Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 70
resultados
70
resultados
 Última actualización
30/04/2026 [07:13:00]
Última actualización
30/04/2026 [07:13:00]


 Resultados 25 a 50 de 70
Resultados 25 a 50 de 70

Resumen de: US20260105259A1
A computerized method for extracting domain specific insights from a corpus of files containing large documents comprising: breaking down large chunks of text into smaller sentences/short paragraphs in a domain specific way, identifying and removing domain noise; identifying the sentence intents of the non-noise sentences; tagging the sentences with other domain specific attributes; defining a semantic ontology using a graph database based on the sentence intents, a multitude of mini-dictionaries and domain attributes; applying a pre-defined ontology to tag documents with domain specific hashtags; and combining the hashtags using machine learning techniques into insights.

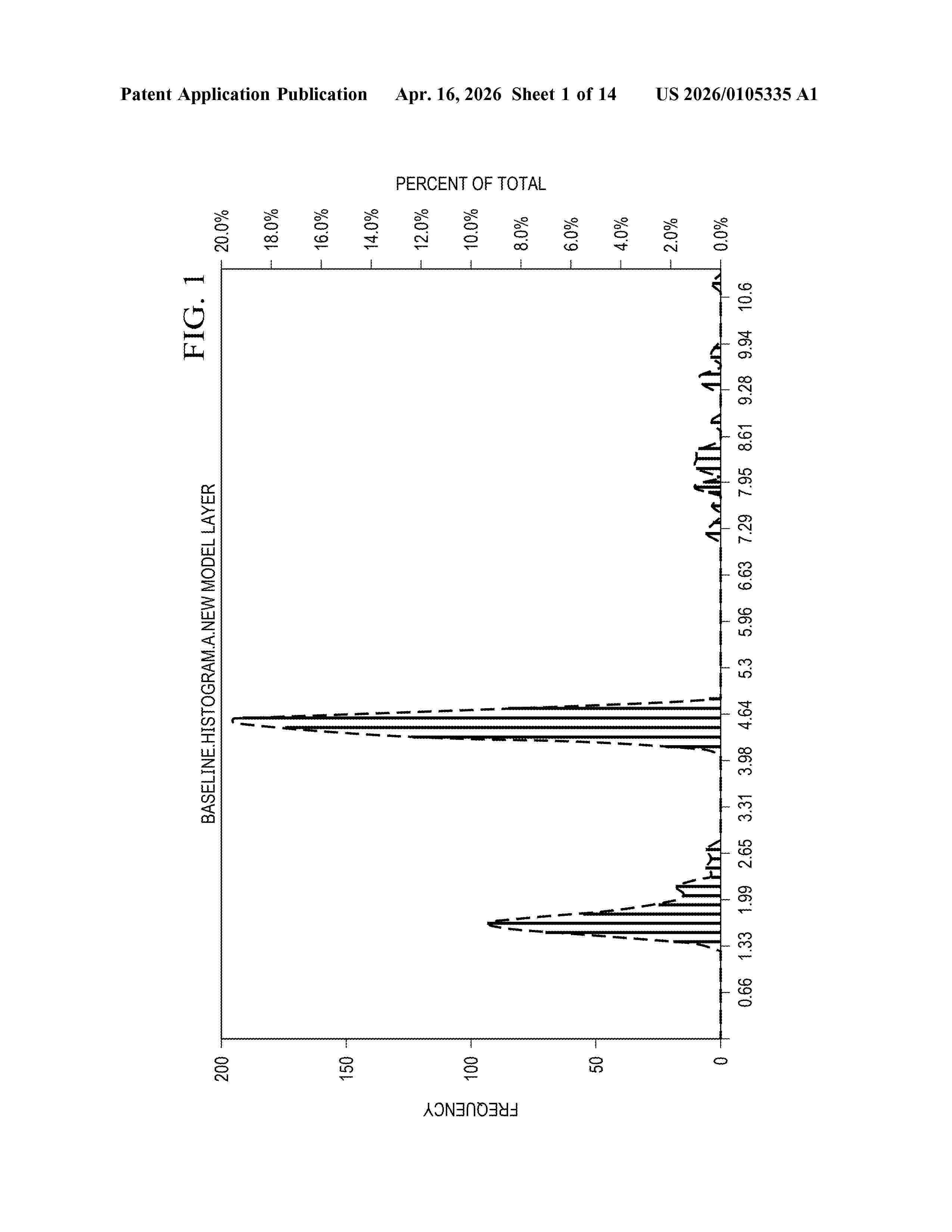
Resumen de: US20260105335A1
A methodology for correlated histogram clustering for machine learning which does not require a priori knowledge of cluster numbers, which extends beyond bimodal scenarios to multimodal scenarios, and does not need iterative optimization methods nor require powerful data processing.
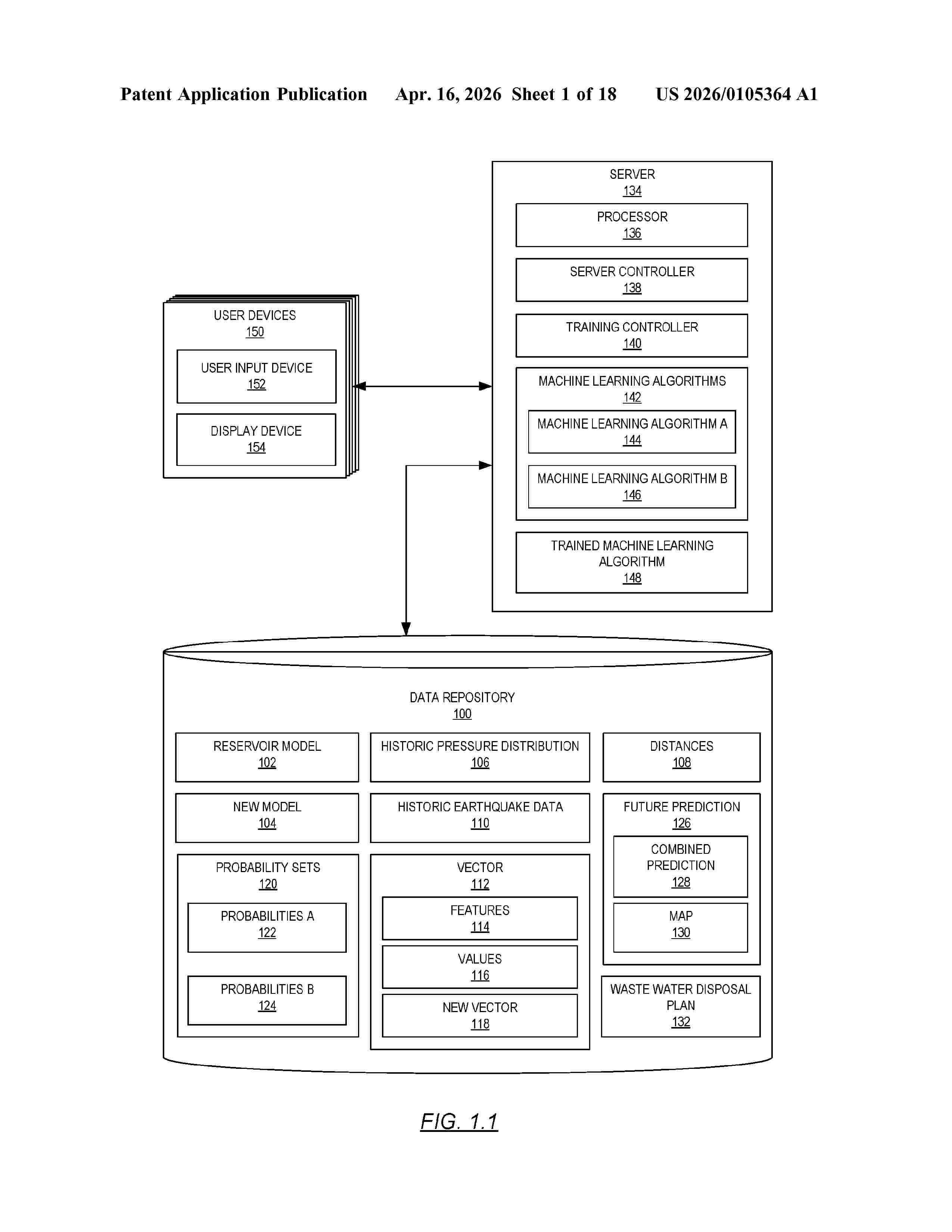
Resumen de: US20260105364A1
A method including receiving a reservoir model of a target under-ground region. The method also includes extracting, from the reservoir model, a historic pressure distribution in grid cells of the target underground region. The method also includes extracting, from the reservoir model, distances. Each distance represents a distance between a grid cell and a corresponding lineament in the target underground region. The method also includes receiving historic earthquake data of past earthquakes in the target underground region. The method also includes generating a vector. The vector includes features and corresponding values for at least i) the historic pressure distribution, ii) the distances, and iii) the historic earthquake data. The method also includes training a trained machine learning algorithm by recursively executing a machine learning algorithm on the vector until convergence.
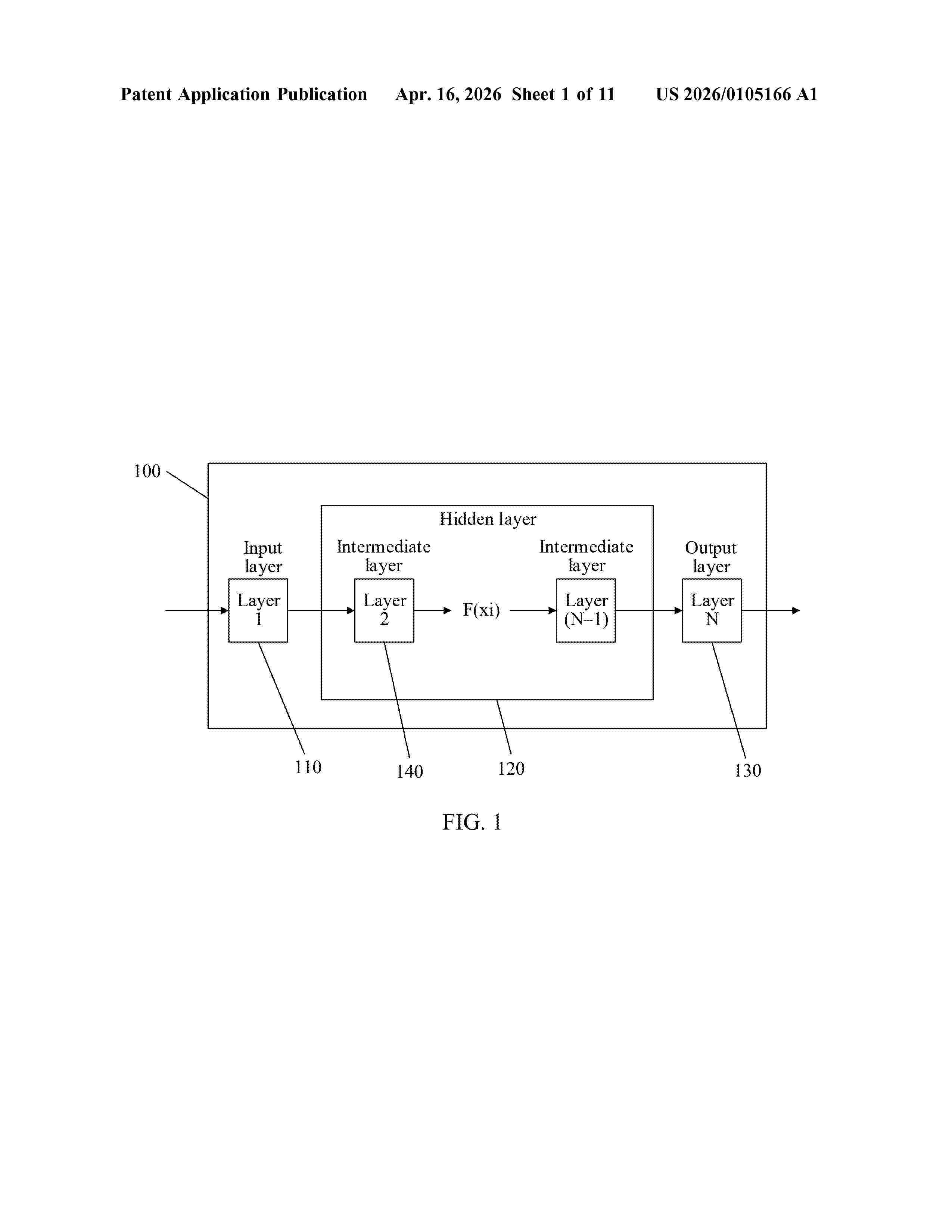
Resumen de: US20260105166A1
A model inference method and apparatus are disclosed, and relates to the field of machine learning technologies. A client and a server use respective deployed models to process different parts of user data, to obtain respective output results. In addition, the client obtains the output result of the server, and obtains an inference result based on the output results of the server and the client. Compared with a case in which the server needs to obtain all the user data in an inference process, in this application, the server obtains only a part of the user data. As the server cannot obtain, based on the part of the user data, all content included in the user data, security of the user data is ensured.
Resumen de: AU2024359770A1
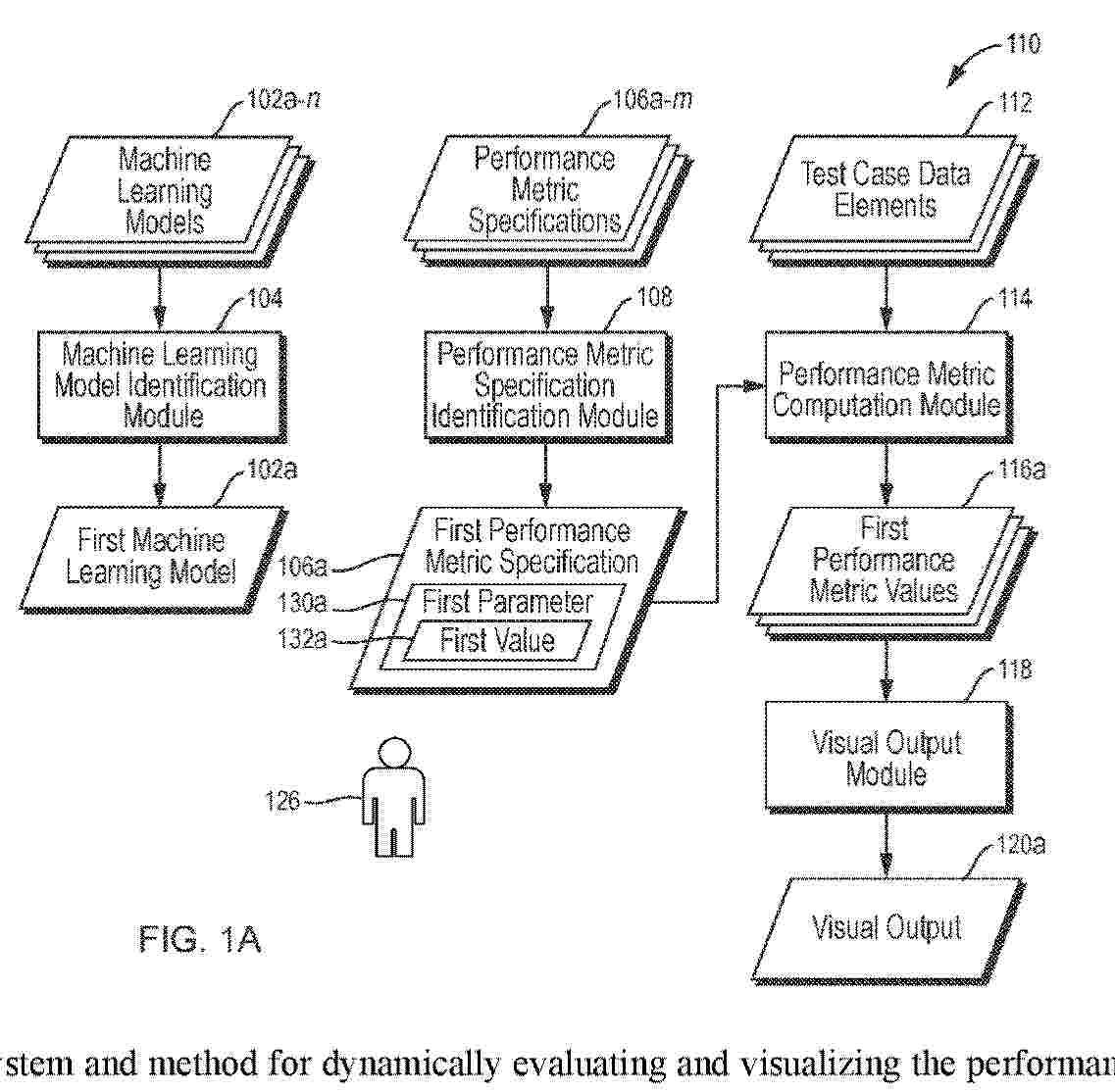
A universal system and method for dynamically evaluating and visualizing the performance of any predictive model, including machine learning models. The system and method compute performance metrics based on test set data and display visual representations in real-time, allowing users to interactively explore model performance by adjusting parameters that reflect model-deployment scenarios. Key features include model-agnostic design, support for both technical and business metrics, and the ability to compare multiple models. The system and method's extensible architecture enables custom metrics and visualizations, making them scalable across various modeling use cases and industries. By providing intuitive, real-time visual feedback, embodiments of the invention empower both technical and non-technical stakeholders to gain deeper insights into model behavior, leading to more informed decisions about deployment and optimization.
Resumen de: AU2026202443A1
Computerized systems and methods are disclosed for automating Configure to Order (CTO) and Quote to Order (QTO) processes. Methods include receiving user inputs for desired product configurations, retrieving corresponding data from a bill of materials database, and calculating optimized pricing through intelligent rules based on real-time market data. Automated quotes are generated and transferred to orders in a vendor system, selected based on pre-set criteria like vendor reputation and delivery time. Validation steps reduce errors, and real-time reports are generated. The system integrates a Real-Time Data Mesh for data aggregation, a Single Pane of Glass User Interface for user interactions, and Advanced Analytics and Machine Learning Modules for implementing rule-based and learning algorithms. The system is accessible across various devices and standardizes data for uniform consumption, while also employing machine learning models to continually optimize processes. Notifications are sent to users upon successful execution of orders or completion of quotes. ar a r
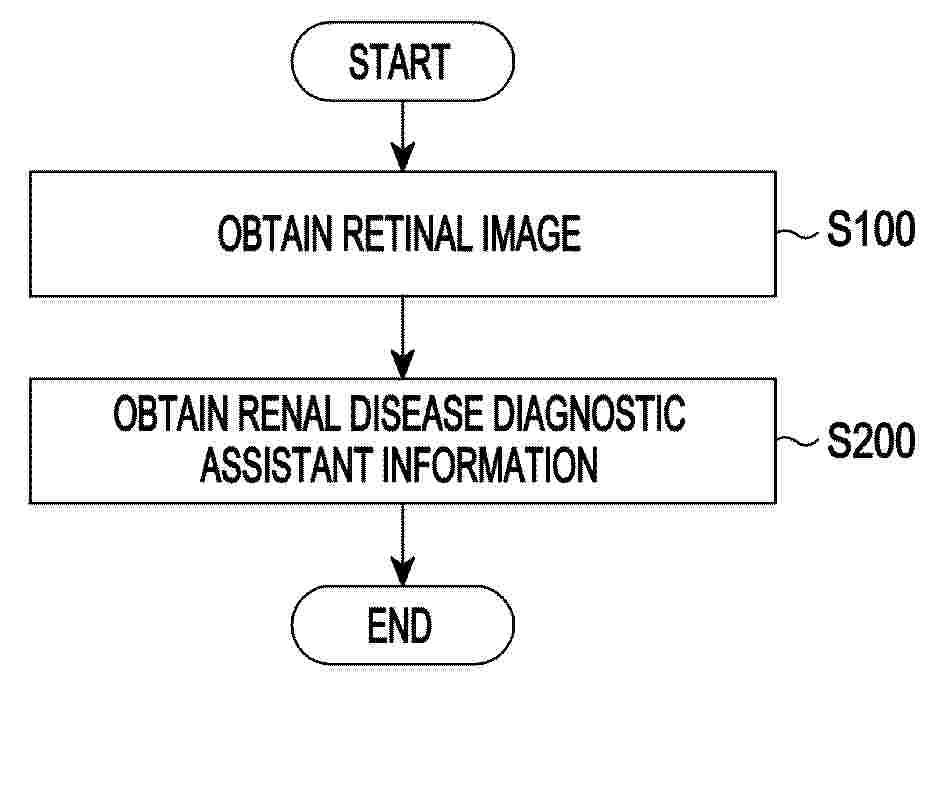
Resumen de: EP4725391A1
0001 A method and device for diagnosing renal disease are disclosed. A control method of a diagnostic device according to one embodiment comprises: obtaining a retinal image of a subject; and obtaining renal disease diagnostic information regarding the subject using a machine learning model based on the retinal image, wherein the machine learning model includes a first model and a second model, wherein the first model is a neural network model, and wherein the second model is a regression-based machine learning model.
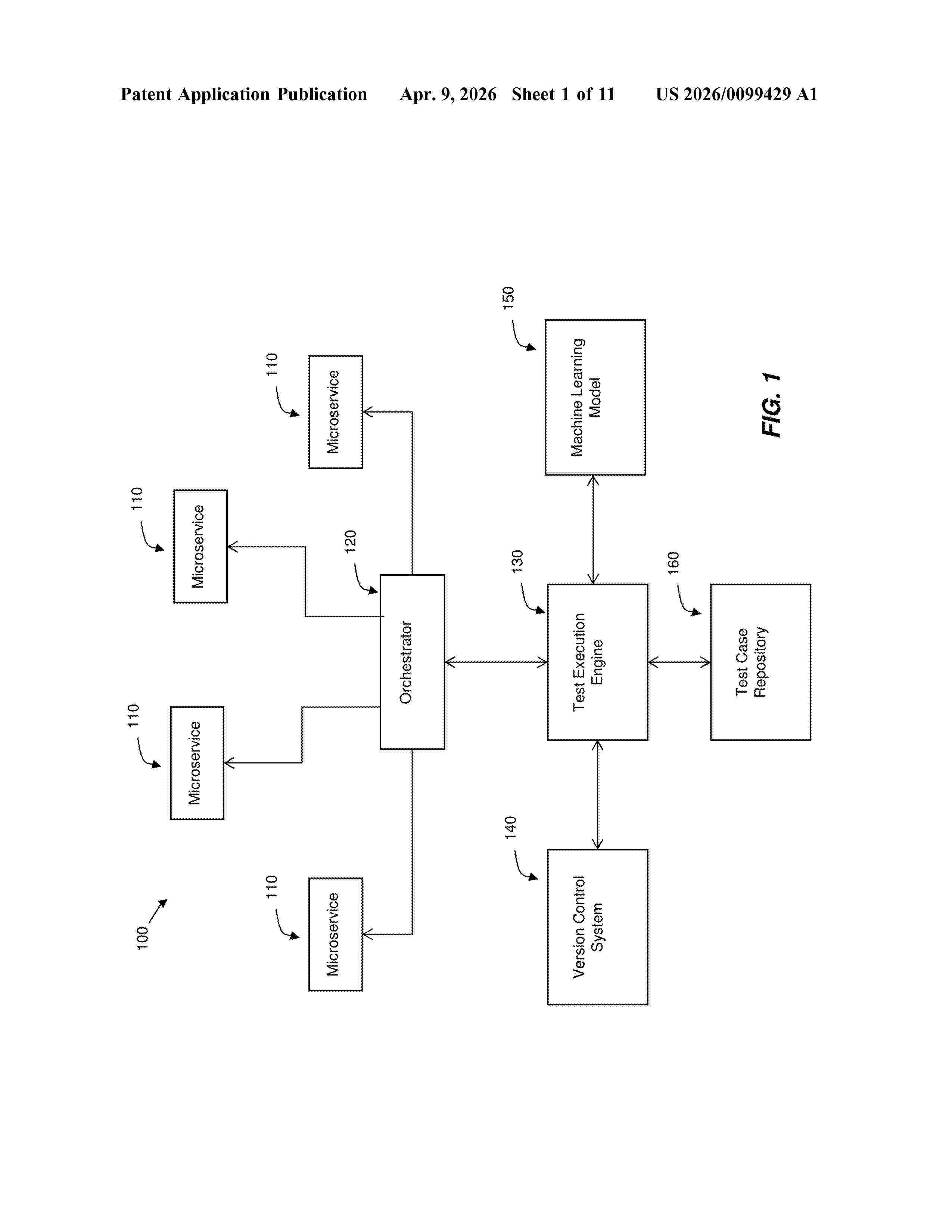
Resumen de: US20260099429A1
A computer-implemented method and system can be used to test a code modification for a microservice application. The code modification is analyzed using a machine learning model trained on historical test run results and code change data, Based on the analysis, a subset of test cases relevant to the code modification are predicted and selected from a test case repository. The selected subset of test cases can be executed to test the code modification. If the test cases are stored in natural language, natural language processing can be used to determine actionable words and assign weightages from the test case information. Test scripts can be developed based on the determined actionable words and assigned weightages.
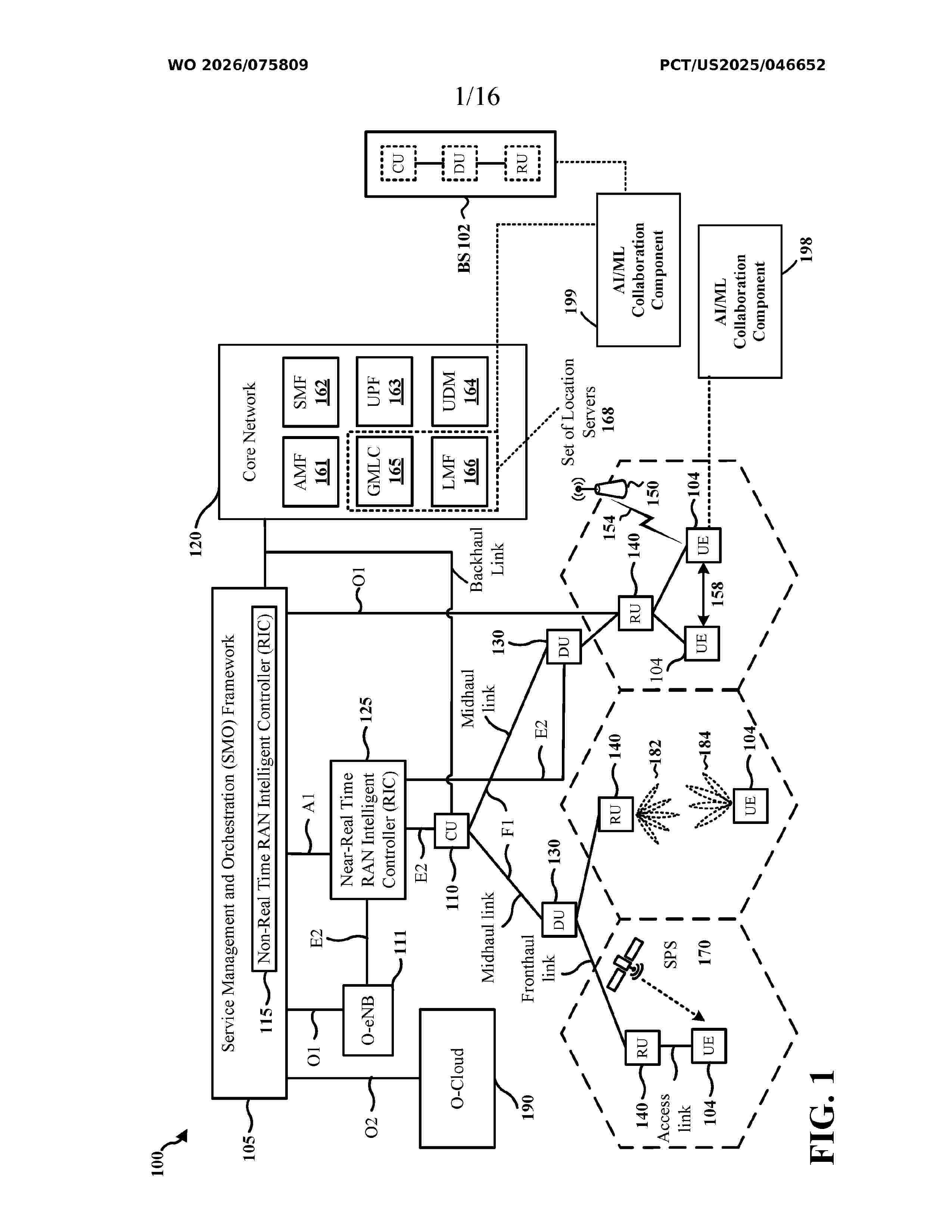
Resumen de: WO2026075809A1
Aspects presented herein may enable a user equipment (UE) to determine a collaboration level to be applied to at least one artificial intelligence (AI) or machine learning (ML) (AI/ML) model/functionality based on a set of defined conditions, thereby improving and promoting collaborations between the UE and a network entity related to AI/ML positioning and/or sensing. In one aspect, a UE communicates, with a network entity, a request for a performance of at least one AI/ML-based functionality. The UE selects, based on a set of conditions, a collaboration level from a set of collaboration levels to be applied to the performance of at least one AI/ML-based functionality. The UE performs the at least one AI/ML-based functionality based on the selected collaboration level.
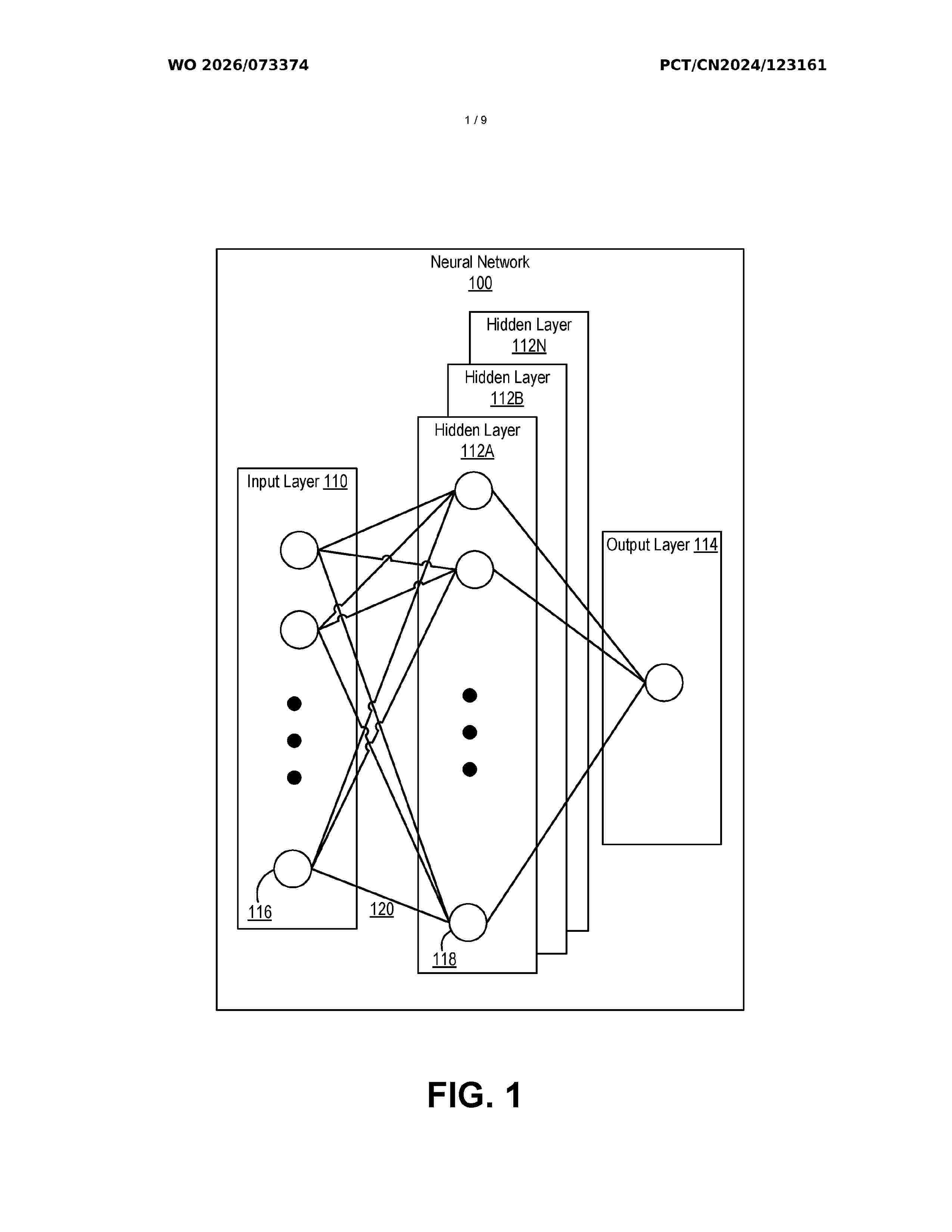
Resumen de: WO2026073374A1
Systems and techniques for machine learning model operation and/or optimization are described. In some examples, a system identifies a difference between an input size of an input and a context window size associated with a trained machine learning model. The trained machine learning model is associated with a computational graph having a static shape. The computational graph includes a plurality of operations. The system processes the input using the trained machine learning model to generate an output. To process the input using the trained machine learning model, the system executes a first subset of the plurality of operations (e.g., valid operations and/or semi-valid operations) and skips a second subset of the plurality of operations (e.g., invalid operations). The first subset of the plurality of operations is associated with the input. The second subset of the plurality of operations is associated with the difference.
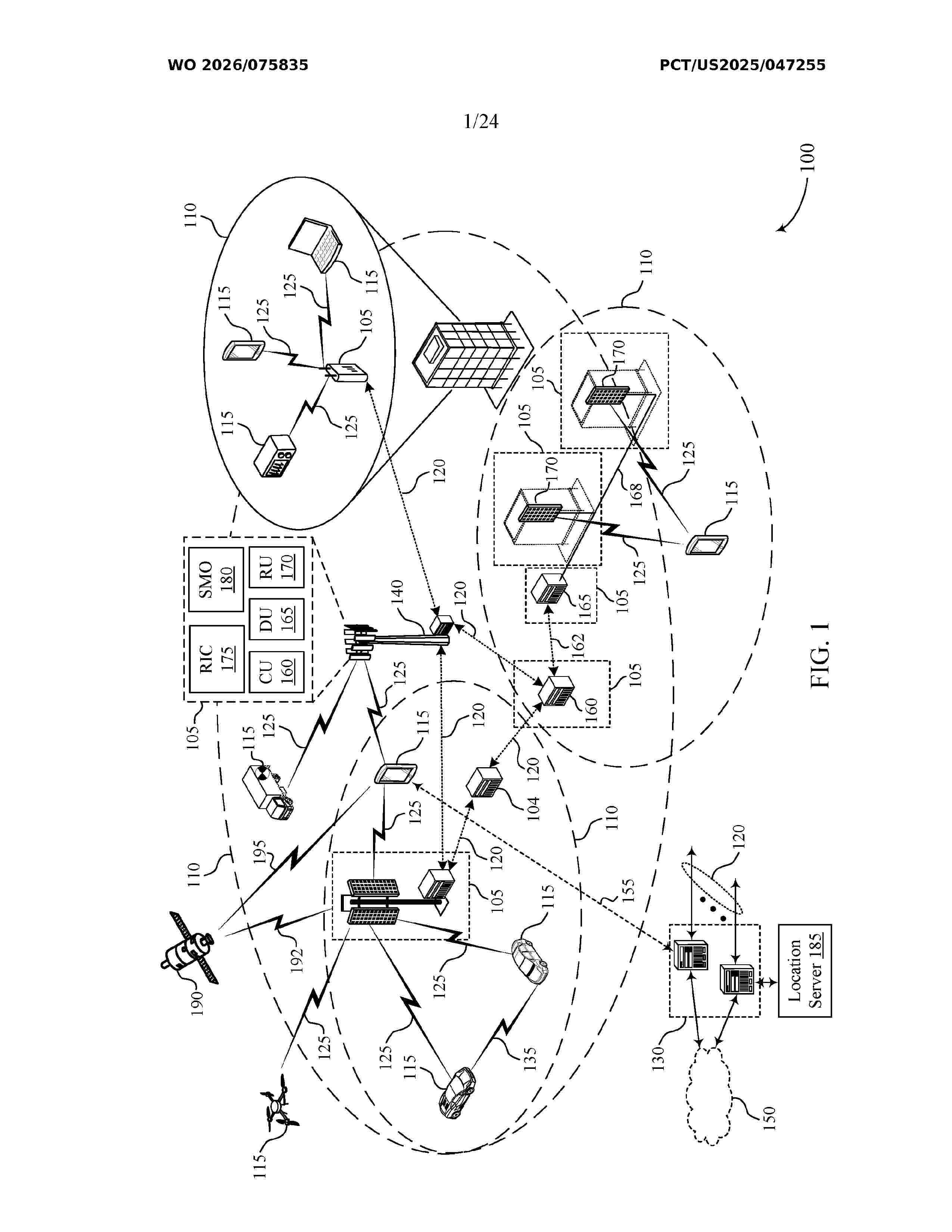
Resumen de: WO2026075835A1
In some examples of the techniques described herein, one or more network settings may be associated with an identifier. In some approaches, a network entity may indicate one or more identifiers to a wireless device for checking an artificial intelligence or machine learning (AI/ML) model on the wireless device. For instance, a network entity may help to maintain a correspondence or alignment between identifiers and corresponding network settings during training data collection or inference. Network settings may change over time, and a network entity may control AI/ML positioning running at the wireless device. For instance, the network entity may indicate the wireless device to activate, deactivate, select, or switch an AI/ML model, or to fall back to a non-AI/ML-based positioning procedure. One or more operations may be utilized to enable life cycle management (LCM) based on the associated identifiers.
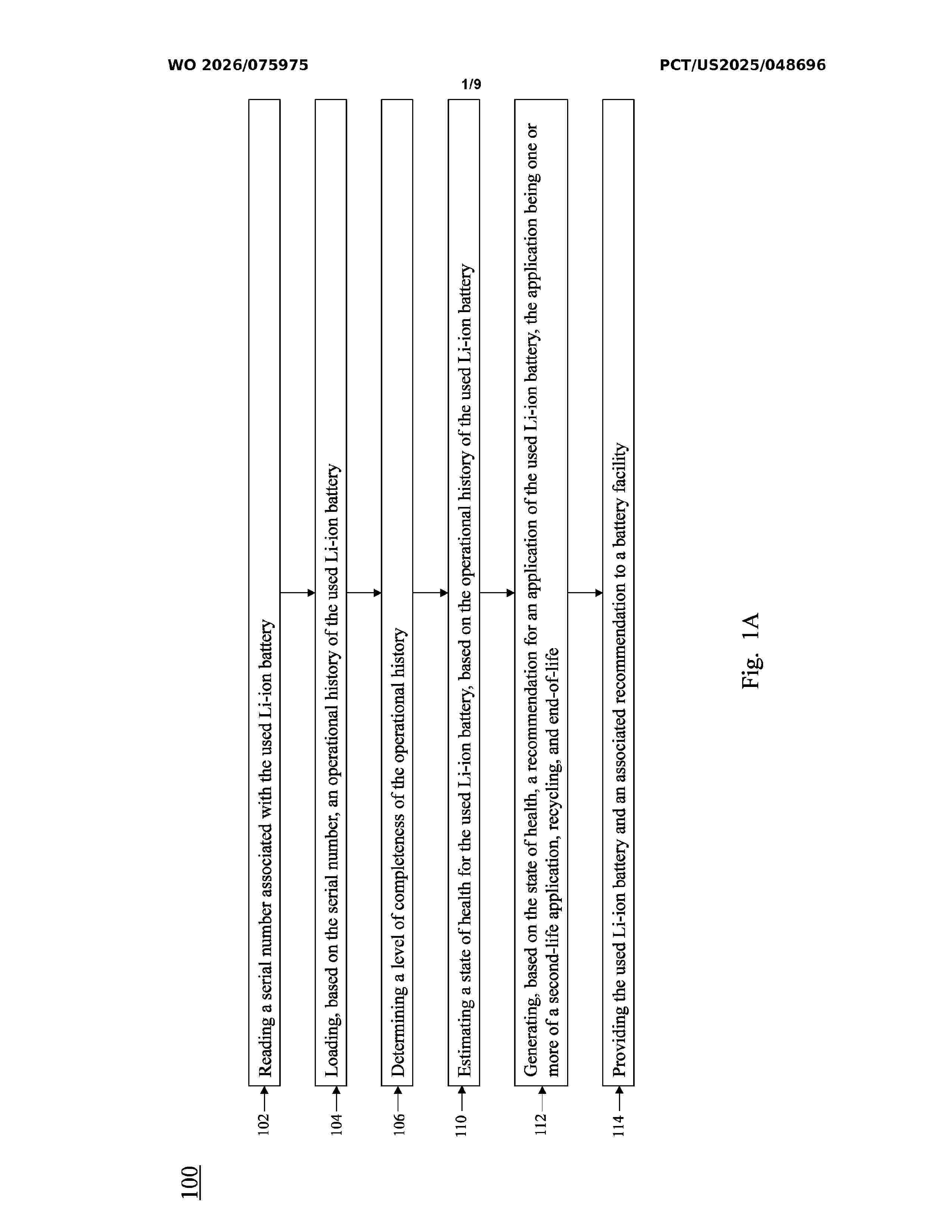
Resumen de: WO2026075975A1
Systems and methods disclosed herein comprise providing operational history and an electrolyte of a used Li-ion battery to a machine-learning model; receiving, from the machine-learning model, an estimate of a state of health (SoH) of the used Li-ion battery; reading parameters of the used Li-ion battery; providing the parameters and the estimate of the SoH of the used Li-ion battery to a machine-learning model trained to output a rate of degradation of the SoH of the used Li-ion battery in response to receiving parameters and a SoH; receiving, from the machine-learning model, a rate of degradation of the SoH of the used Li-ion battery; generating, based on the estimate of the SoH and the rate of degradation, a recommendation for an application of the used Li-ion battery, the application being a second-life application, recycling, or end-of-life; and providing the used Li-ion battery and a recommendation to a facility.
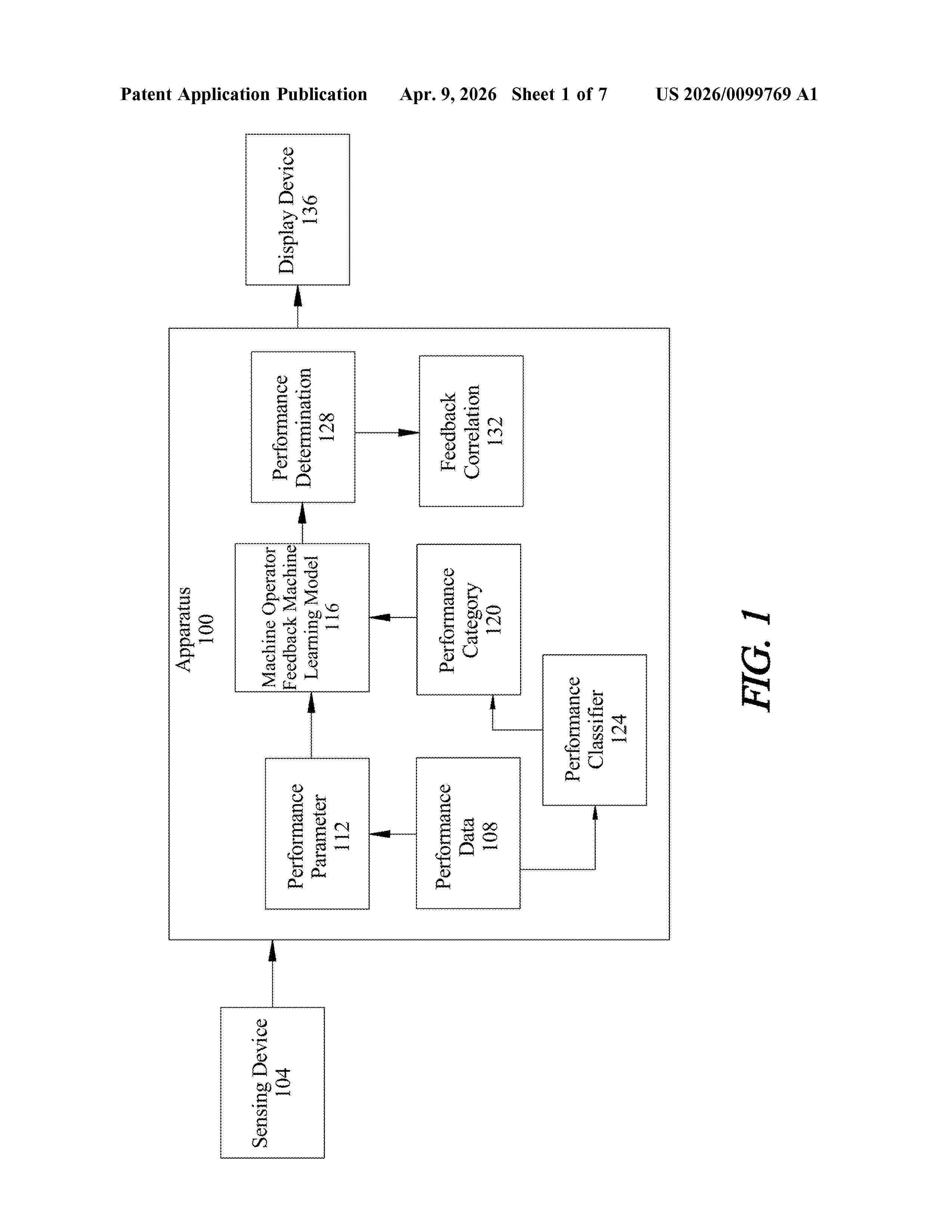
Resumen de: US20260099769A1
In an aspect, an apparatus for machine operator feedback correlation is presented. An apparatus includes at least a processor and a memory communicatively connected to the at least a processor. A memory contains instructions configuring at least a processor to receive, through a sensing device, performance data of at least a machine operator. At least a processor is configured to classify performance data to a performance category through a performance classifier. At least a processor is configured to calculate a performance determination. At least a processor is configured to generate a feedback correlation through a machine operator feedback correlation machine learning model. At least a processor is configured to provide a feedback correlation to a user through a display device.
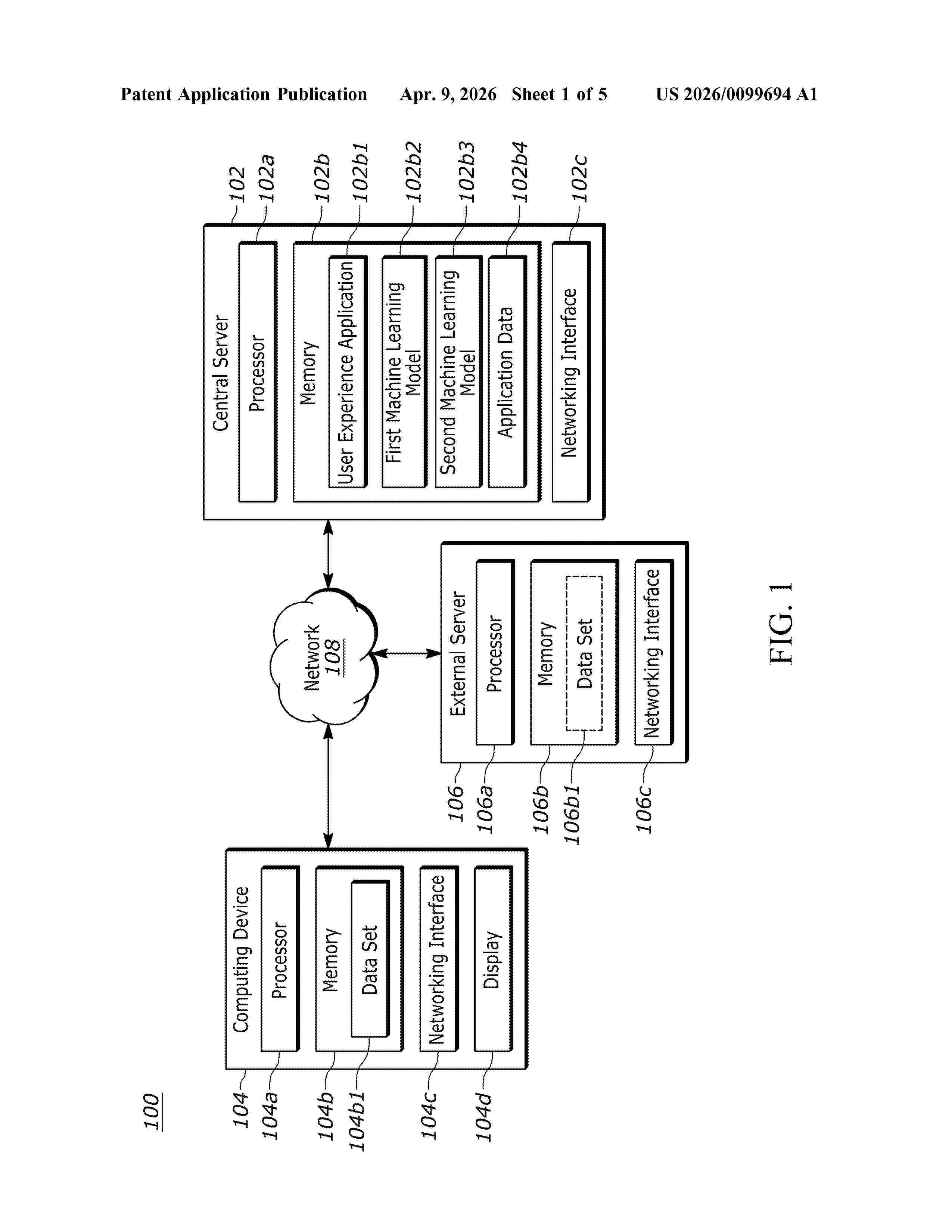
Resumen de: US20260099694A1
Techniques for improved user experience prediction are disclosed herein. An example computer-implemented method includes receiving a sequence of web pages visited by a user and applying a machine learning model to (i) the sequence of web pages and (ii) a set of metrics data corresponding to the sequence of web pages. Applying the machine learning model includes generating embeddings of web page identifiers associated with the sequence of web pages, determining, by a first hidden layer, a first modified embedding based on respective cross-effects associated with one or more other embeddings, determining, by a second hidden layer, a second modified embedding based on the set of metrics data associated with a respective first modified embedding, and outputting a user experience value for each second modified embedding. The example computer-implemented method further includes generating one or more data objects indicating one or more of the user experience values.
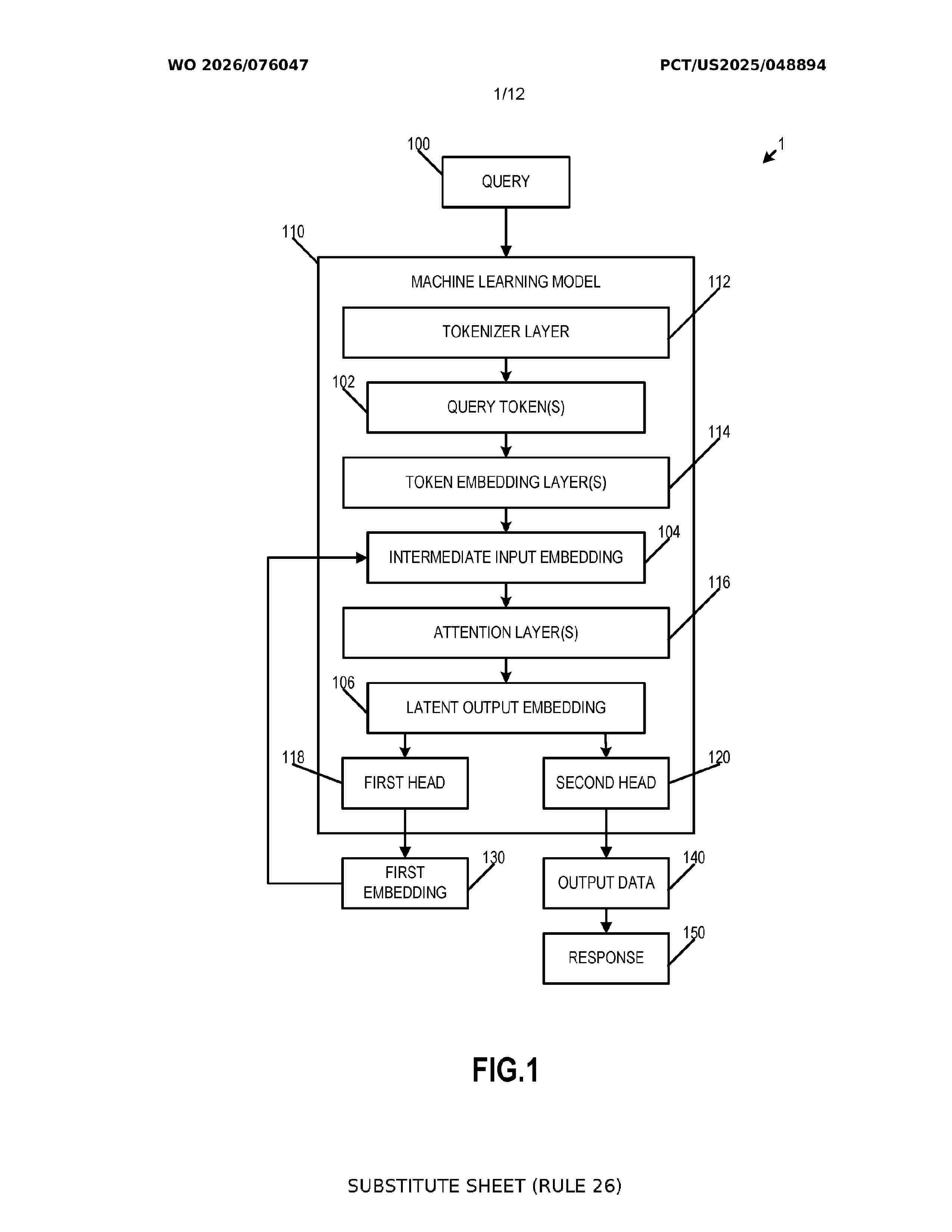
Resumen de: WO2026076047A1
A computer-implemented method for generating a response to a query. The method comprises receiving one or more query tokens, the one or more query tokens indicative of the query, providing the one or more query tokens as input to a machine learning model, outputting, from a first head of the machine learning model, a first embedding based upon the one or more query tokens, generating an intermediate input embedding based upon the one or more query tokens and the first embedding, outputting, from a second head of the machine learning model, output data based upon the intermediate input embedding, and generating the response to the query based upon the output data.
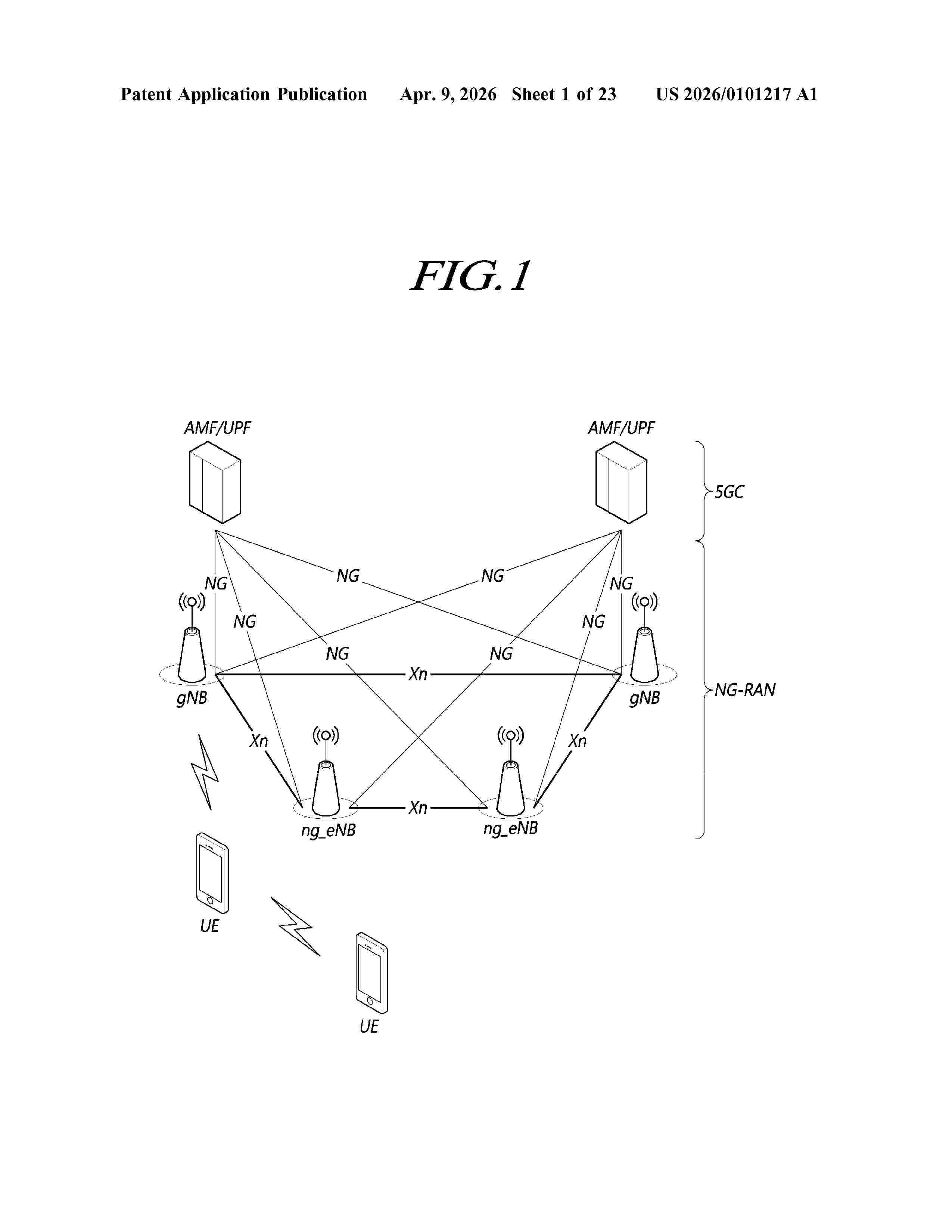
Resumen de: US20260101217A1
0000 Provided are a method and apparatus for monitoring a model in beam management by using artificial intelligence and machine learning. The method may include: in relation to a reference signal configured for a terminal, receiving second reference signal resource set configuration information of the reference signal for monitoring an AI/ML model; on the basis of the second reference signal resource set configuration information, measuring signal strength or signal quality for the reference signal; and reporting the performance result of the AI/ML model by comparing a measured value of the reference signal with a predicted value of the reference signal inferred via the AI/ML model.
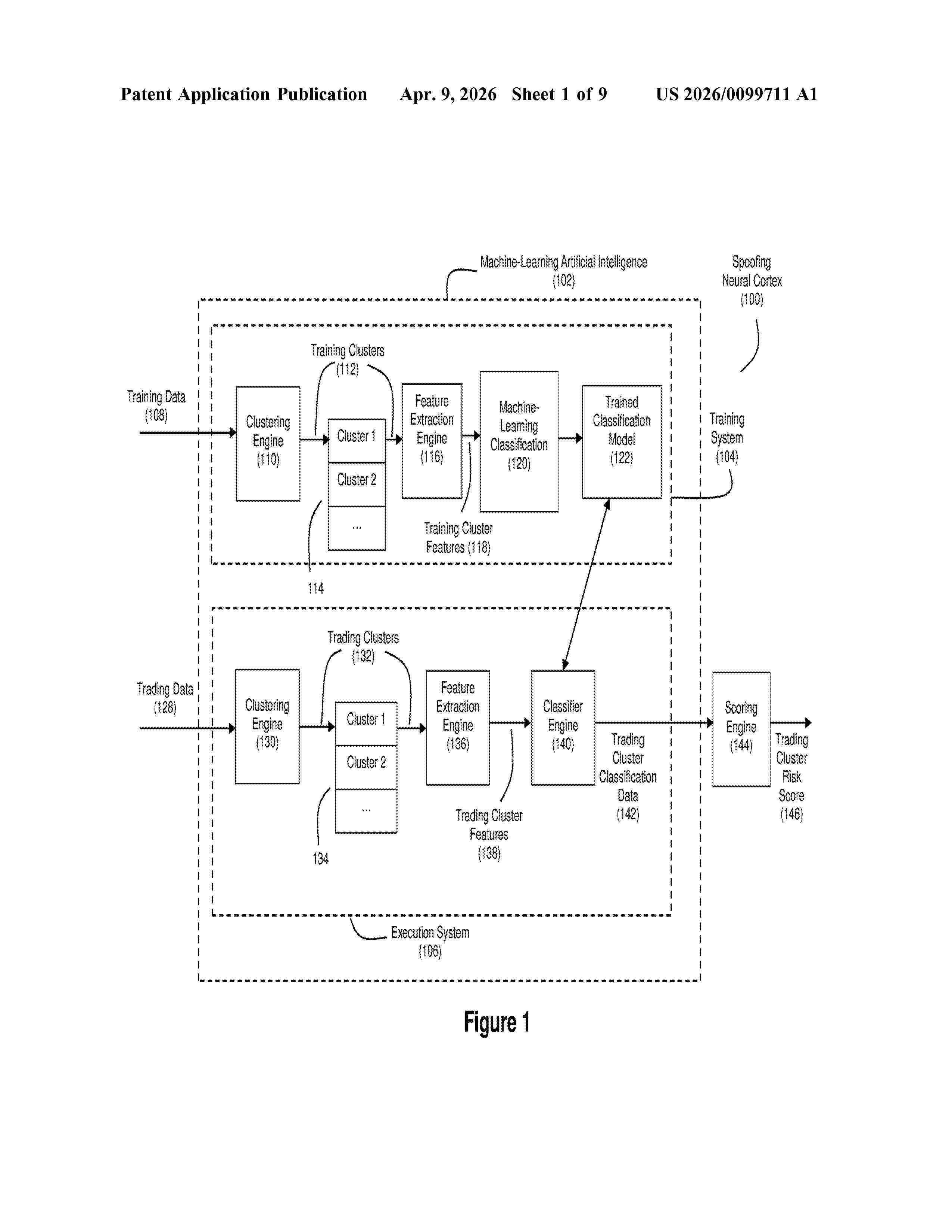
Resumen de: US20260099711A1
Various techniques are described for using machine-learning artificial intelligence to improve how trading data can be processed to detect improper trading behaviors such as trade spoofing. In an example embodiment, semi-supervised machine learning is applied to positively labeled and unlabeled training data to develop a classification model that distinguishes between trading behavior likely to qualify as trade spoofing and trading behavior not likely to qualify as trade spoofing. Also, clustering techniques can be employed to segment larger sets of training data and trading data into bursts of trading activities that are to be assessed for potential trade spoofing status.
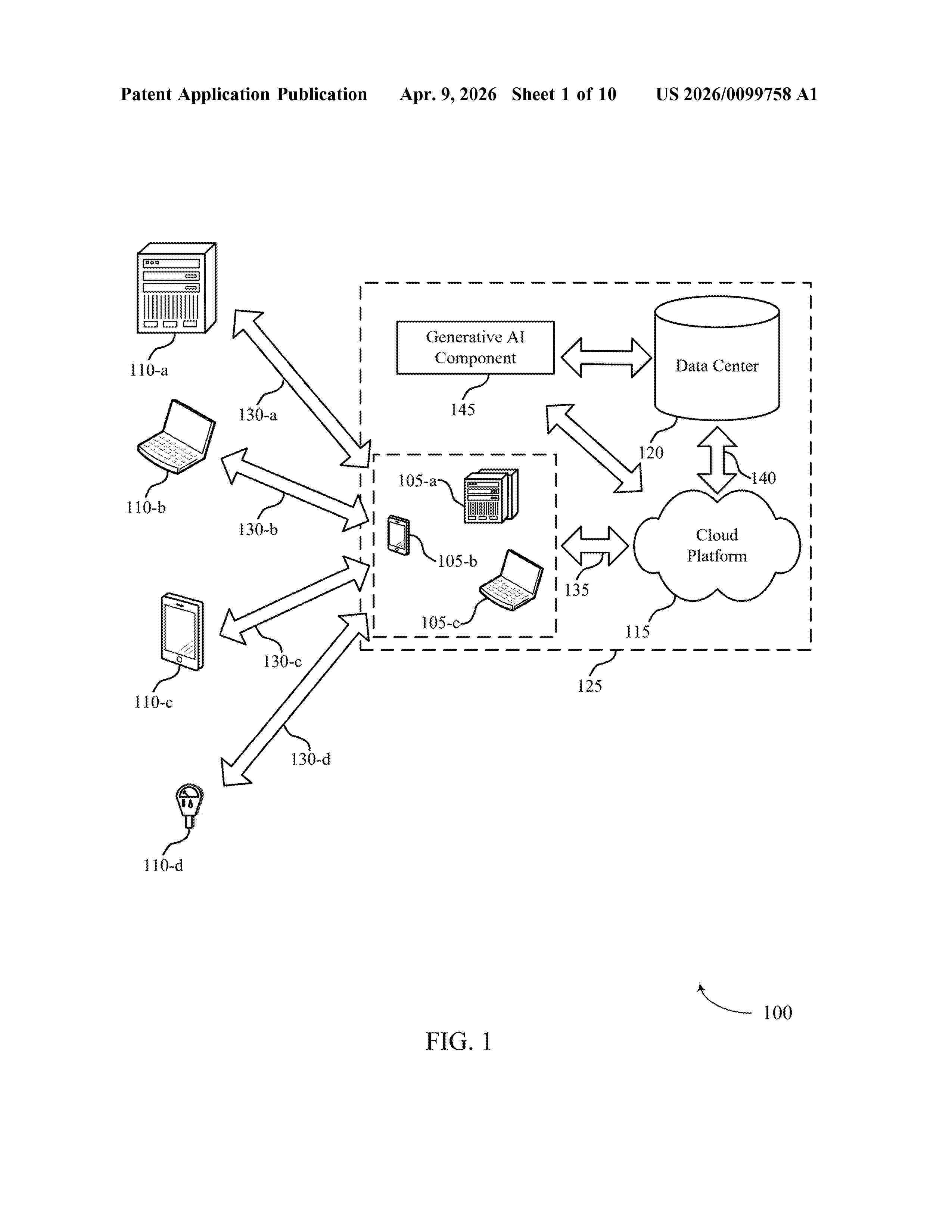
Resumen de: US20260099758A1
0000 An application server may receive a request to train the machine learning model on a dataset, and may generate a first set of randomized solutions based on inputting one or more of a set of model parameters into the machine learning model, where the first set of randomized solutions correspond to a set of outputs generated by the machine learning model and spans at least a subset of a set of local minimums. The application server may then select a first solution from the first set of randomized solutions and generate a second set of randomized solutions based on the first solution and inputting one or more of the set of model parameters into the machine learning model. The application server may then determine that the second set of randomized solutions includes a global minimum of the dataset based on the second set of randomized solutions satisfying a threshold.
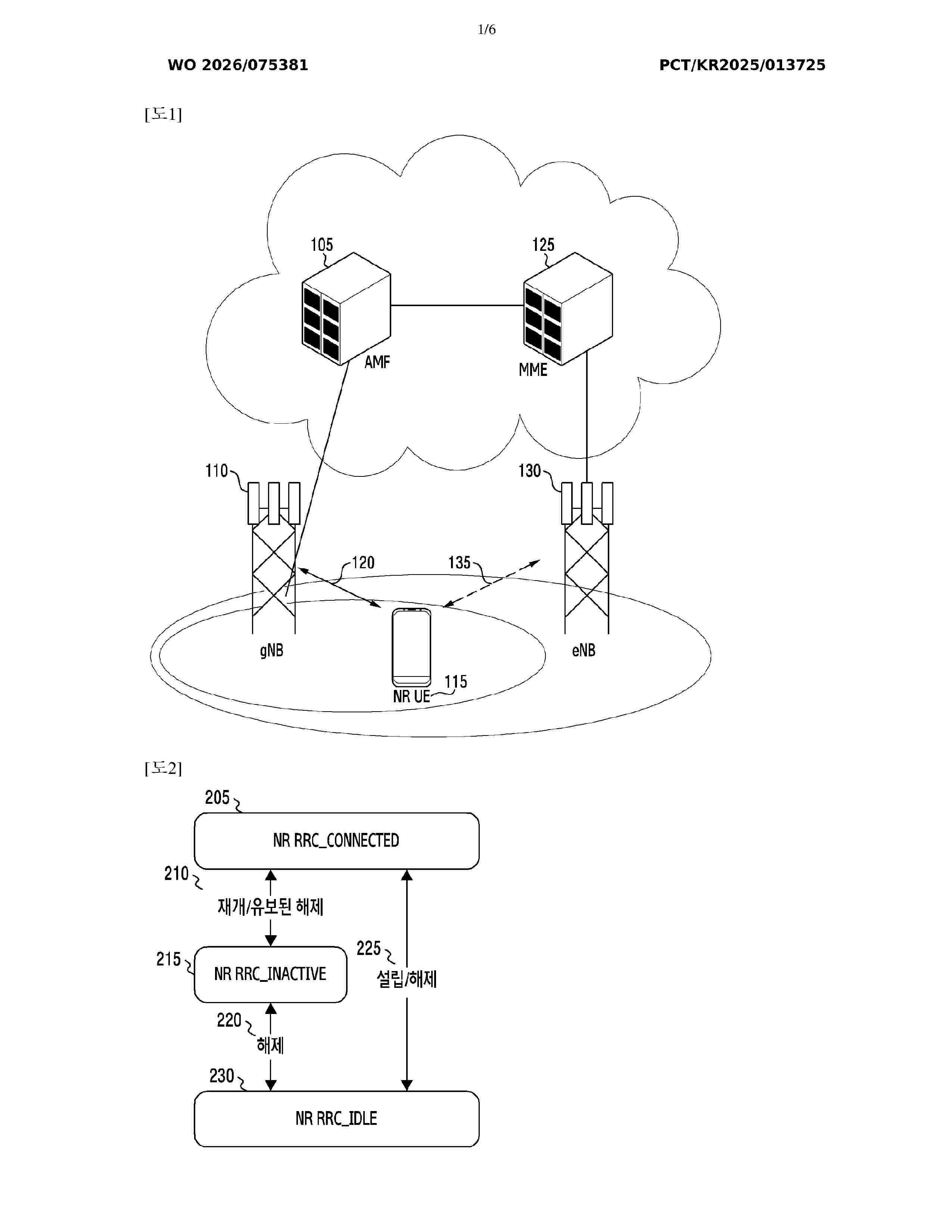
Resumen de: WO2026075381A1
The present disclosure relates to a 5G or 6G communication system for supporting a higher data transmission rate. A method performed by a first user equipment (UE) in a wireless communication system, according to various embodiments of the present disclosure, may comprise the steps of: receiving, from a second base station, an artificial intelligence (AI) model on the basis of first network-side training information associated with a first base station; receiving, from the second base station, second network-side training information associated with the second base station; when the first network-side training information corresponds to the second network-side training information, transmitting, to the second base station, information indicating that the AI model is applicable; and receiving, from the second base station, information for configuring inference using the AI model.
Resumen de: US20260099756A1
0000 Various methods and processes, apparatuses/systems, and media for generating recourse data with data-driven actionability constraints for a negatively classified individual are disclosed. A processor trains a machine learning model by using a first set of training data and a second set of training data which outputs risk classification data associated with a negative decision; identifies, based on the risk classification data, a negatively classified individual who received the negative decision; applies a feature attribution algorithm to the trained model; ranks, in response to applying the feature attribution algorithm, a list of features that explain a negative classification for the negatively classified individual; filters the list of features that explain the negative classification for each negatively classified individual by utilizing computed actionability labels (i.e., “likely to improve,” unlikely to improve”) for all features; and outputs advice statements based on significant and actionable (likely to improve) features.
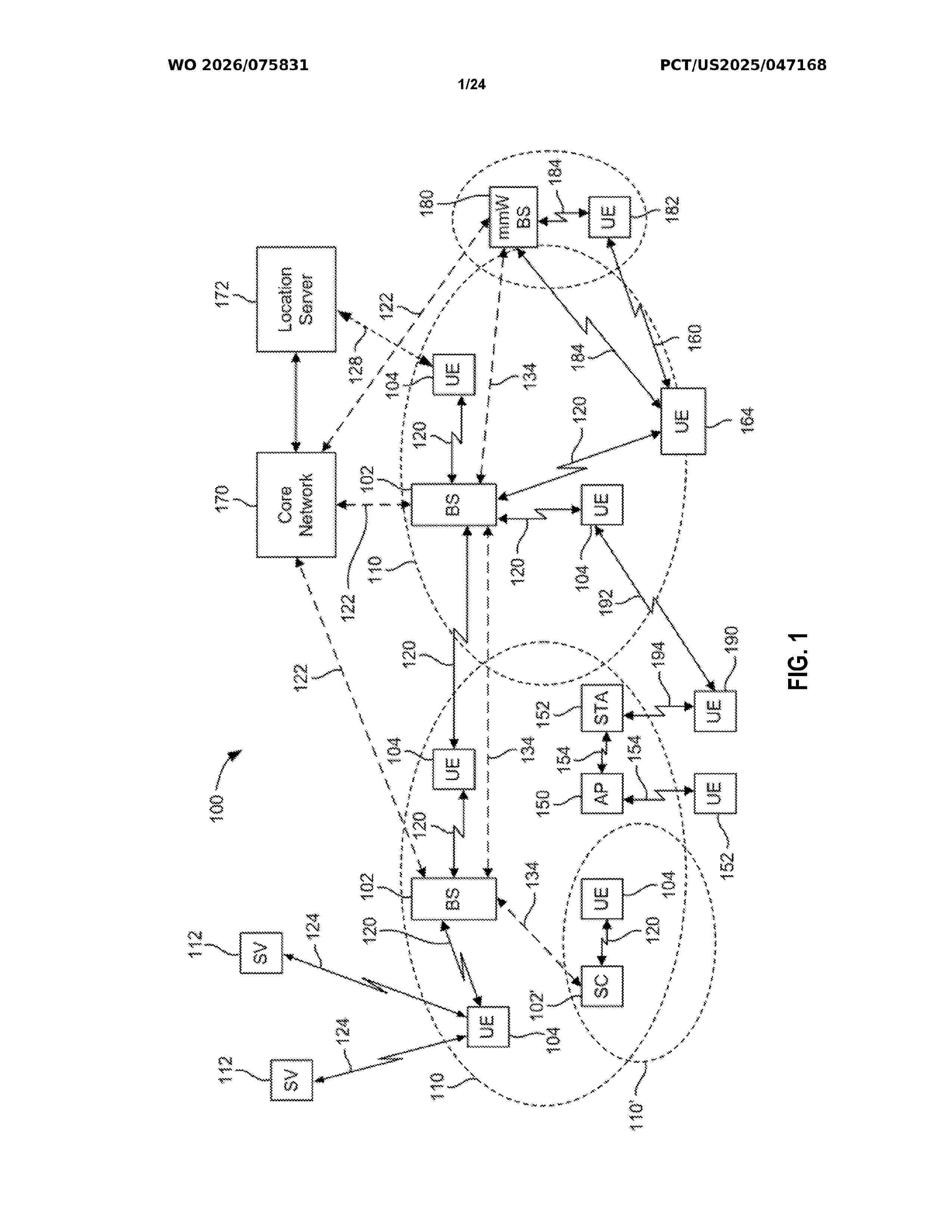
Resumen de: WO2026075831A1
A method comprises determining, by a network entity, a device group of at least one selected wireless device, wherein the one or more selected wireless devices are a subset of available wireless devices in an environment; and configuring the one or more selected wireless devices to send measurement data generated by the one or more selected wireless devices to a consumer entity configured to use training examples to train a machine learning (ML) system to generate output data, the training examples being based on the measurement data, the measurement data comprising measurements of wireless signals received by the one or more selected wireless devices, the output data indicating physical positions of one or more User Equipment (UE) devices in the environment or the output data being input data to a process that determines the physical positions of the one or more UE devices.
Resumen de: EP1000000A1
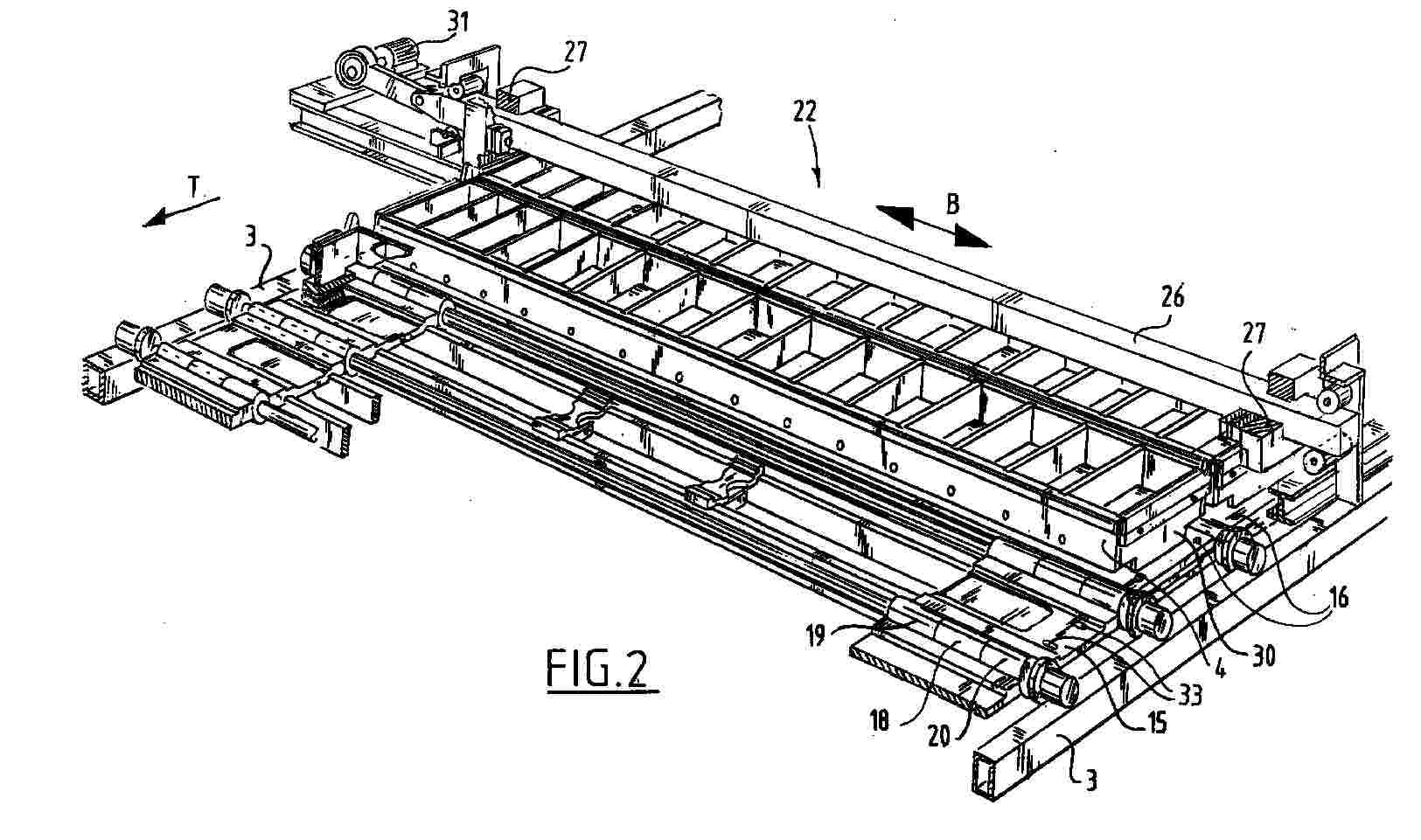
The invention relates to an apparatus (1) for manufacturing green bricks from clay for the brick manufacturing industry, comprising a circulating conveyor (3) carrying mould containers combined to mould container parts (4), a reservoir (5) for clay arranged above the mould containers, means for carrying clay out of the reservoir (5) into the mould containers, means (9) for pressing and trimming clay in the mould containers, means (11) for supplying and placing take-off plates for the green bricks (13) and means for discharging green bricks released from the mould containers, characterized in that the apparatus further comprises means (22) for moving the mould container parts (4) filled with green bricks such that a protruding edge is formed on at least one side of the green bricks.
Resumen de: EP1000000A1
The invention relates to an apparatus (1) for manufacturing green bricks from clay for the brick manufacturing industry, comprising a circulating conveyor (3) carrying mould containers combined to mould container parts (4), a reservoir (5) for clay arranged above the mould containers, means for carrying clay out of the reservoir (5) into the mould containers, means (9) for pressing and trimming clay in the mould containers, means (11) for supplying and placing take-off plates for the green bricks (13) and means for discharging green bricks released from the mould containers, characterized in that the apparatus further comprises means (22) for moving the mould container parts (4) filled with green bricks such that a protruding edge is formed on at least one side of the green bricks.
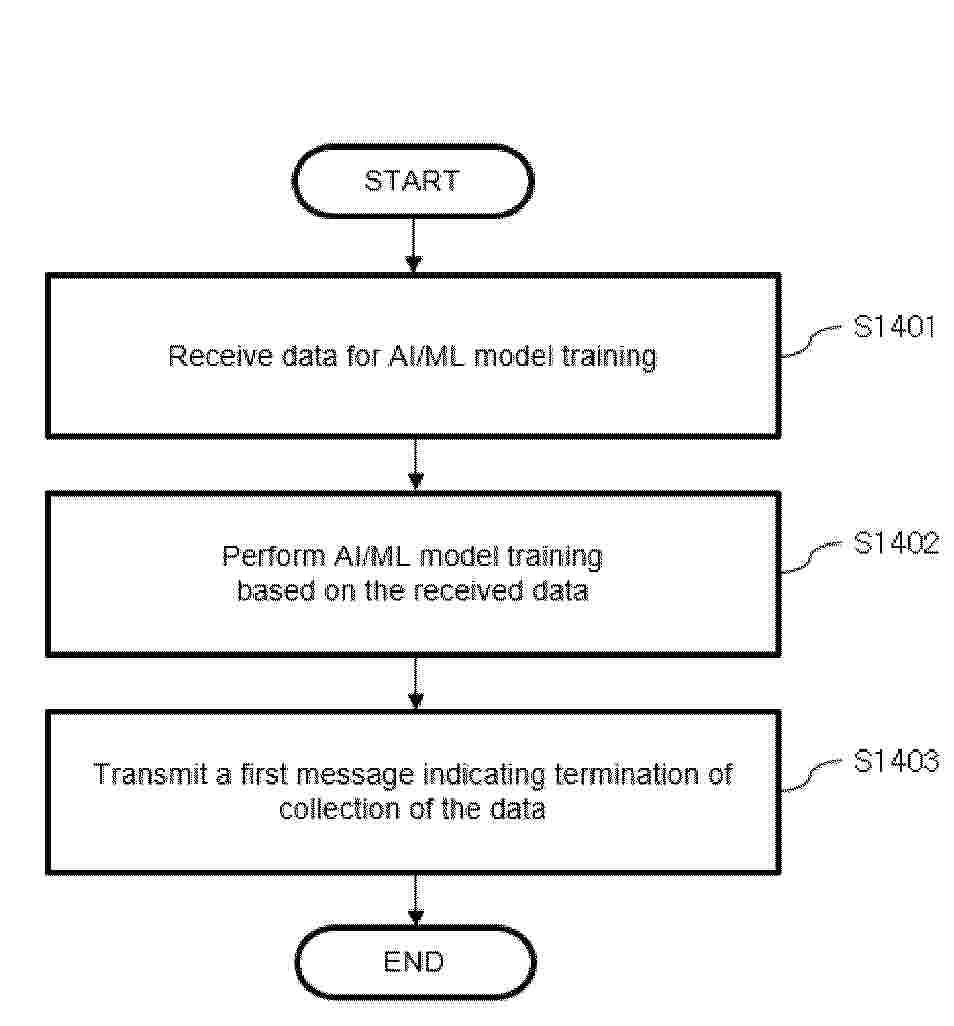
Resumen de: EP4723506A1
Provided are a method and apparatus for training a model for artificial intelligence and/or machine learning (AI/ML)-based communication. A terminal receives, from a base station, data for AI/ML model training, and performs AI/ML model training based on the received data. After performing the AI/ML model training, the terminal transmits, to the base station, a first message indicating termination of collection of the data.
Nº publicación: WO2026072270A1 02/04/2026
Solicitante:
LIVERAMP INC [US]
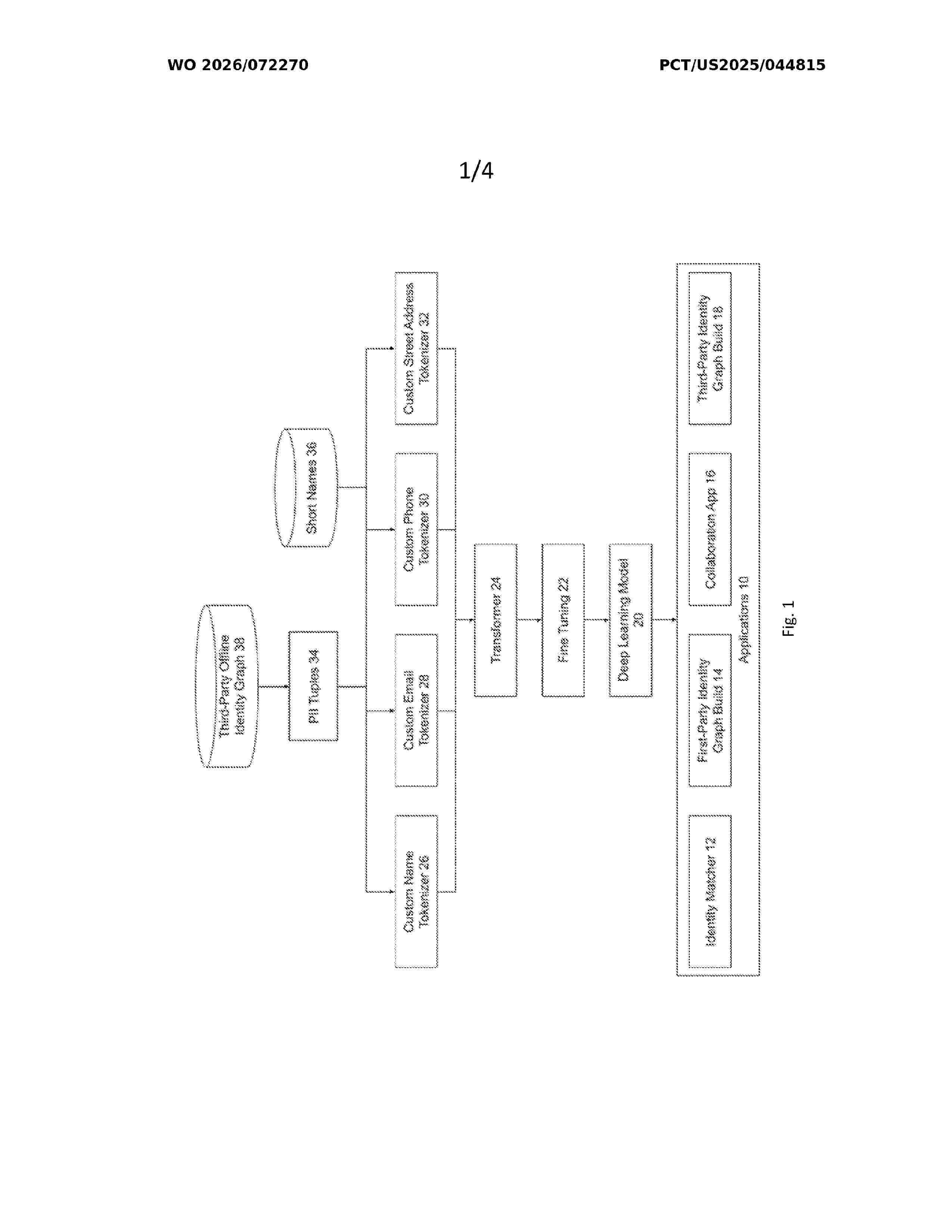
Resumen de: WO2026072270A1
A system and method for privacy-preserving identity resolution using deep learning enables accurate matching of personally identifiable information (PH) while maintaining data security. The system employs a deep learning model trained with transformer architecture and contrastive learning on third-party identity graph data. Custom tokenizers process data by leveraging hierarchical structures and domain-specific characteristics. The trained model generates vector embeddings that enable fuzzy matching, accounting for variations in spellings, typographical errors, and data inconsistencies. A vector database stores embeddings for nearest neighbor searches to identify potential identity matches. The system enables identity resolution without requiring Pll data movement from first-party environments. The invention facilitates building accurate first-party identity graphs and enables secure collaboration between parties without exposing underlying Pll data.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica