. The method comprises: acquiring one-dimensional data and image data; on the basis of the size of the image data, converting the one-dimensional data into two-dimensional data; performing zero padding processing on vacant positions in the two-dimensional data; performing stacking processing on the two-dimensional data which has been subjected to the zero padding processing, and the image data, so as to obtain a multi-layer stacked input feature map; by means of a neural network, performing fusion processing on the multi-layer stacked input feature map, so as to obtain a fused feature map; and on the basis of the fused feature map, performing data processing. In the present invention, one-dimensional data is converted into two-dimensional data which is of the same size as image data, and the two-dimensional data is stacked with the image data, such that data formats of different modalities can be unified, and the data can be processed within the same feature space, thereby greatly simplifying an alignment process between heterogeneous data.
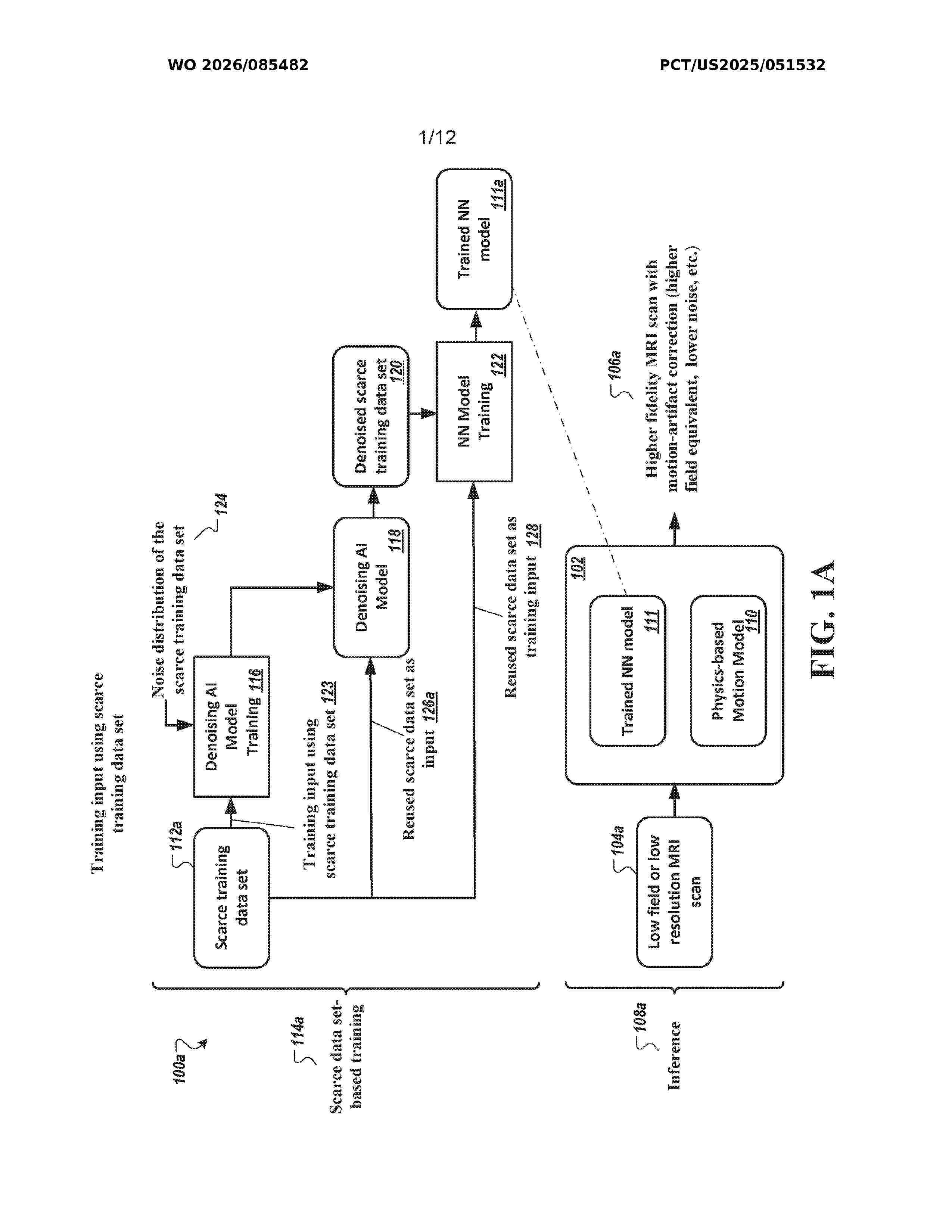
Resumen de: WO2026085482A1
An exemplary AI system and method are disclosed for reconstructing high-fidelity motion-corrected MRI scans from low-field, motion-corrupted MRI scans (e.g., neonatal MRI data) using a neural network (NN) model in combination with a physics-based motion model. The exemplary AI system and method can enhance image quality and remove motion artifacts which can allow for scans to be performed with significantly reduced scan time, a particular benefit for neonatal subjects as well as all patients when employing low-field MRI.
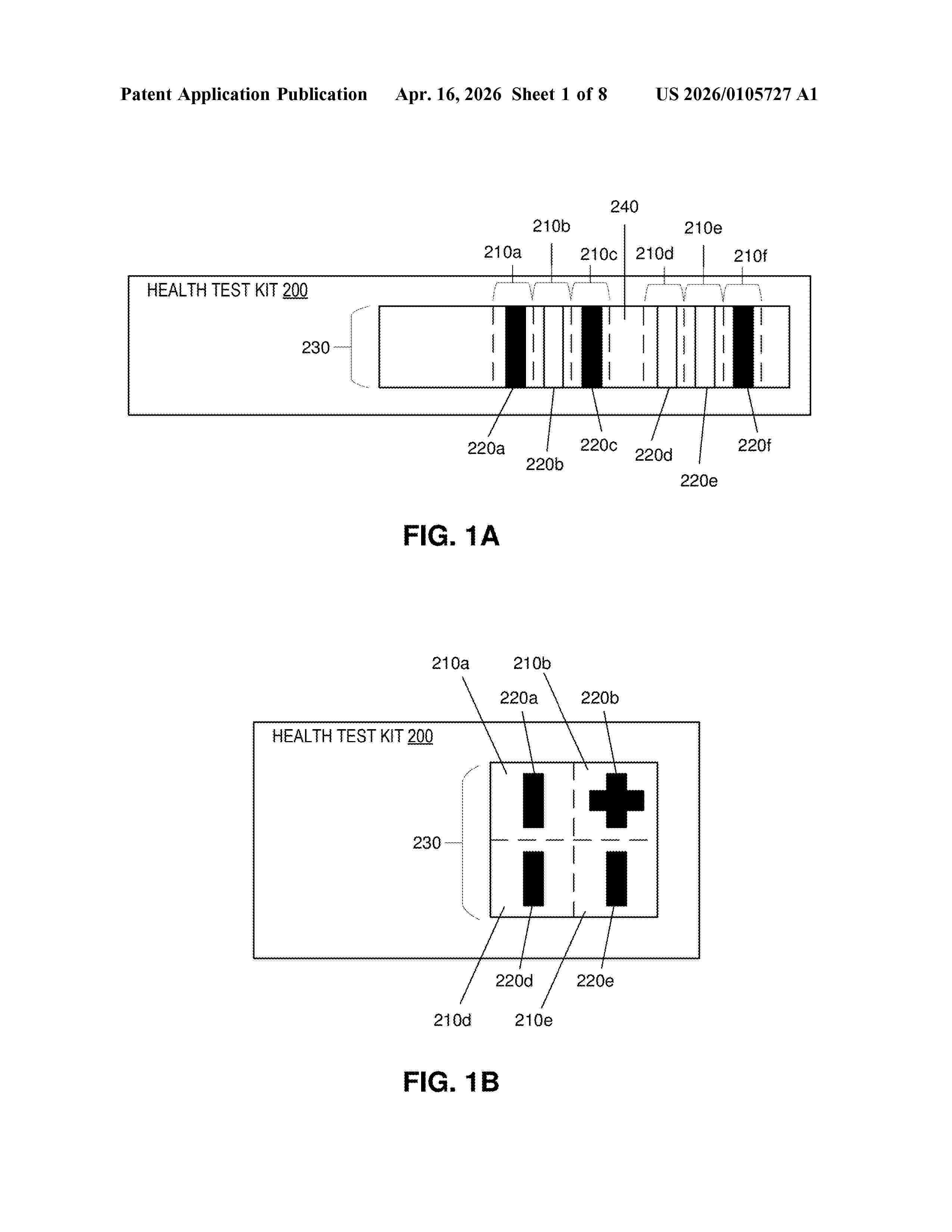
Resumen de: US20260105727A1
To train a computer vision model to classify health test kit results, a computing system obtains a plurality of training images. Each training image depicts a plurality of health test results in respective segments of a test membrane of a health test kit. The computing system obtains, for each training image, labeling indicating the health test results depicted by the training image. The computing system trains a plurality of local Convolutional Neural Networks (CNNs) of the computer vision model in parallel. Each of the local CNNs is trained to predict the health test result depicted in a respective one of the segments based on local features extracted by the local CNN from the respective one of the segments of each training image and global features extracted by a global CNN of the computer vision model from the test membrane of each training image.
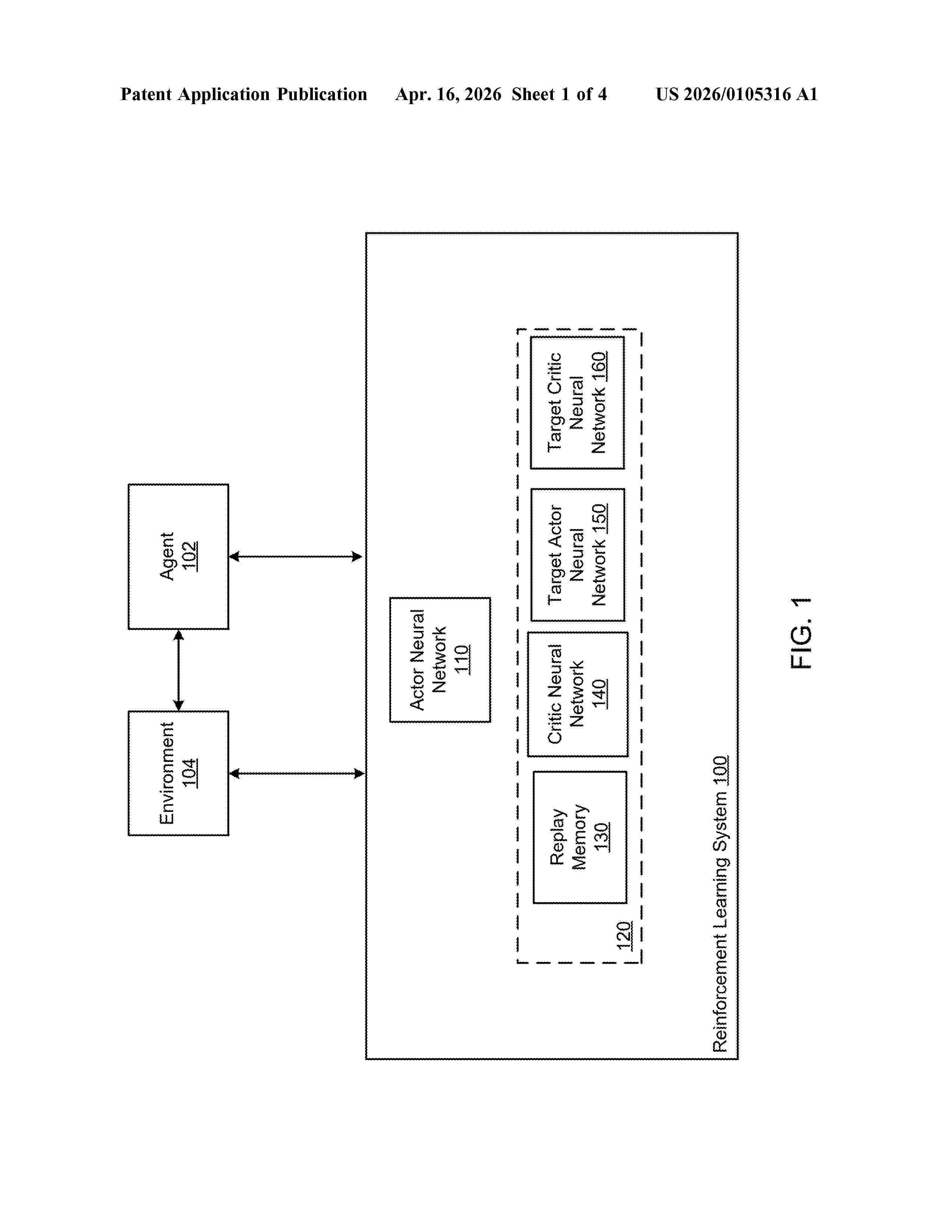
Resumen de: US20260105316A1
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for training an actor neural network used to select actions to be performed by an agent interacting with an environment. One of the methods includes obtaining a minibatch of experience tuples; and updating current values of the parameters of the actor neural network, comprising: for each experience tuple in the minibatch: processing the training observation and the training action in the experience tuple using a critic neural network to determine a neural network output for the experience tuple, and determining a target neural network output for the experience tuple; updating current values of the parameters of the critic neural network using errors between the target neural network outputs and the neural network outputs; and updating the current values of the parameters of the actor neural network using the critic neural network.
Nº publicación: US20260105989A1 16/04/2026
Solicitante:
GRAIL INC [US]
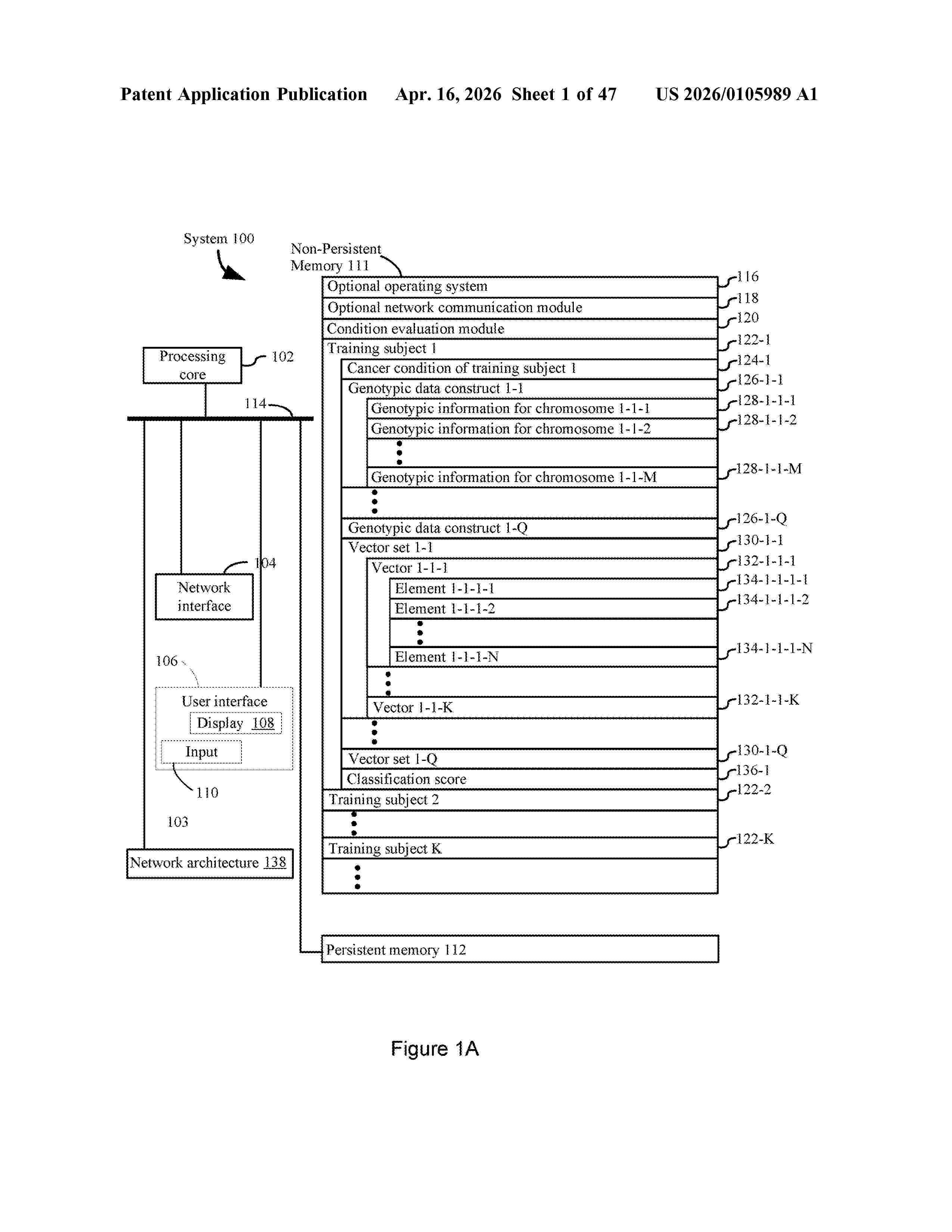
Resumen de: US20260105989A1
Classification of cancer condition, in a plurality of different cancer conditions, for a species, is provided in which, for each training subject in a plurality of training subjects, there is obtained a cancer condition and a genotypic data construct including genotypic information for the respective training subject. Genotypic constructs are formatted into corresponding vector sets comprising one or more vectors. Vector sets are provided to a network architecture including a convolutional neural network path comprising at least a first convolutional layer associated with a first filter that comprise a first set of filter weights and a scorer. Scores, corresponding to the input of vector sets into the network architecture, are obtained from the scorer. Comparison of respective scores to the corresponding cancer condition of the corresponding training subjects is used to adjust the filter weights thereby training the network architecture to classify cancer condition.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica