Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 56
resultados
56
resultados
 Última actualización
30/04/2026 [07:41:00]
Última actualización
30/04/2026 [07:41:00]


 Resultados 25 a 50 de 56
Resultados 25 a 50 de 56

Resumen de: US20260099963A1
Apparatuses, systems, and techniques are presented to generate or manipulate digital images. In at least one embodiment, a network is trained to generate modified images including user-selected features.

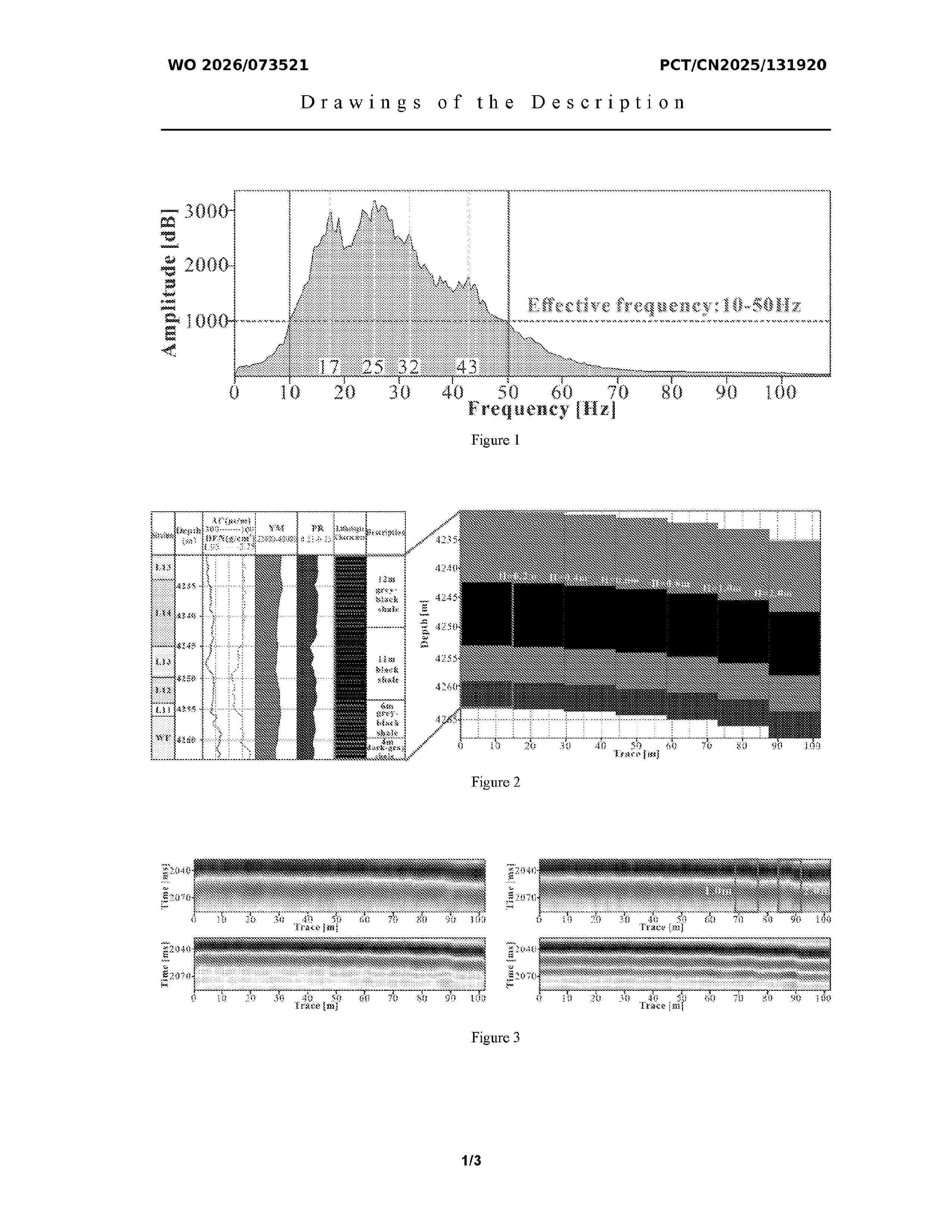
Resumen de: WO2026073521A1
A shale fracture seismic identification method based on a 3D U-Net convolutional neural network combined with ant tracking is disclosed. The method establishes a geological model of shale fractures using single-well data and performs seismic forward modeling to determine the advantageous frequency band for fracture identification. Spectral-peak decomposition is applied to obtain the advantageous frequency-band data volume, which is processed using a 3D U-Net convolutional neural network and ant-tracking computation to generate a 3D U-Net Ant Tracking volume. The results are verified using microseismic data, and along-layer attributes of the 3D U-Net Ant Tracking volume are extracted to determine the regional planar distribution characteristics of shale fractures. The method effectively reduces exploration costs by combining single-well and seismic data, significantly improves seismic resolution through integrated application of seismic forward modeling, spectral-peak decomposition, and advantageous frequency-band data computation, and expands the range of fracture identification by extracting along-layer slices from the data volume.
Resumen de: US20260100058A1
Disclosed herein are systems, methods, and devices for detecting traffic lane violations. In one embodiment, a method for detecting a potential traffic violation is disclosed comprising bounding a vehicle detected from one or more video frames of a video in a vehicle bounding box. The vehicle can be detected and bounded using a first convolutional neural network. The method can also comprise bounding, using the one or more processors of the edge device, a plurality of lanes of a roadway detected from the one or more video frames in a plurality of polygons. The plurality of lanes can be detected and bounded using multiple heads of a multi-headed second convolutional neural network. The method can further comprise detecting a potential traffic violation based in part on an overlap of at least part of the vehicle bounding box and at least part of one of the polygons.
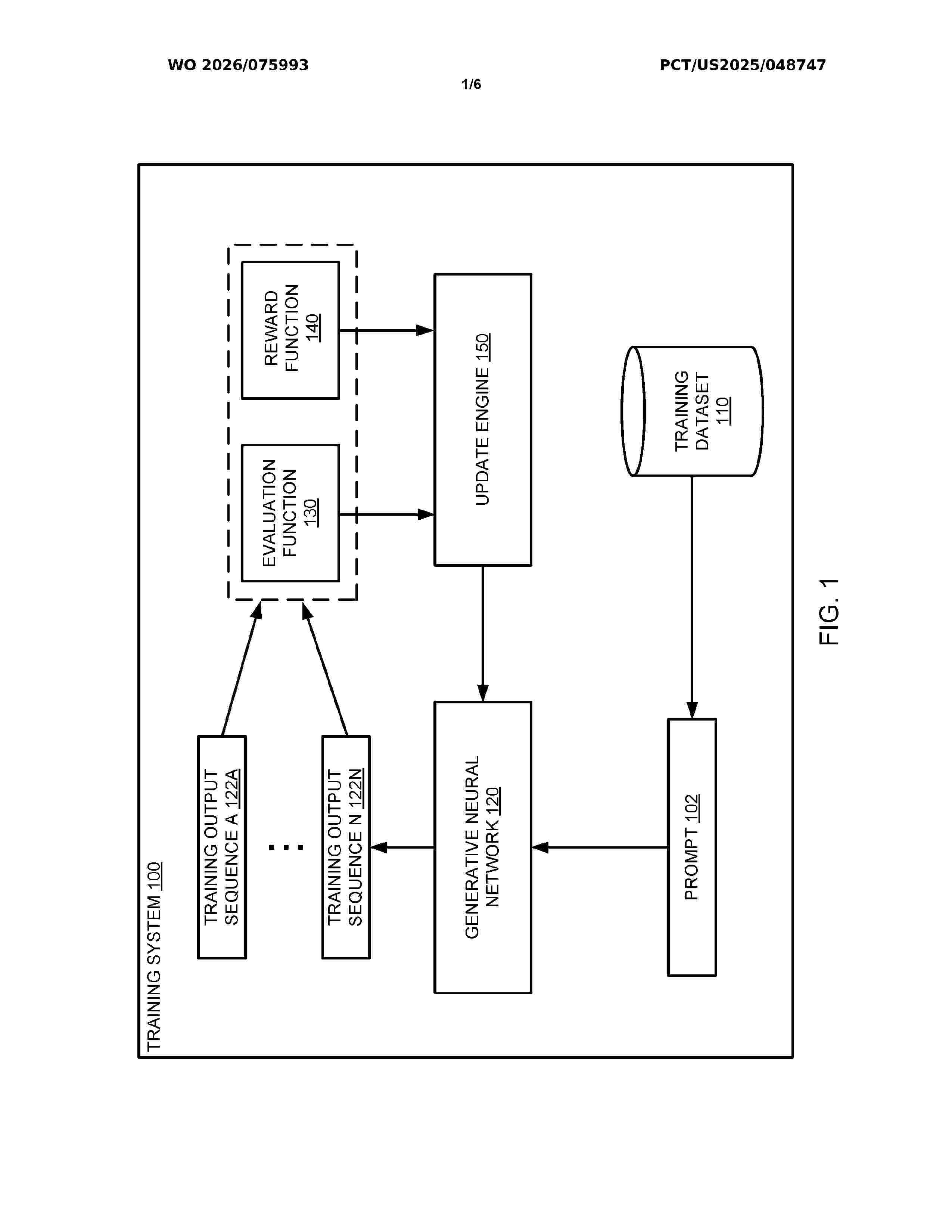
Resumen de: WO2026075993A1
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for training a generative neural network using an inference-aware fine-tuning framework to mitigate the difference between how the generative neural network has been trained and how the generative neural network will be used at inference time.
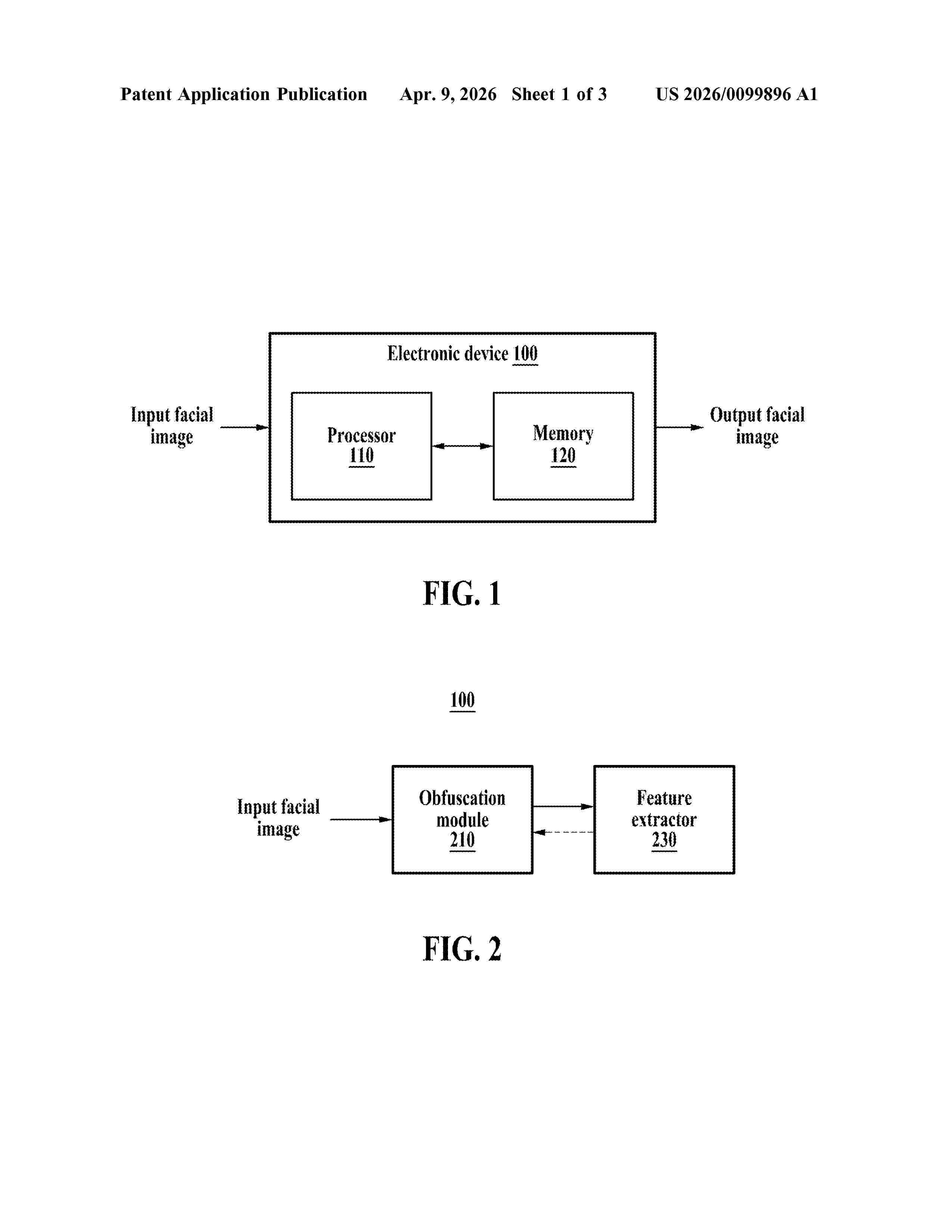
Resumen de: US20260099896A1
0000 A method of training a neural network configured to obfuscate a facial image and an electronic device for performing the method are provided. The method includes obtaining, based on an input facial image, an output facial image in which the input facial image is obfuscated, extracting, based on the input facial image, a feature of the input facial image for reconstructing identification information included in the input facial image from the output facial image, extracting, based on the output facial image, a feature of the output facial image corresponding to the feature of the input facial image, and training the neural network based on a difference between the feature of the input facial image and the feature of the output facial image.
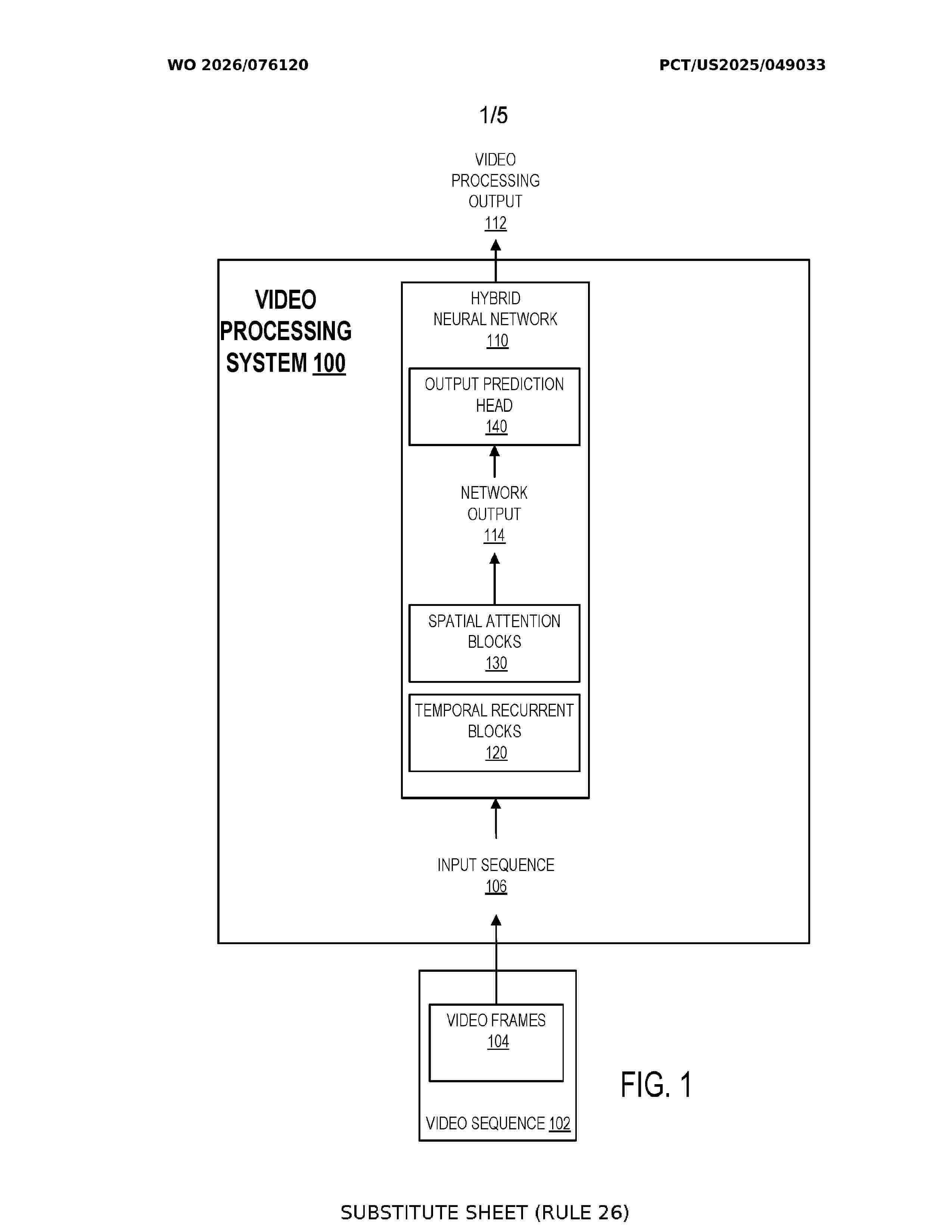
Resumen de: WO2026076120A1
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for processing videos using neural networks. In particular, the neural network has a hybrid architecture that includes both recurrent and self-attention layers.
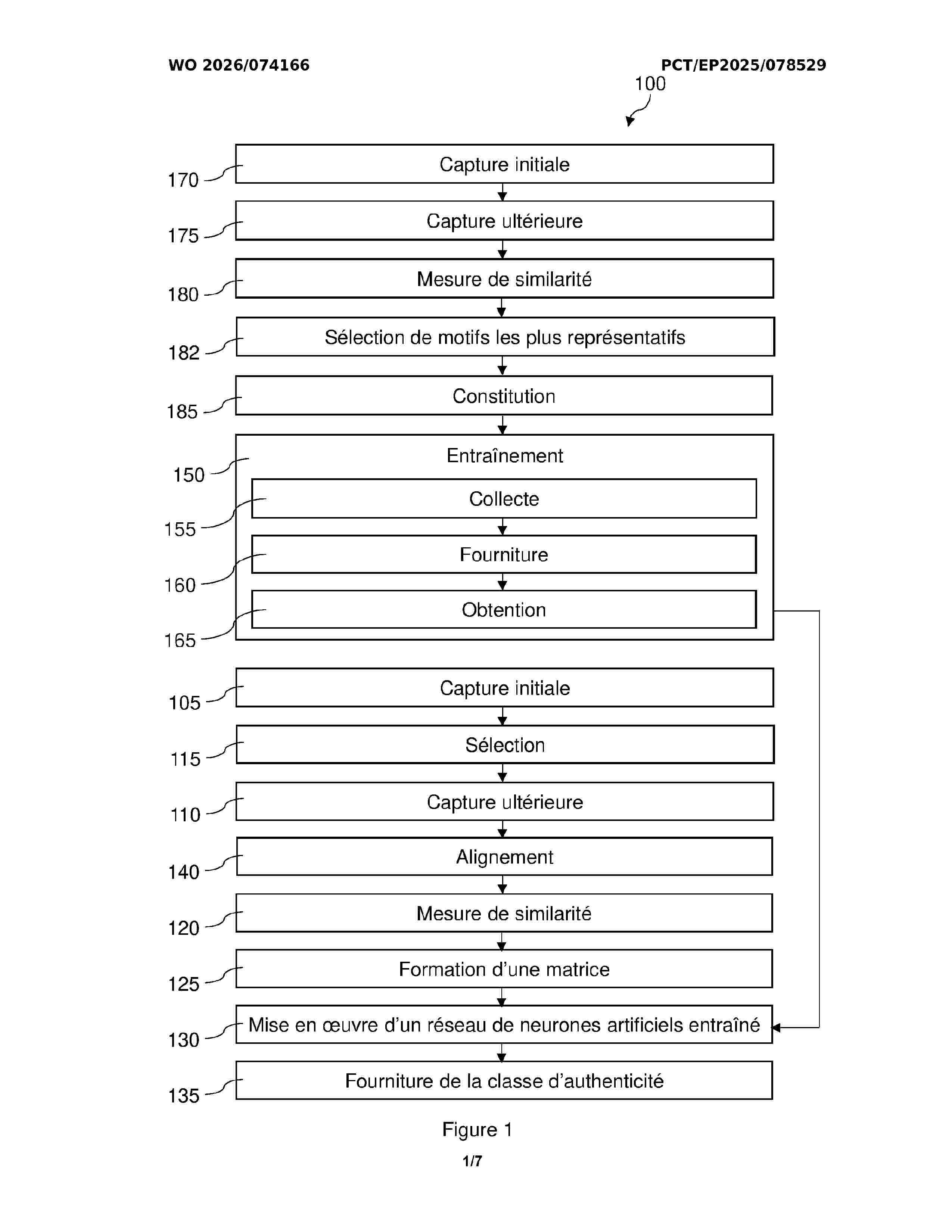
Resumen de: WO2026074166A1
The invention relates to a method for authenticating a product carrying a marking defined by a geometric distribution of a plurality of groups of binary modules, which method consists in capturing an initial image of the marking of the product, selecting minutiae from among its binary modules, and capturing a subsequent image on a candidate product. For each minutia, a measure of the similarity between the two images is computed. These similarity measures are organised in a matrix representing the position and the structure of the minutiae. An artificial neural network analyses this matrix to provide the authenticity class of the product.
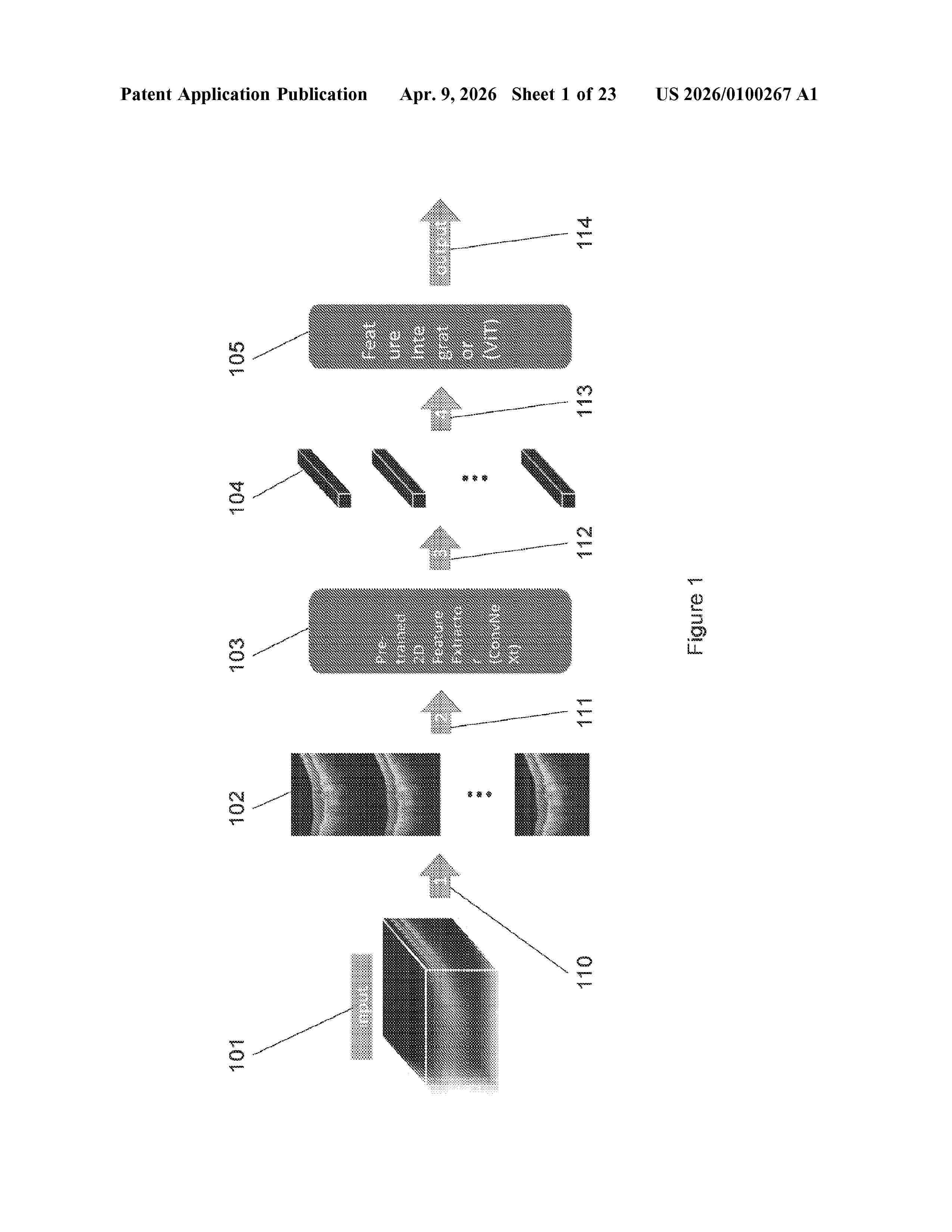
Resumen de: US20260100267A1
0000 Deep learning methods and systems for detecting biomarkers within volumetric biomedical imaging dataset using such deep learning methods and systems are provided. Embodiments predict the clinically useful biomarkers in optical coherent tomography images, ultrasound images, magnetic resonance imaging images, and computed tomography images using deep neural networks.
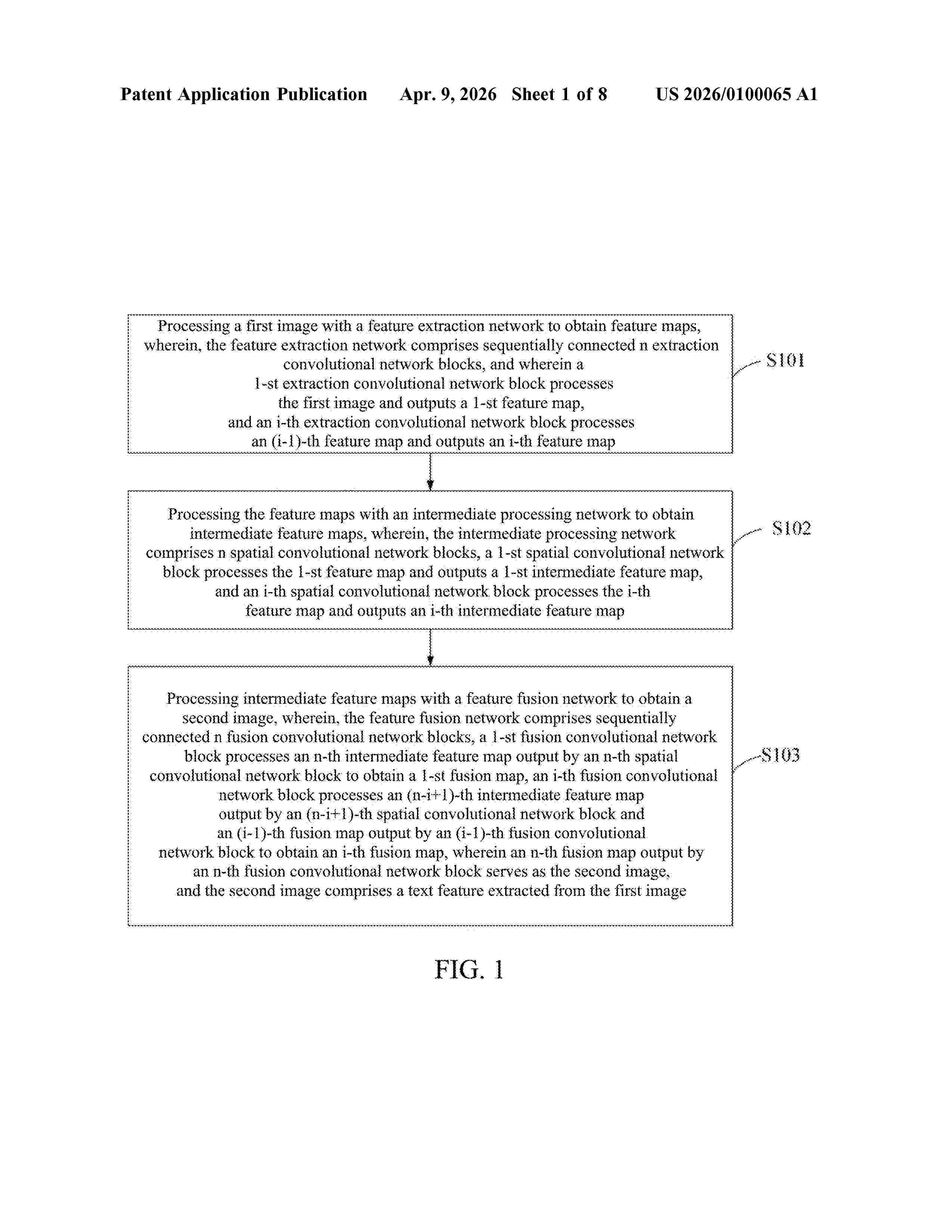
Resumen de: US20260100065A1
0000 The present disclosure provides an image style conversion method. The image style conversion method includes: acquiring a first image, wherein the first image includes text information; performing image processing on the first image by a text matting neural network model to obtain a text mask; performing style conversion on the text mask based on a preset application scenario to obtain a converted text mask; and performing image fusion on the converted text mask and a background image of the preset application scenario to obtain a converted image after image style conversion.
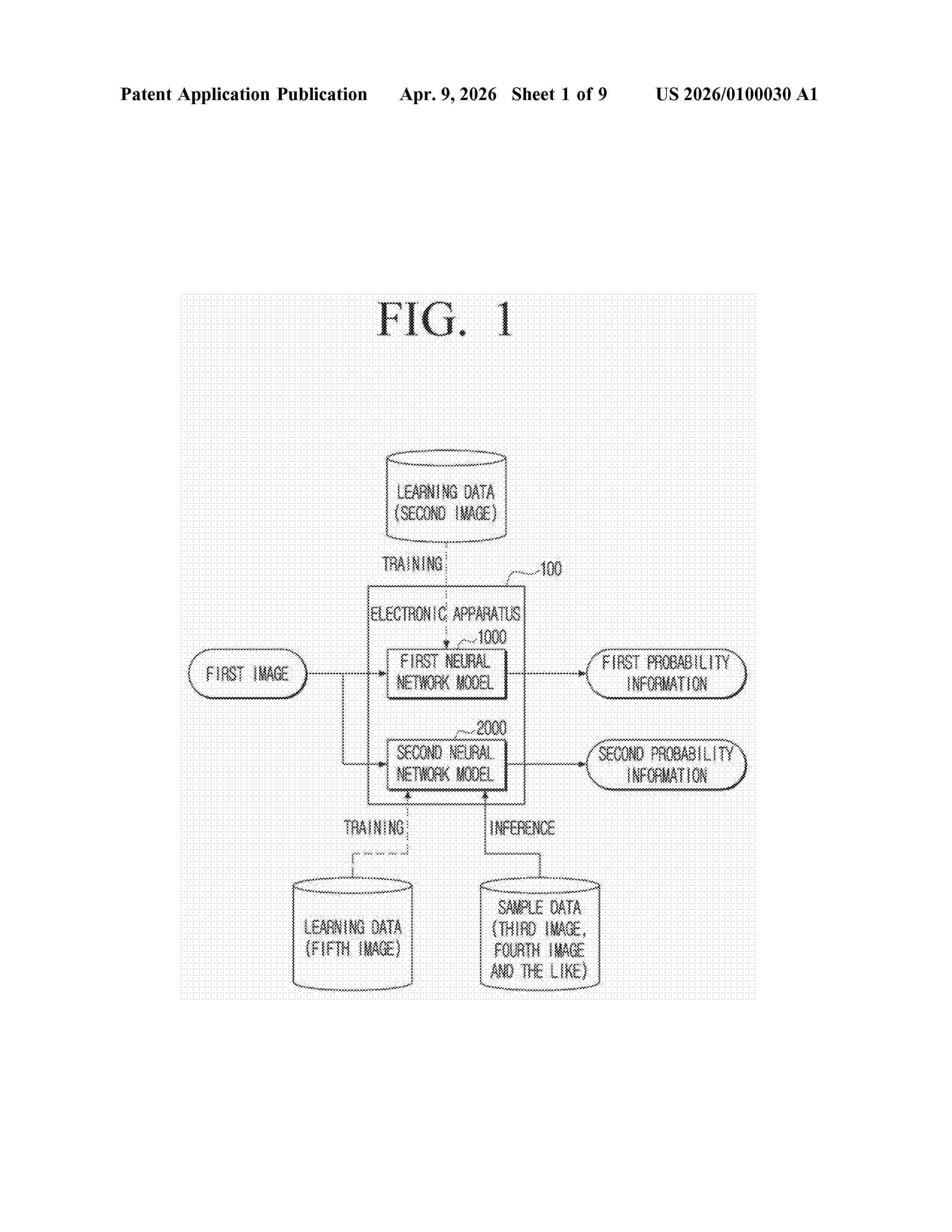
Resumen de: US20260100030A1
Provided is an electronic apparatus including memory configured to store at least one instruction, and a processor configured to execute the at least one instruction to obtain a first image including an object, input the first image to a first neural network model that is configured to be trained by using a plurality of second images in relation to a plurality of predefined types, obtain first probability information including a first probability of the object corresponding to a first type among the plurality of types and a second probability of the object corresponding to a second type among the plurality of types, obtain second probability information, through a second neural network model, indicating a type of the object included in the first image, by using a plurality of third images corresponding to the first type and a plurality of fourth images corresponding to the second type based on a difference between the first probability and the second probability being less than a first threshold value and based on a first input, and identify the type of the object based on the second probability information.
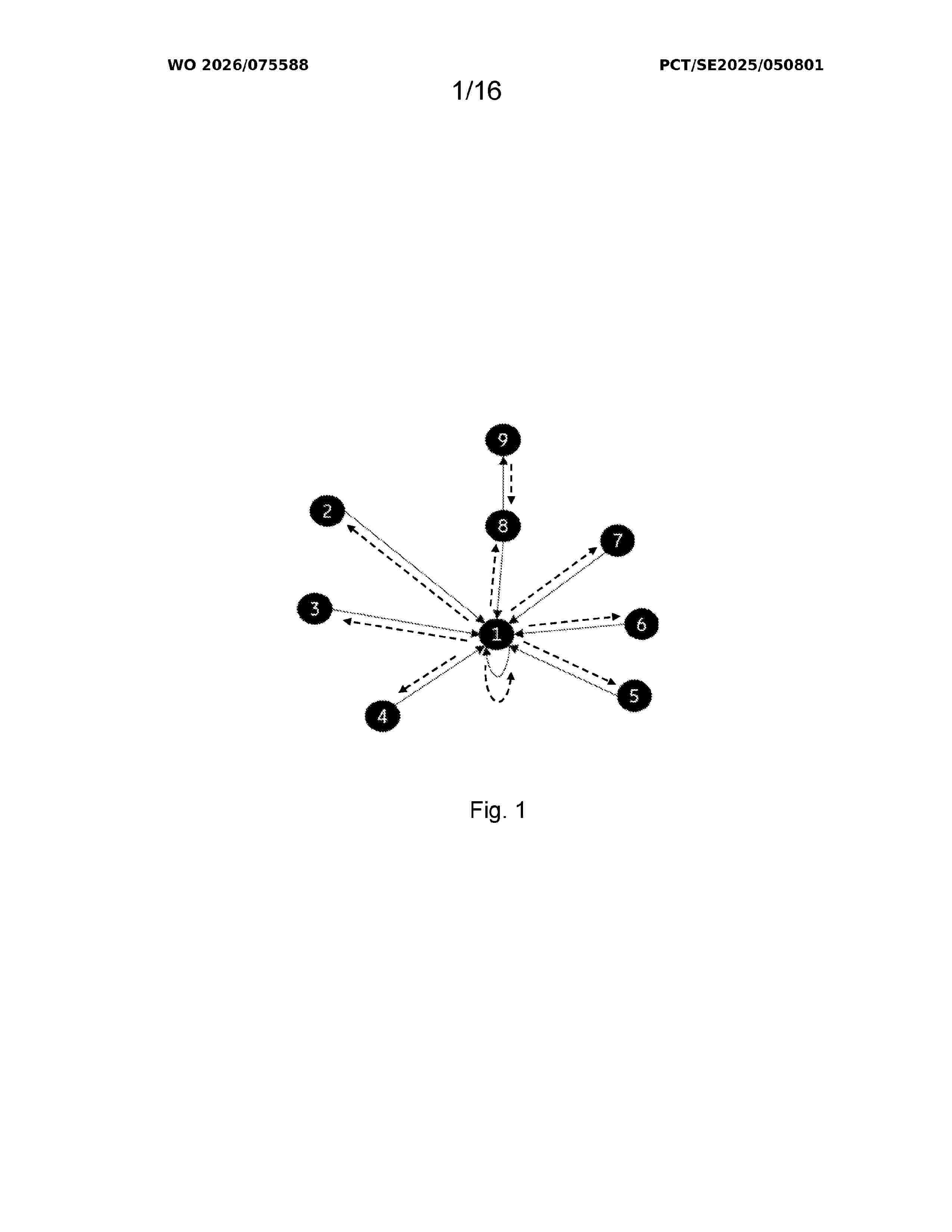
Resumen de: WO2026075588A1
A method (200) is disclosed for generating an explainability output for node level predictions generated by a GNN on an input graph. The method comprises, for individual nodes in the input graph, for each incoming neighbour node of the node, creating an ordered group comprising the node and the incoming neighbour node (210), and then combining the ordered groups into a plurality of batches, each batch comprising an ordered group (220). The method further comprises, for individual batches, and for individual nodes in the batch, identifying edges in the GNN computation graph of the node that connect to nodes outside of the batch, and detaching the identified edges in the backward pass direction (230), and using the GNN to generate, in parallel, node level predictions for the nodes in the batch by performing a forward pass through the GNN computation graphs of the nodes in the batch (240). The method further composites using a gradient based explainability method to generate, in parallel, importance scores of incoming neighbour nodes for the nodes in the batch by performing a backward pass through the GNN computation graphs of the nodes in the batch (250). The method further comprises, for individual nodes in the input graph, assembling the generated importance scores of incoming neighbour nodes into an explainability output for the node prediction generated by the GNN (260).
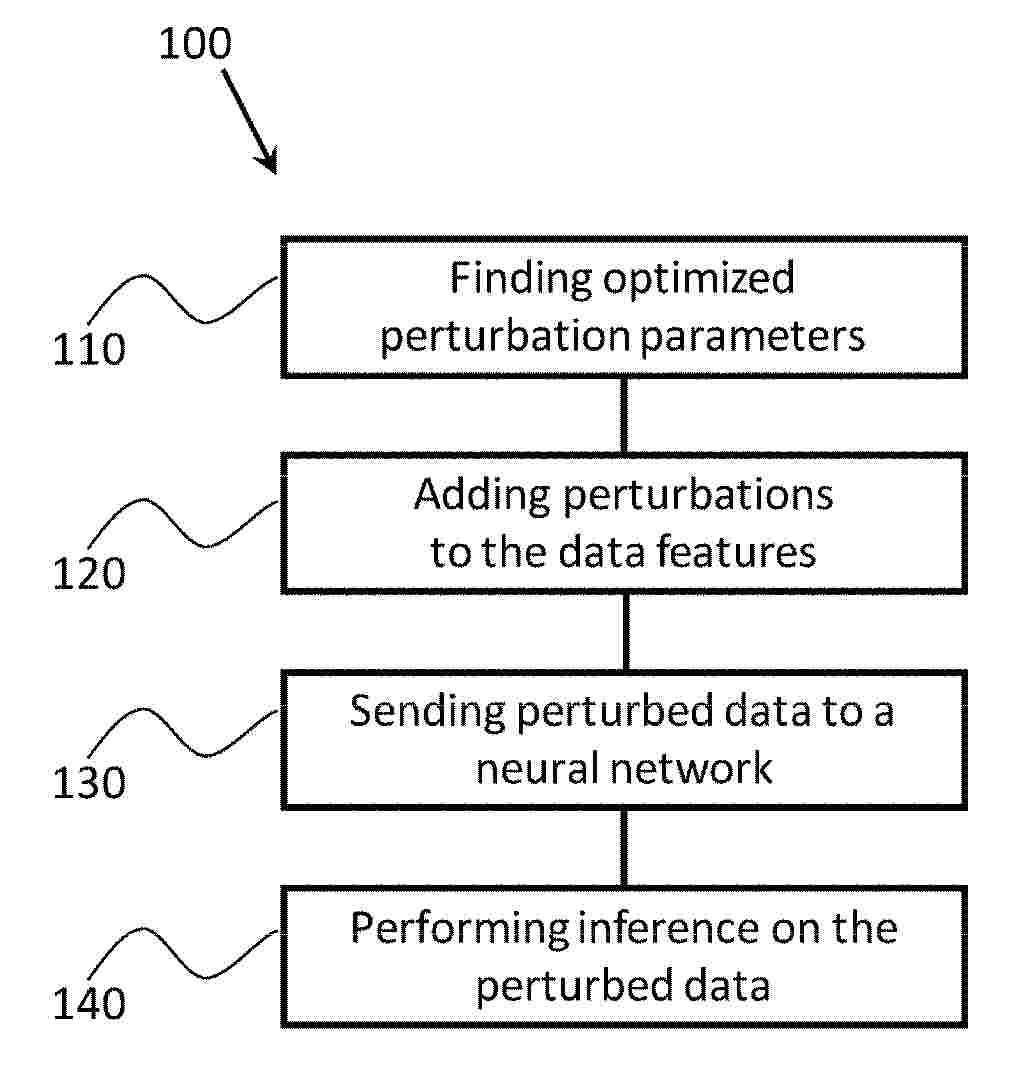
Resumen de: EP4722968A2
Methods and systems that provide data privacy for implementing a neural network-based inference are described. A method includes injecting stochasticity into the data to produce perturbed data, wherein the injected stochasticity satisfies an ε-differential privacy criterion and transmitting the perturbed data to a neural network or to a partition of the neural network for inference.
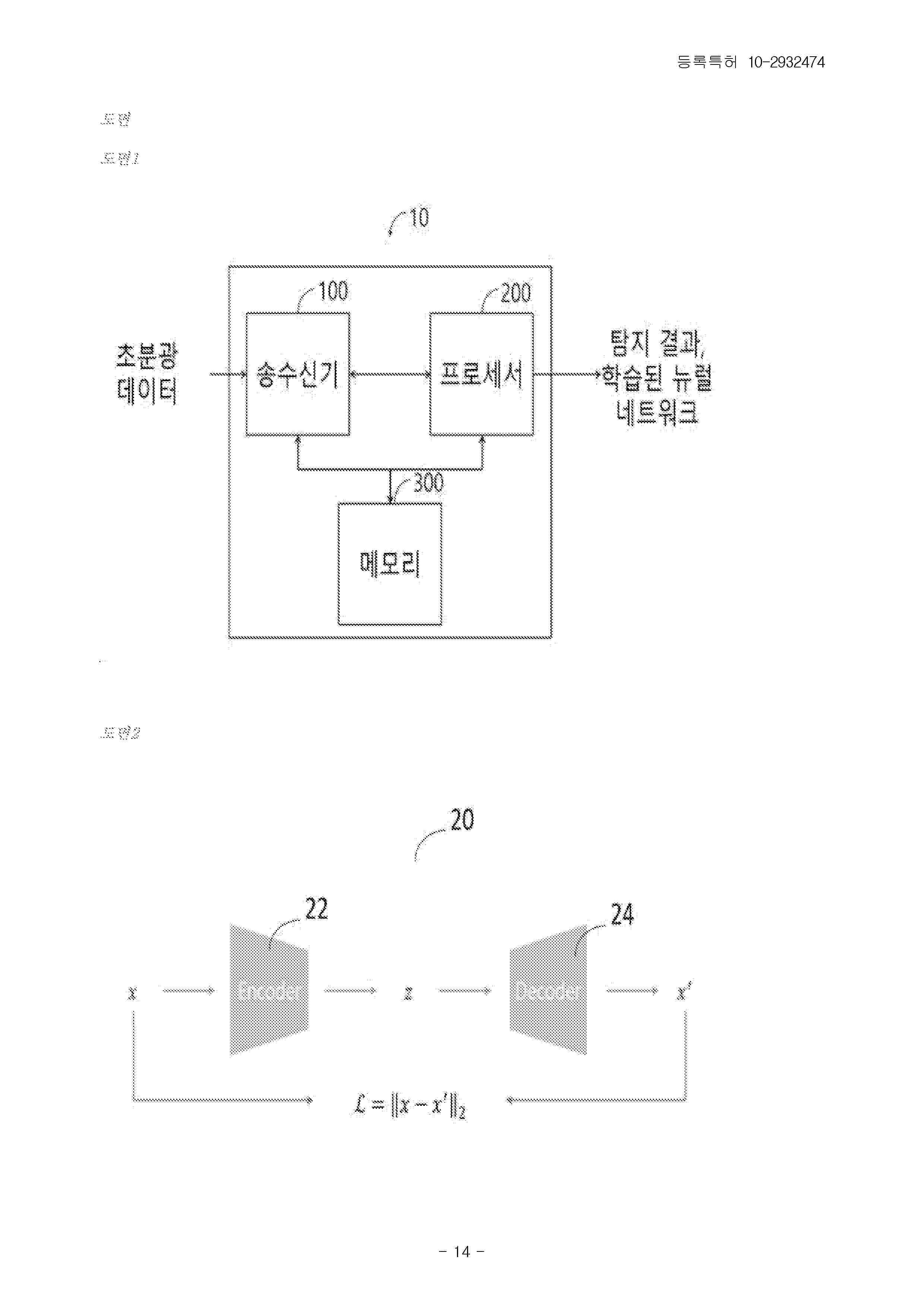
Resumen de: KR102932474B1
Disclosed is an electronic device for detecting an anomaly by using a neural network. According to an embodiment, the electronic device comprises a memory, a transceiver, and a processor. The processor can detect an anomaly in an input image based on a neural network model which is pre-trained to detect an anomaly corresponding to the input image based on deep features which are calculated based on the input image and an average of the deep features. According to the present invention, a high-performance anomaly detection algorithm can be provided.
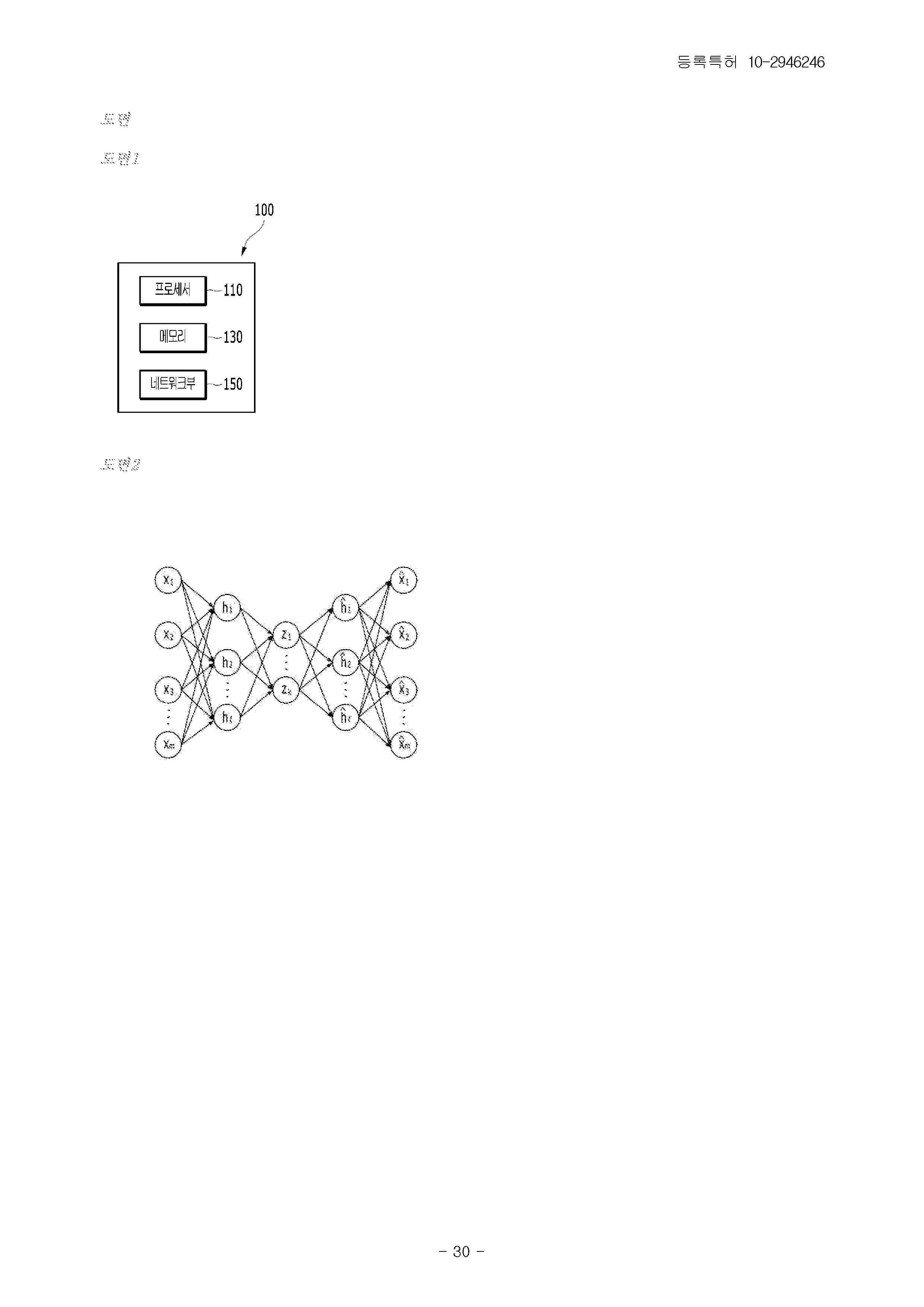
Resumen de: KR102946246B1
According to one embodiment of the present disclosure, disclosed is a method for predicting performance for an image to be evaluated using a neural network model. The method may include the following steps of: determining one or more indices among a plurality of quantified indices related to an image to be evaluated; determining one or more image-related features among a plurality of image-related features of the image to be evaluated; extracting a first latent vector for the image to be evaluated based on the determined one or more indices and the determined one or more image-related features; and predicting performance for the image to be evaluated based on the extracted first latent vector.
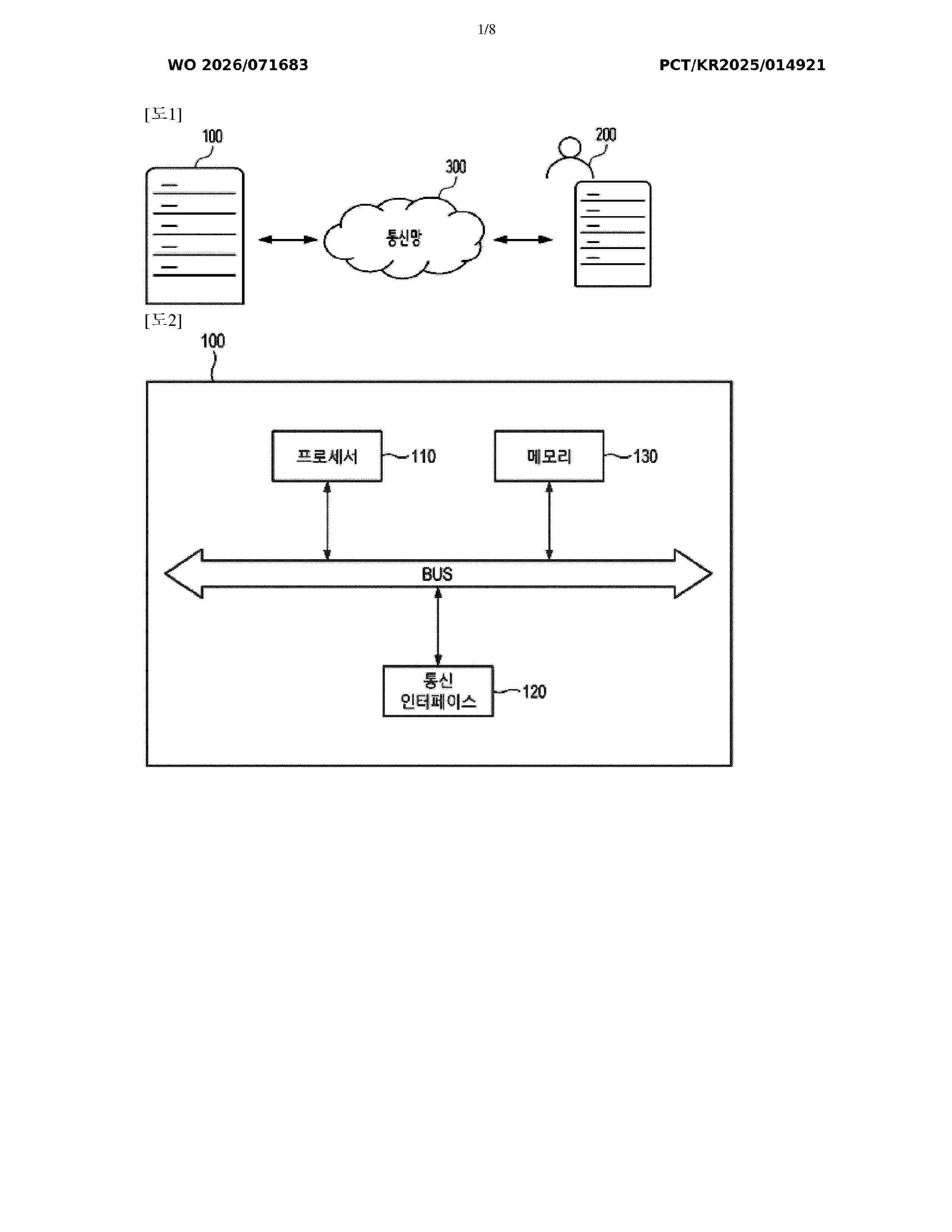
Resumen de: WO2026071683A1
According to an embodiment of the present disclosure, disclosed is a method for predicting the price of cryptocurrency on the basis of an artificial neural network. The method may comprise the steps of: acquiring monitoring reference information from a user terminal; generating a chart image according to the monitoring reference information; generating a pattern prediction result corresponding to the chart image on the basis of an artificial neural network-based pattern prediction model; and transmitting, to the user terminal, notification information generated on the basis of the pattern prediction result.
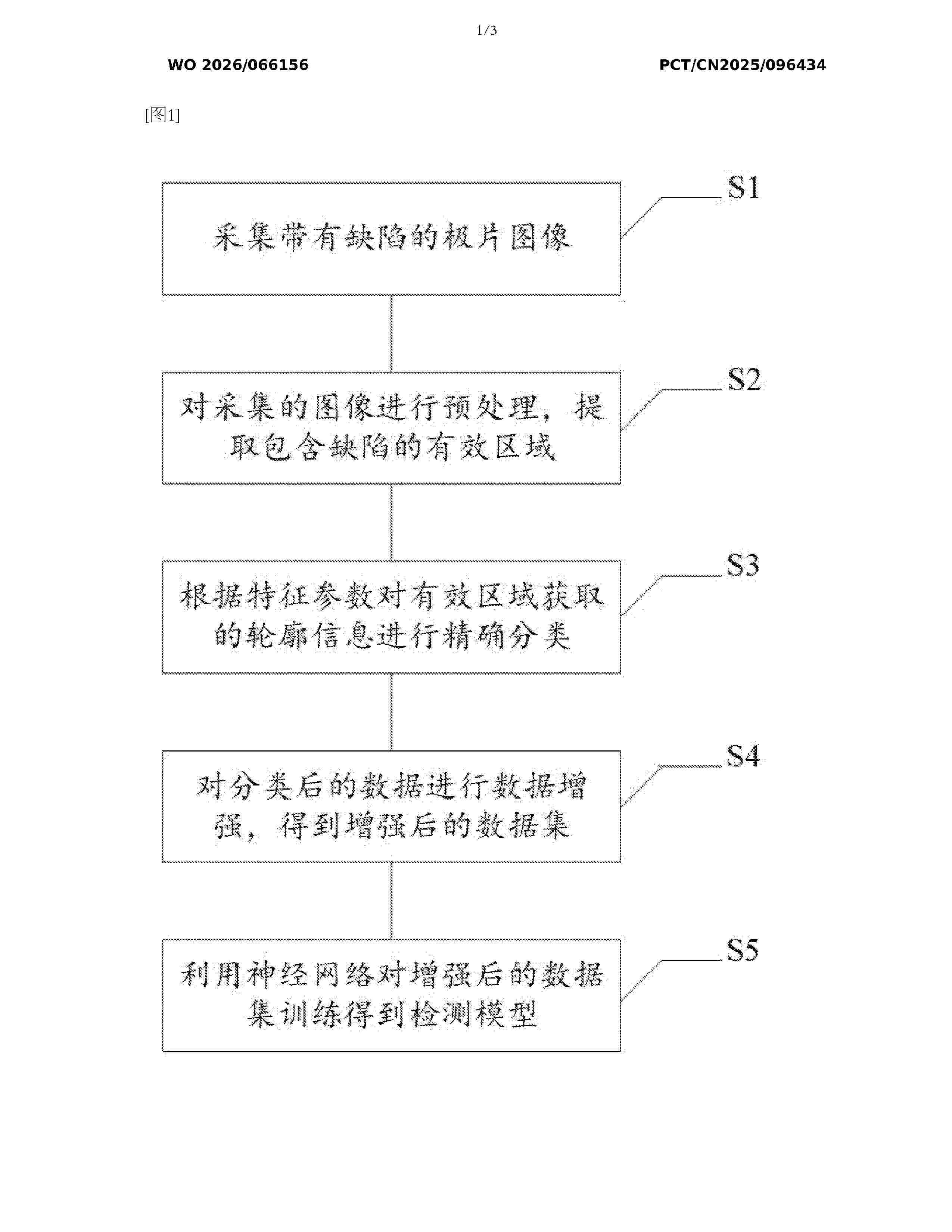
Resumen de: WO2026066156A1
Disclosed in the present invention is a method for constructing a GAN-based defect detection model for pole pieces of a blade battery. The method comprises the following steps: collecting several images of defective target pole pieces; pre-processing the images to obtain pre-processed images, and extracting valid defective regions from the images; acquiring contour information for the valid regions, and accurately classifying the contour information on the basis of characteristic parameters; performing data augmentation on classified data, so as to obtain an augmented dataset; and in the dataset, using defect types and position information as labels to train a neural network, and using a neural network model as a defect detection model for pole pieces of a blade battery. In the present invention, a dataset that has undergone data augmentation is inputted into a network as a training set, such that the problem of a severe shortage of training samples caused by numerous types of battery pole piece defects and low occurrence probabilities of individual samples is solved, and the detection accuracy of a defect detection model for pole pieces of a battery is greatly improved, thereby enabling the rapid and accurate detection of various defects and position information of pole pieces of a blade battery.
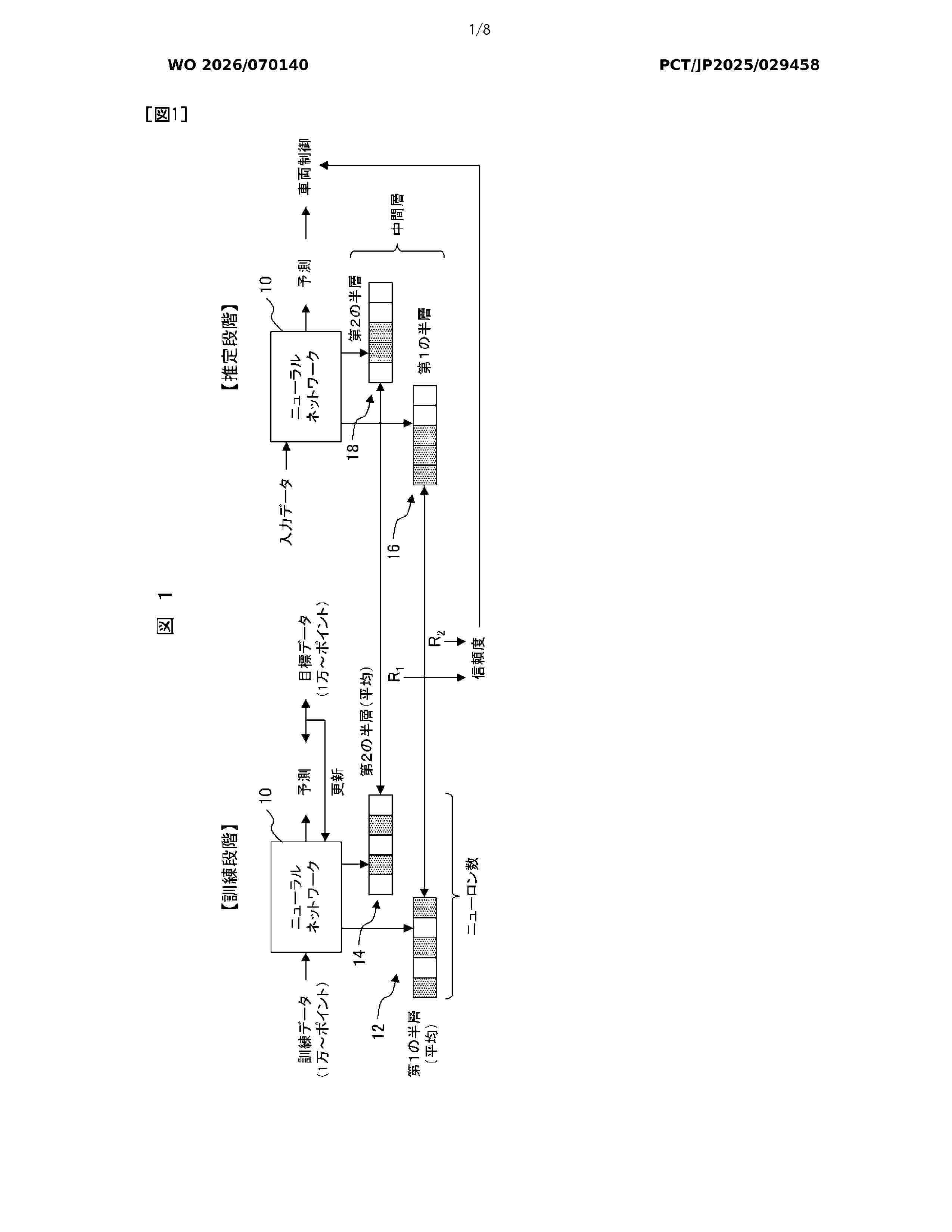
Resumen de: WO2026070140A1
The present disclosure relates to vehicle control based on a neural network. In particular, the present disclosure relates to determining confidence in the output of a neural network by comparing a firing pattern observed during operation of a vehicle with a reference firing pattern obtained by observing firing of neurons during a training phase.
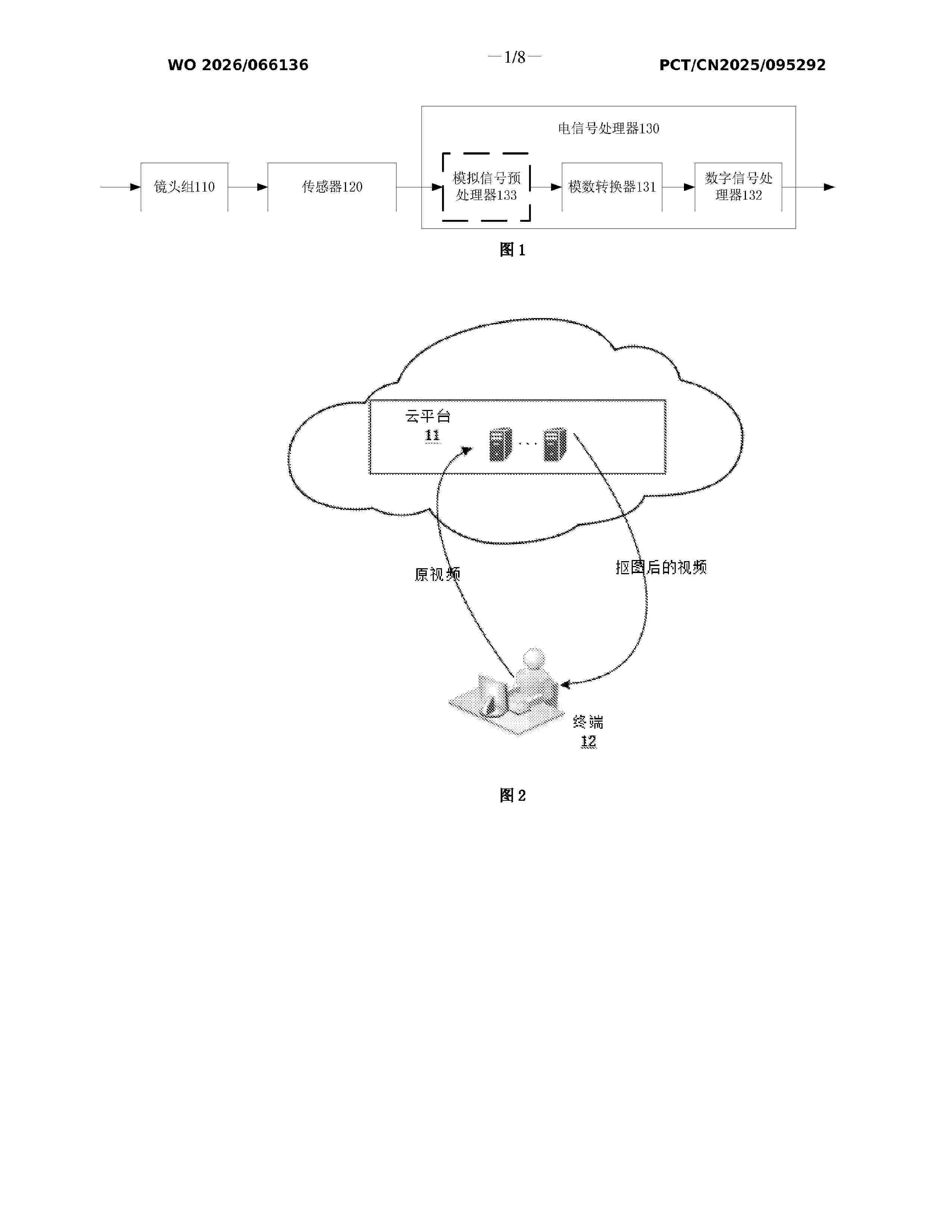
Resumen de: WO2026066136A1
Provided in the embodiments of the present application are a video processing method and a related apparatus, which are used for optimizing the matting effect of a video. The method comprises: acquiring at least one key frame among at least one first video frame; inputting the at least one first video frame into a first neural network model, so as to obtain at least one second video frame and the confidence of each second video frame; on the basis of the confidence of the at least one second video frame, screening the at least one first video frame to select at least one third video frame; in response to an operation for at least one frame among the at least one key frame or the at least one third video frame, correcting the at least one frame to obtain at least one fourth video frame; inputting the at least one fourth video frame into the first neural network model for training, so as to obtain a second neural network model; and inputting the at least one first video frame into the second neural network model, and outputting at least one fifth video frame.
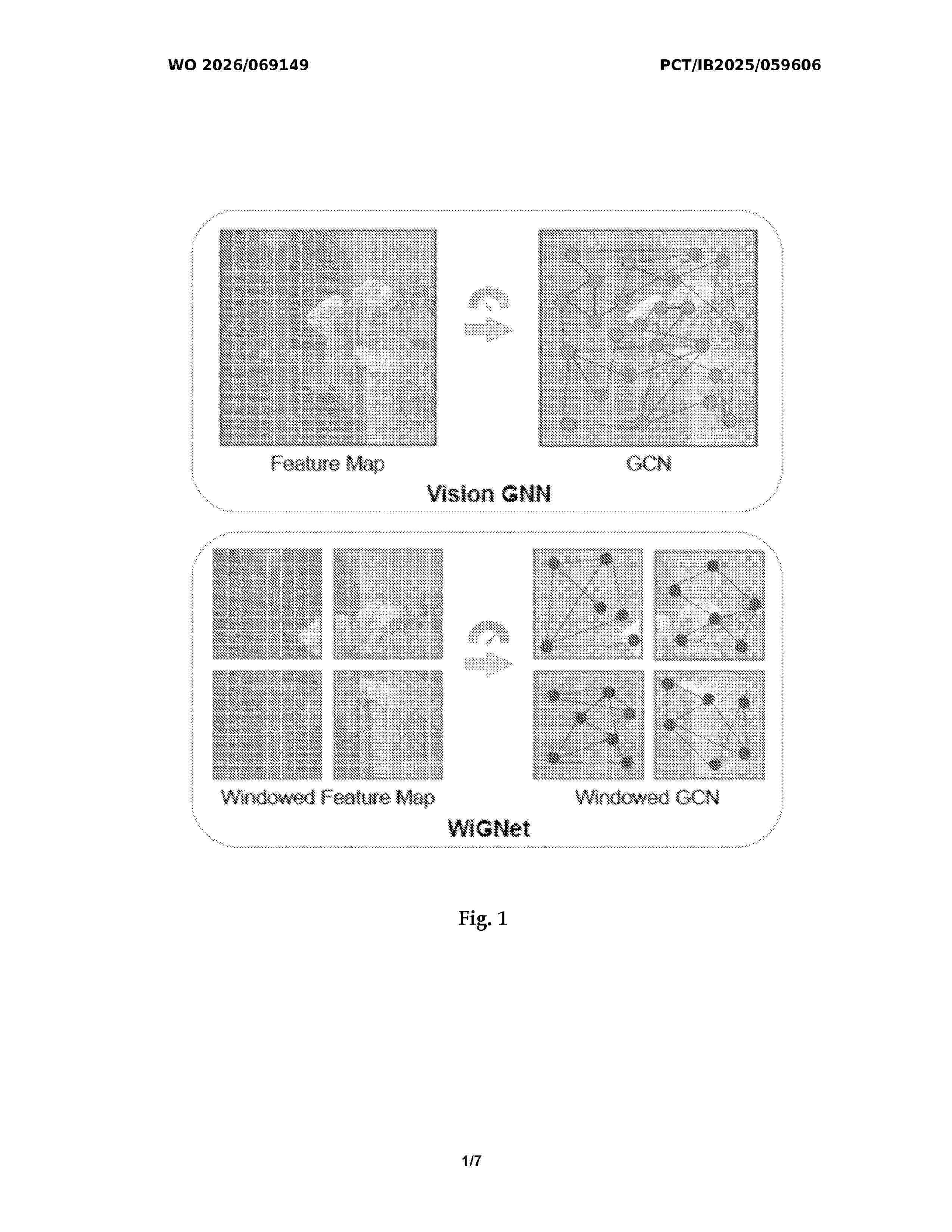
Resumen de: WO2026069149A1
It is described a method for processing an image using a vision graph neural network, said vision graph neural network comprising a window-based grapher module (7) including a first fully connected layer with batch normalization (9), a windows partitioning module (10), a dynamic graph convolution module (11), a windows reverse module (12), a second fully connected layer with batch normalization (13) and a skip connection (15), wherein said window-based grapher module (7) is configured to: - process a feature vector (X) of said image (2) through said first fully connected layer with batch normalization (9) to obtain a normalized feature vector; - partition said normalized feature vector into a plurality of non-overlapping windows using said windows partitioning module (10); - for each window, construct a graph where nodes represent patches of said image (2) within the respective window and edges represent relationships between said nodes, and apply a graph convolutional operation to each graph to update node features within each window using said dynamic graph convolution module (11); - reshape the updated node features from each window back into the format of said normalized feature vector using said windows reverse module (12); - process the reshaped feature vector through said second fully connected layer with batch normalization (13); combine said feature vector (X) directly with an output of said second fully connected layer with batch normalization (13) using said skip c
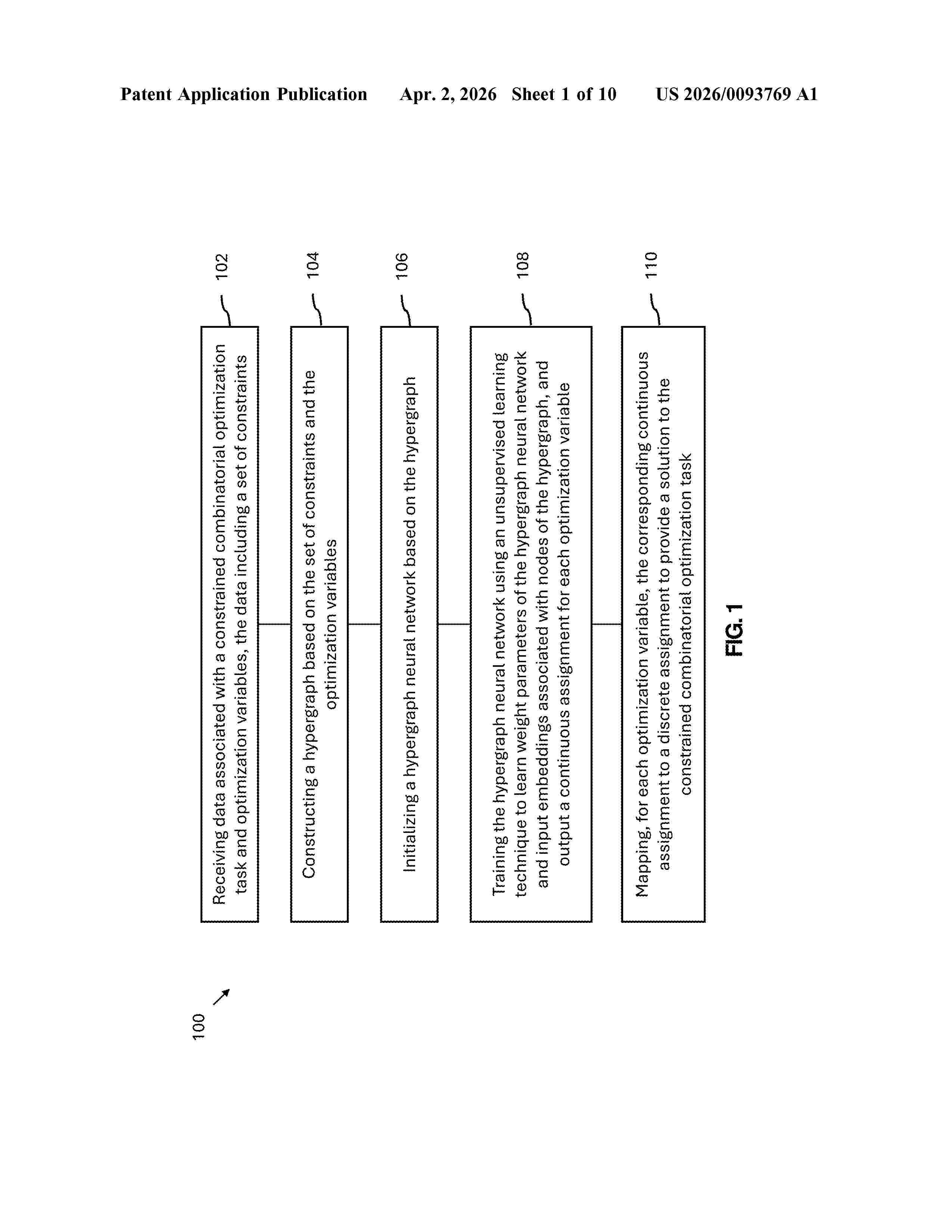
Resumen de: US20260093769A1
0000 A method for solving constrained combinatorial optimization task includes receiving data associated with a constrained combinatorial optimization task and optimization variables, the data including a set of constraints defined over subsets of the optimization variables. A hypergraph is constructed based on the set of constraints and optimization variables. Each node and hyperedge of the hypergraph corresponds to an optimization variable and a constraint respectively. A hypergraph neural network is initialized based on the hypergraph and trained using unsupervised learning to output a continuous assignment for each optimization variable. The training includes updating a plurality of learnable input embeddings associated with the nodes and weight parameters of the network. The continuous assignment is then mapped to a discrete assignment selected from a set of discrete values to yield a solution to the constrained combinatorial optimization task.
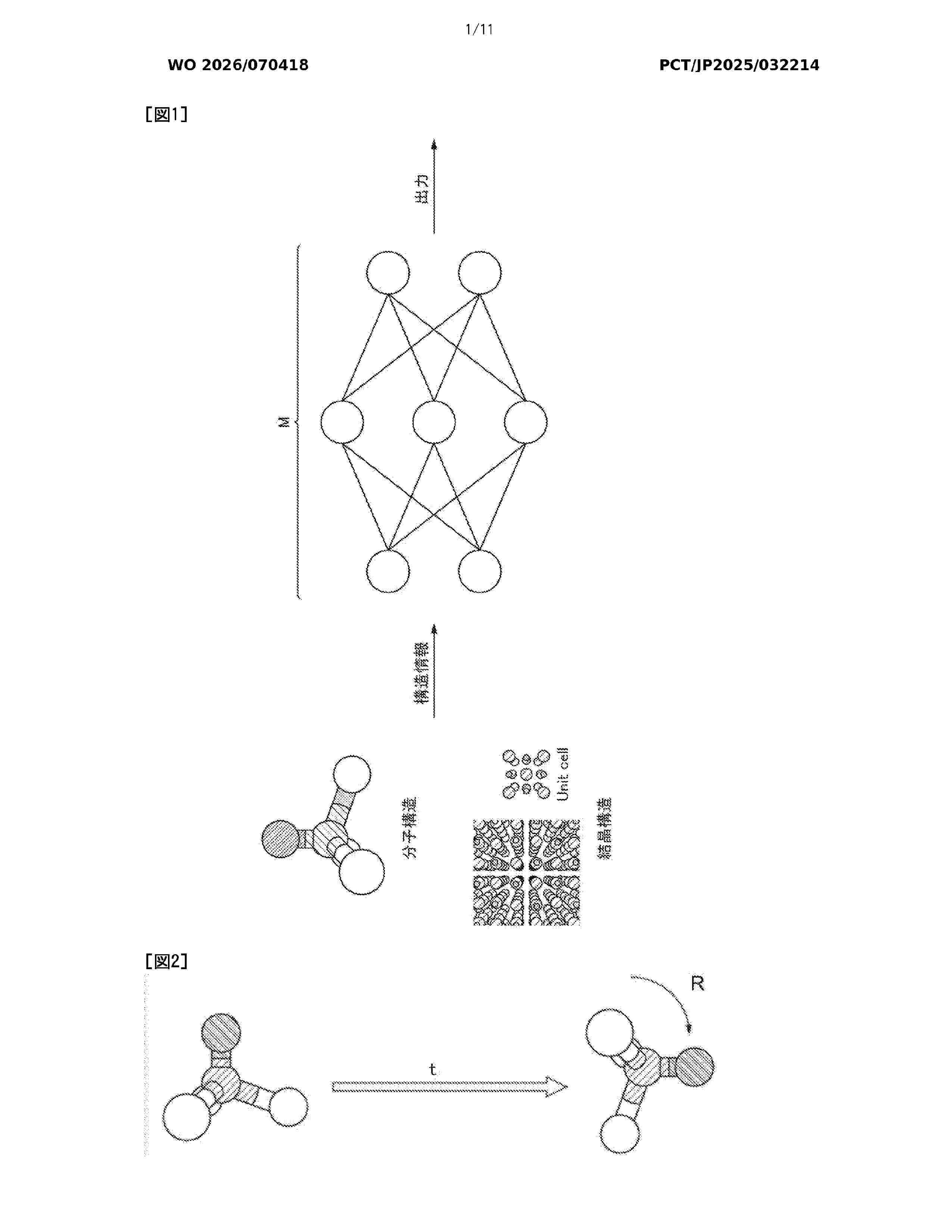
Resumen de: WO2026070418A1
In this information processing method using a neural network for a structure represented as a set of nodes arranged in space, a computer executes processing including: receiving input of a state of each node; calculating, on the basis of states between the nodes, a frame representing a coordinate axis for each node; and extracting, using the frame, information having predetermined symmetry of the structure from each node.
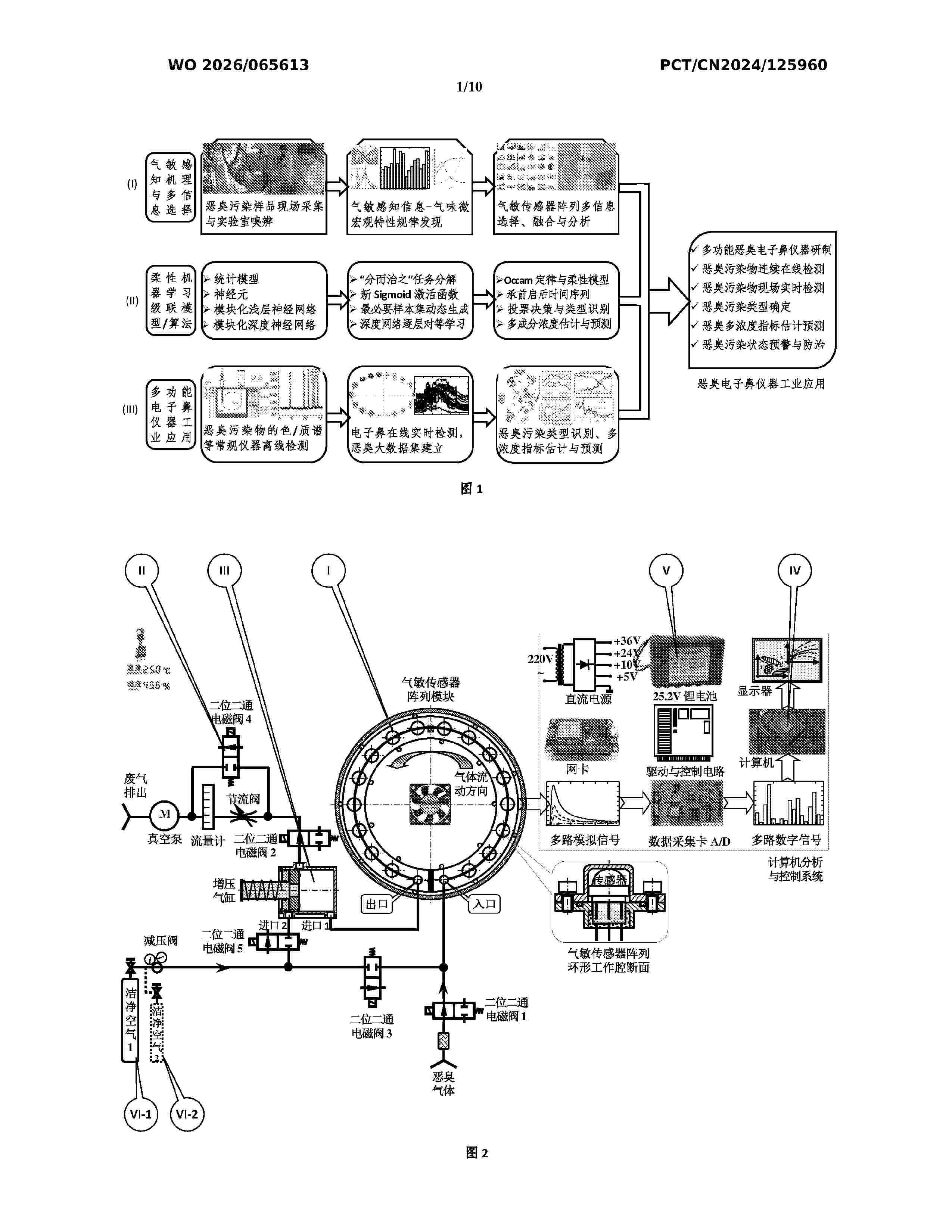
Resumen de: WO2026065613A1
An electronic nose instrument operable in both scheduled and on-demand modes and a method for online real-time detection and analysis of multi-component odors. A hardware unit of the electronic nose instrument mainly comprises: a gas-sensitive sensor array module (I), a headspace sampling module (II), a pressurization cylinder (III), a computer control and analysis module (IV), a backup power supply (V), and a clean air cylinder (VI). A main housing integrates the first four components. Within a cycle time T=180-600 s, the pressurization cylinder (III) significantly increases a gas-sensitive response by means of short-term pressure multiplication. The gas-sensitive sensor array obtains a 50-dimensional sensing sample for single detection. A large odor dataset X comprises online detection data from the electronic nose instrument, and offline detection data from olfactometry and chromatography etc. The detection data is decomposed into multiple single-concentration sub-tasks. A machine learning cascade model is formed by multiple learning groups consisting of single neurons, and shallow and deep neural networks. The electronic nose instrument can flexibly achieve online real-time identification of odor pollutants and multi-component concentration estimation and prediction.
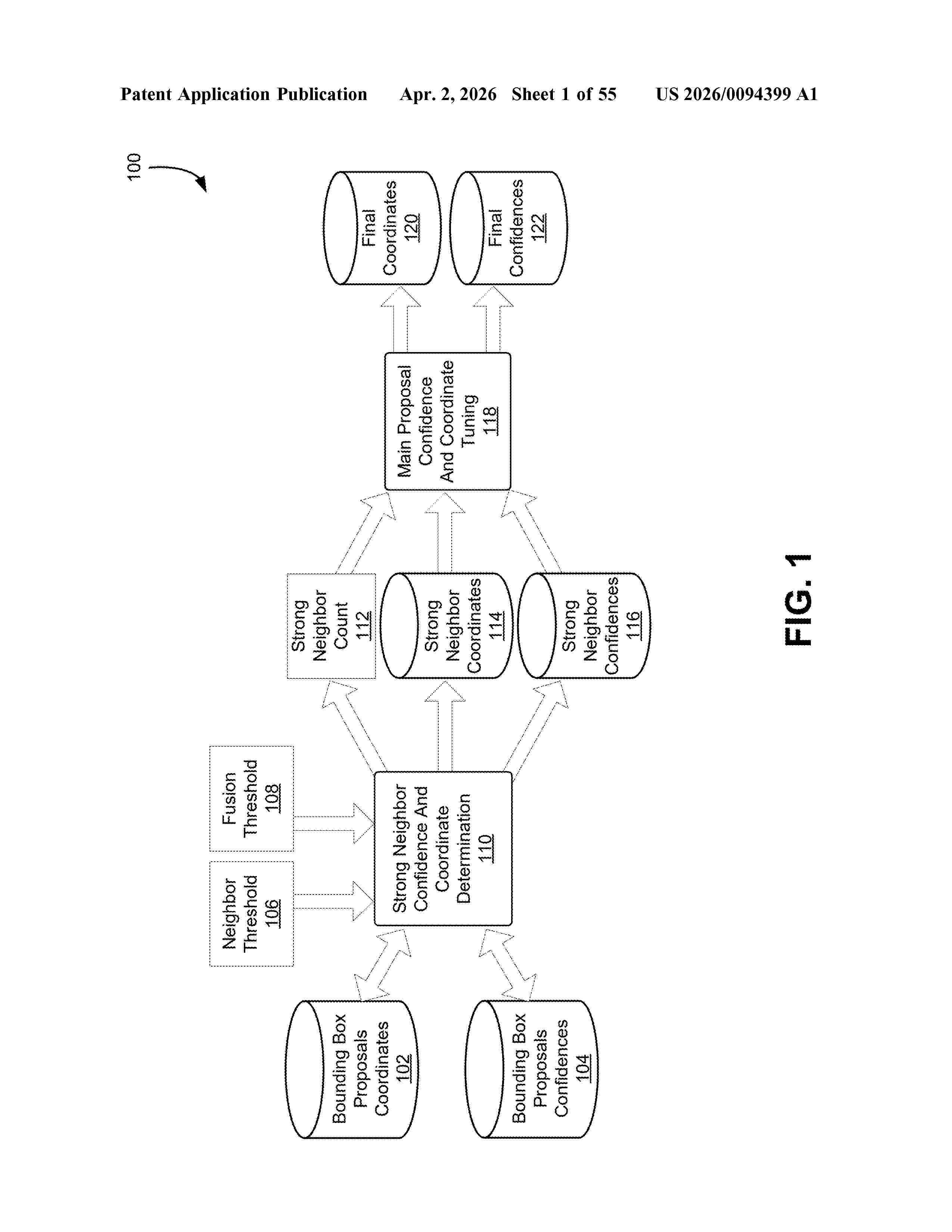
Resumen de: US20260094399A1
0000 Apparatuses, systems, and techniques to generate bounding box information. In at least one embodiment, for example, bounding box information is generated based, at least in part, on a plurality of candidate bounding box information.
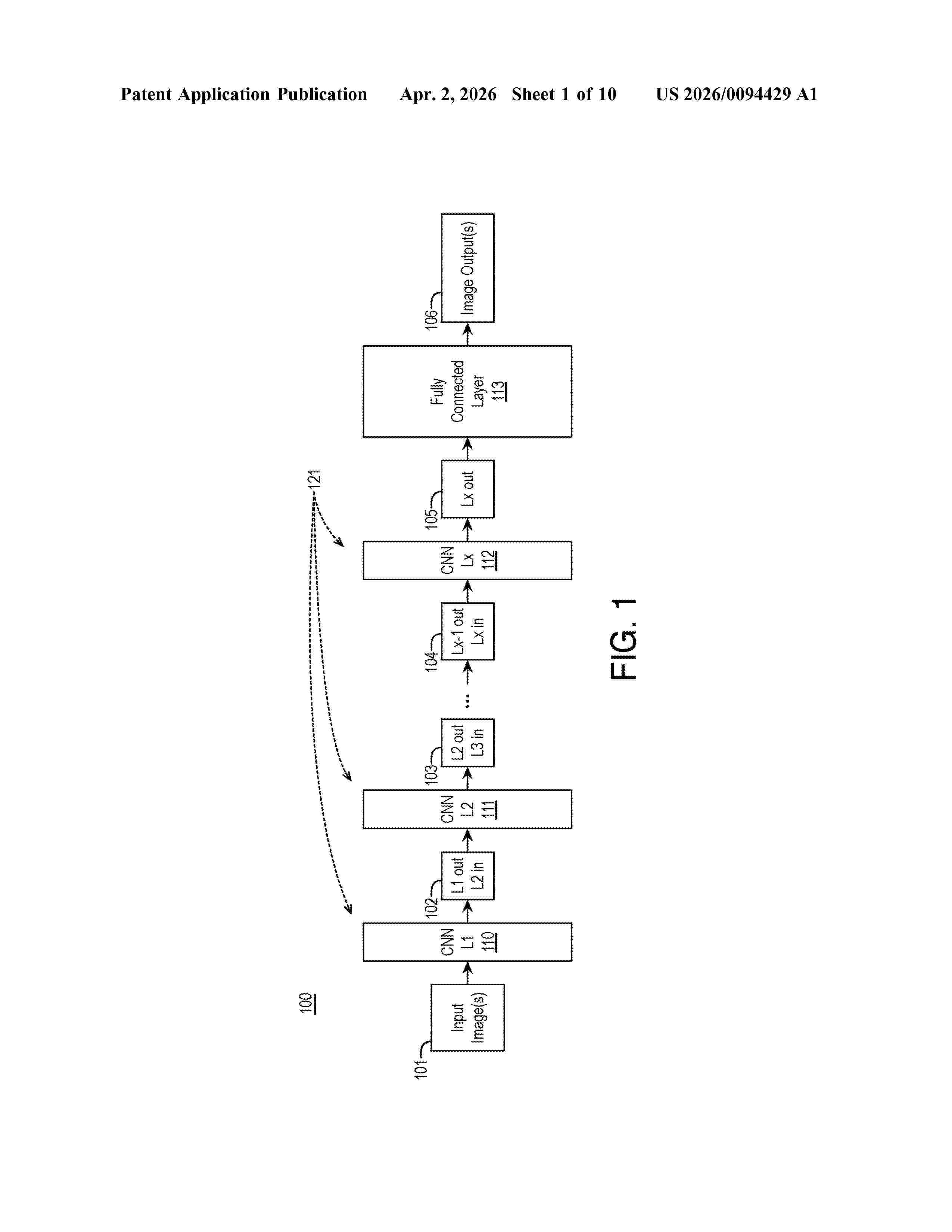
Resumen de: US20260094429A1
Techniques related to poly-scale kernel-wise convolutional neural network layers are discussed. A poly-scale kernel-wise convolutional neural network layer is applied to an input volume to generate an output volume and include filters each having a number of filter kernels with the same sample rate and differing dilation rates optionally in a repeating pattern of dilation rate groups within each of filters with the pattern of dilation rate groups offset between the filters the poly-scale kernel-wise convolutional neural network layer.
Nº publicación: US20260093717A1 02/04/2026
Solicitante:
INTUIT INC [US]
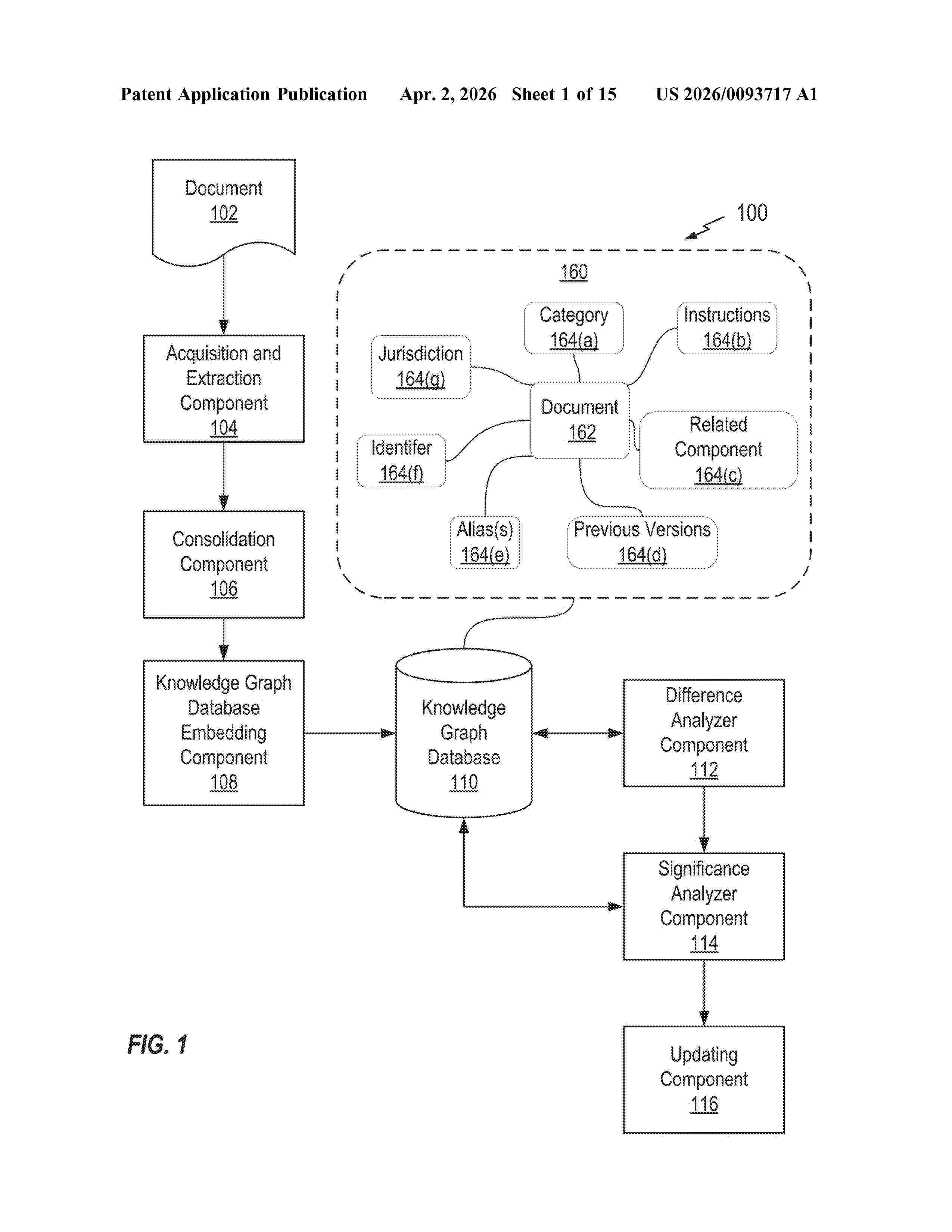
Resumen de: US20260093717A1
Certain aspects of the disclosure provide for a difference analysis method. In certain aspects, a difference analysis method may include embedding a set of source documents into a knowledge graph, wherein each source document is embedded in the knowledge graph as a set of segments and a set of associations connecting two or more segments. A difference may be determined between a first segment in the set of segments of a first source document and a second segment in the set of segments of a second source document. In response to determining the difference between the first segment in the set of segments of the first source document and the second segment in the set of segments of the second source document, determining a significance of the difference on the second source document based on one or more associations of the set of associations connected to the second segment.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica