Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 104
resultados
104
resultados
 Última actualización
27/06/2026 [07:03:00]
Última actualización
27/06/2026 [07:03:00]



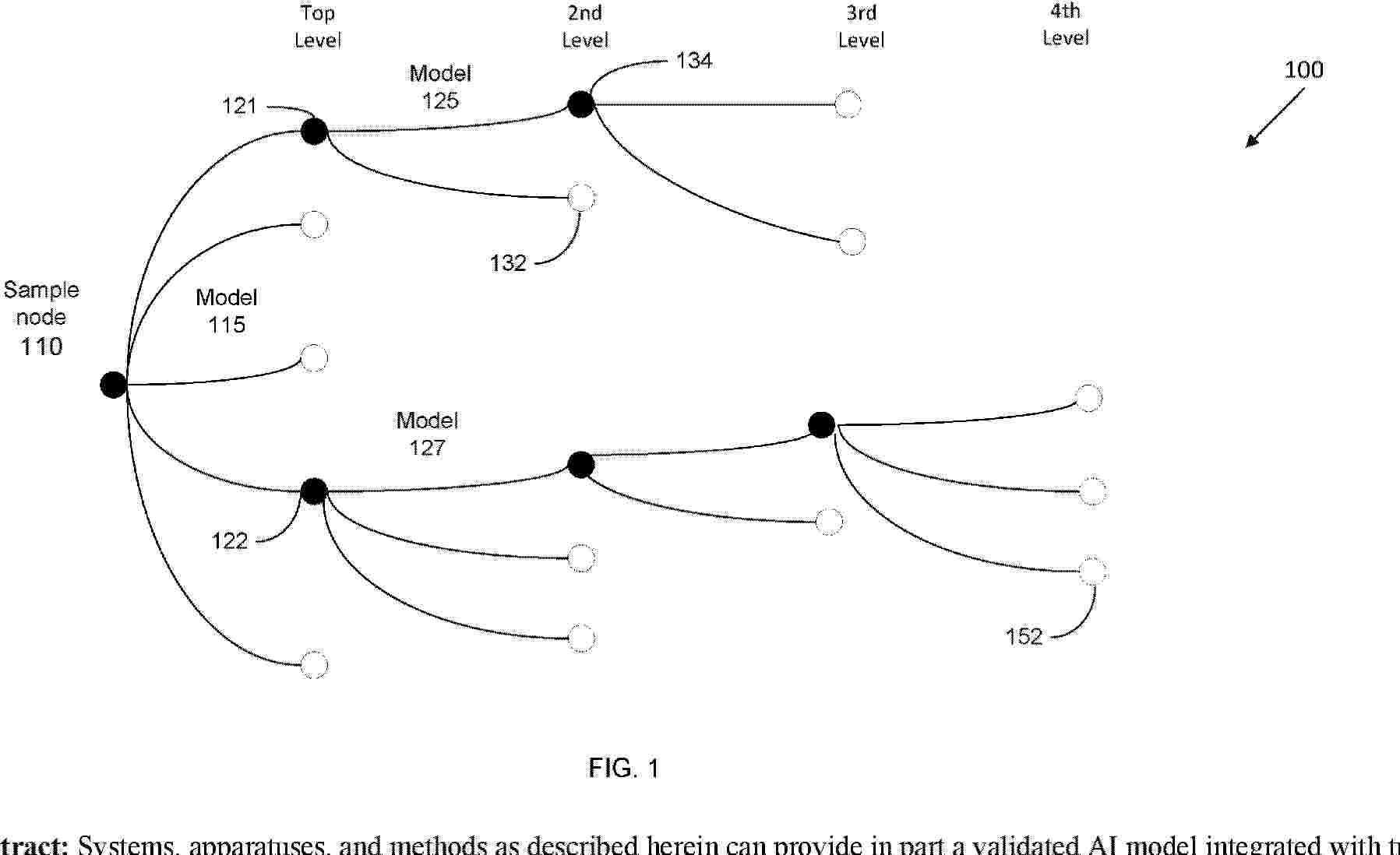
Resumen de: AU2024408349A1
Systems, apparatuses, and methods as described herein can provide in part a validated AI model integrated with tumor profiling that enhances diagnostic accuracy, including resolution of CUP cases, and prompts clinically relevant therapeutic recommendation changes without requiring additional specimen. Machine learning models in a hierarchal sample type tree can be used, e.g., to determine a tumor type of a cancer.

Resumen de: US20260181002A1
The present disclosure relates to systems and methods for determining anomalies using machine learning models. In examples, systems can be configured to receive network operation data representing a plurality of network operations. The system can classify a subset of the network operations as comprising an anomaly using an isolation forest model. The system can then determine, for each network operation of the subset of network operations, that the anomaly is a positive anomaly, a negative anomaly, or noise. In some examples, the systems can be configured to generate a graphical user interface (GUI) comprising a warning message, the warning message identifying at least one network operation of the subset of network operations as being a negative anomaly.
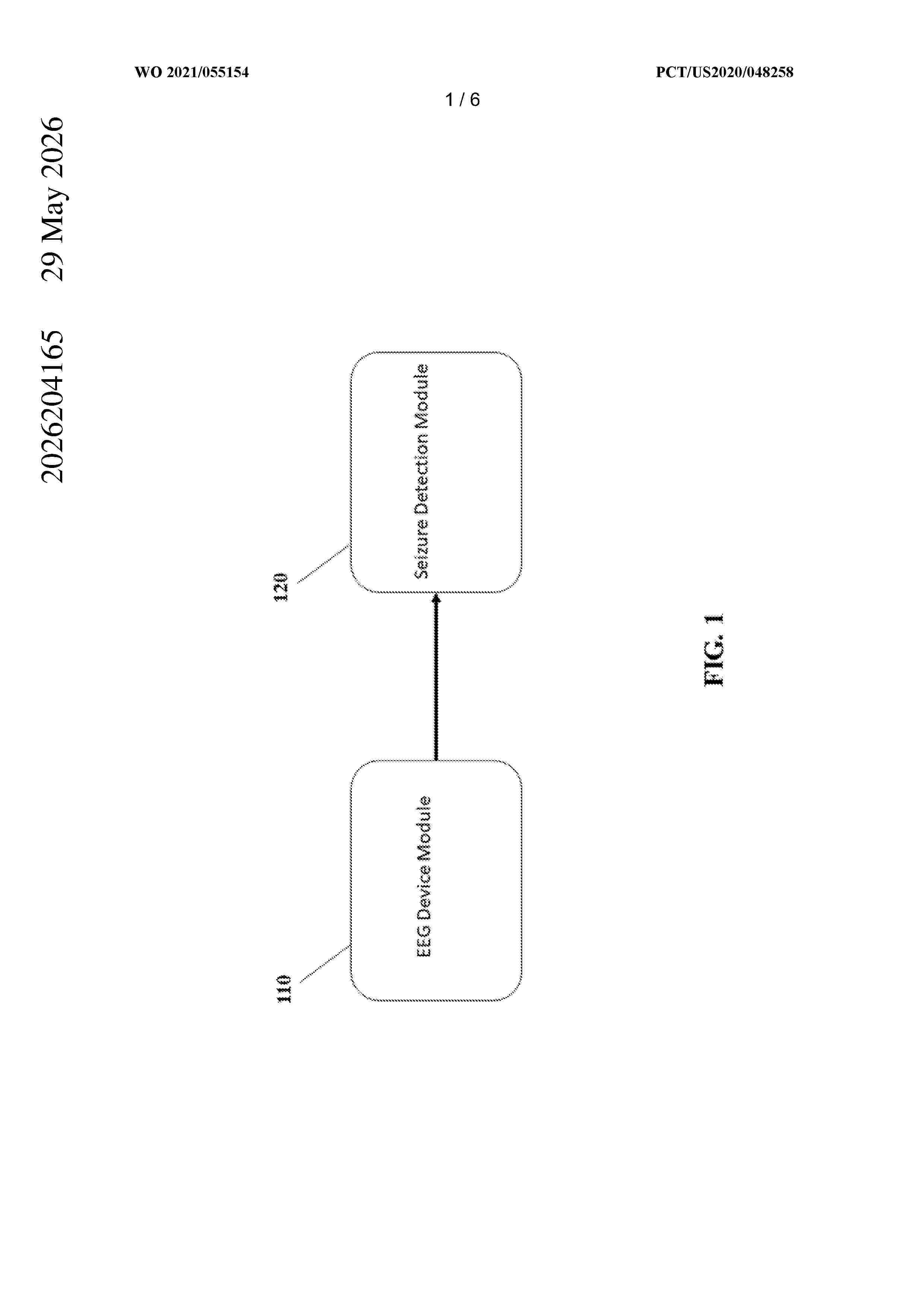
Resumen de: AU2026204165A1
Abstract The present disclosure provides systems and methods for seizure detection. The method for seizure detection may include receiving a plurality of electroencephalography (EEG) signals over a plurality of channels for a subject, preprocessing the plurality of EEG signals by segmenting the plurality of EEG signals for each channel into a plurality of temporal data segments, extracting a plurality of features from each temporal data segment for each channel, and applying a machine learning algorithm to the plurality of features to perform a seizure binary classification for each temporal data segment for each channel. A control policy may be employed to determine a seizure burden on the aggregated seizure binary classifications. When the seizure burden is equal to or exceeds a threshold, a notification may be generated. The notification may be usable by a healthcare practitioner to assess whether the subject may be at risk of having a seizure. Abstract wo 2021/055154 EEG Device Module Seizure Detection Module PCT/US2020/048258 ay a y w o EEG Device Module Seizure Detection Module
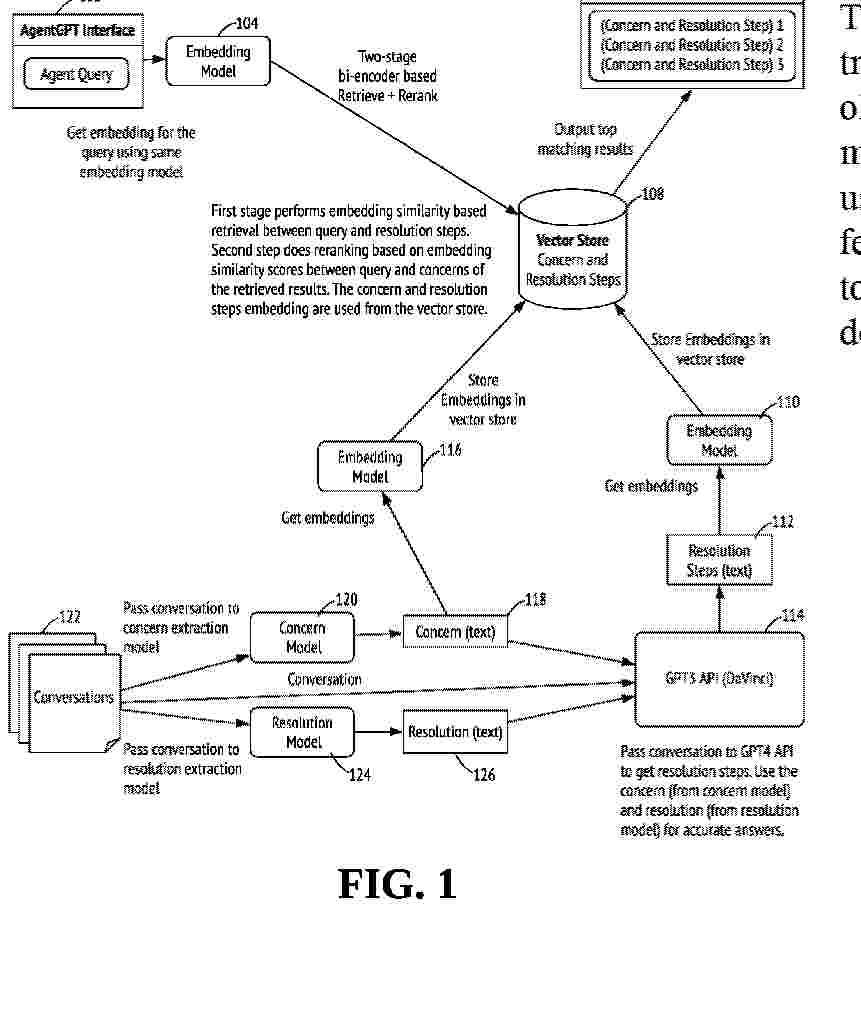
Resumen de: AU2024376764A1
Transformer-based agent assistant systems as machine learning-based customer service tools that analyze past customer-agent conversations to build a knowledge base of problem-resolution steps are disclosed. The system may include a natural language processing (NLP) model and a transfomer-based model to extract and generate customer concerns and resolutions. One embodiment also includes a head-topic and subtopic detection module for identifying trends in customer concerns. Another embodiment uses a question-answering model and a zero-shot-NLI (natural language inference) classifier for entity extraction and detection. The system is designed to be flexible, incorporating new data over time, and can retrieve company documentation or FAQs for the agent based on cosine similarity.
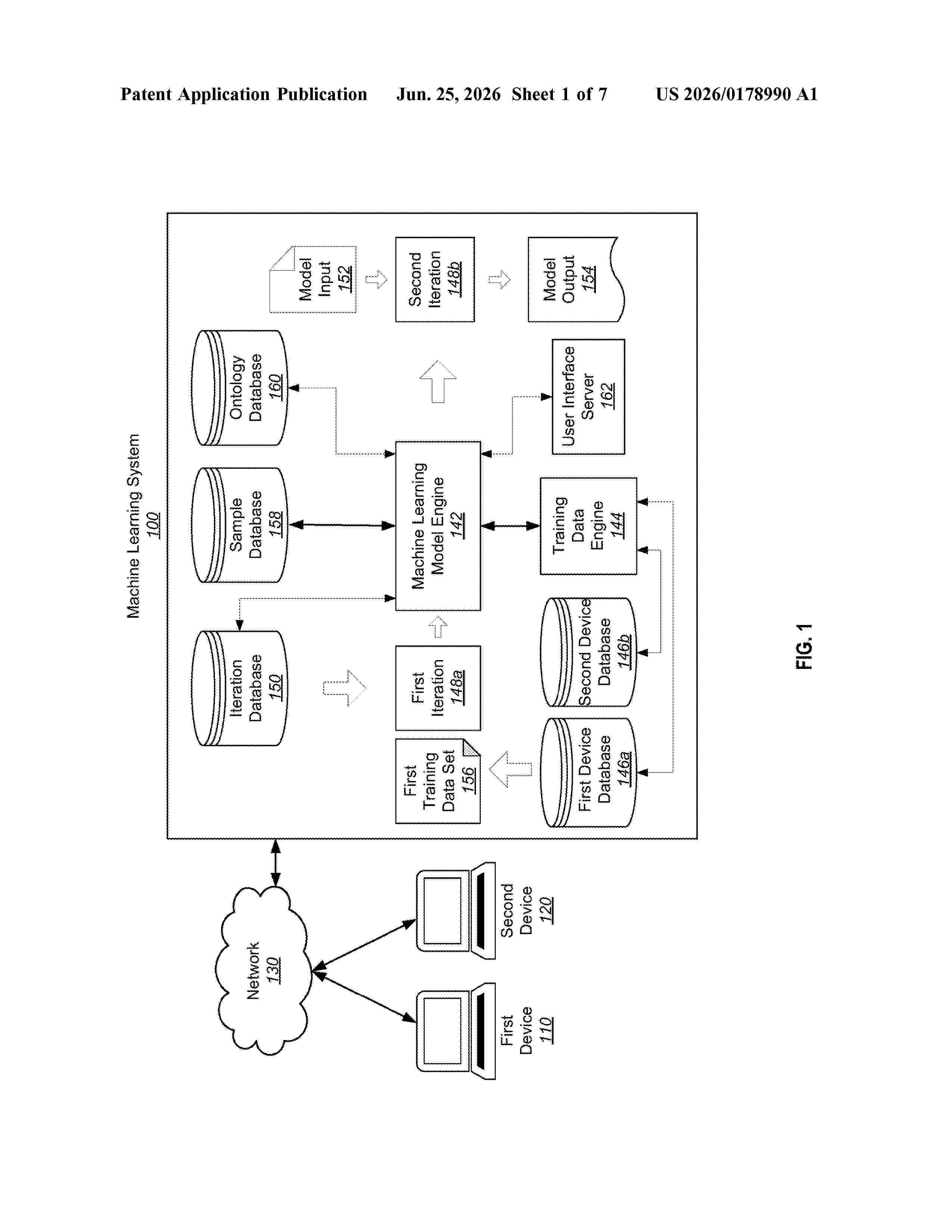
Resumen de: US20260178990A1
A method performed by a machine learning system that involves obtaining a first ontology that includes one or more labels. Each label is associated with a sample that includes text. The ML system is configured to use a particular label to retrieve one or more samples associated with the particular label. The method further involves receiving an identification of a label of a first ontology associated with a first machine learning model to share with a second ontology associated with a second machine learning model and sharing the label and the information with the second ontology. The method further involves training the second machine learning model using the shared information associated with the label.
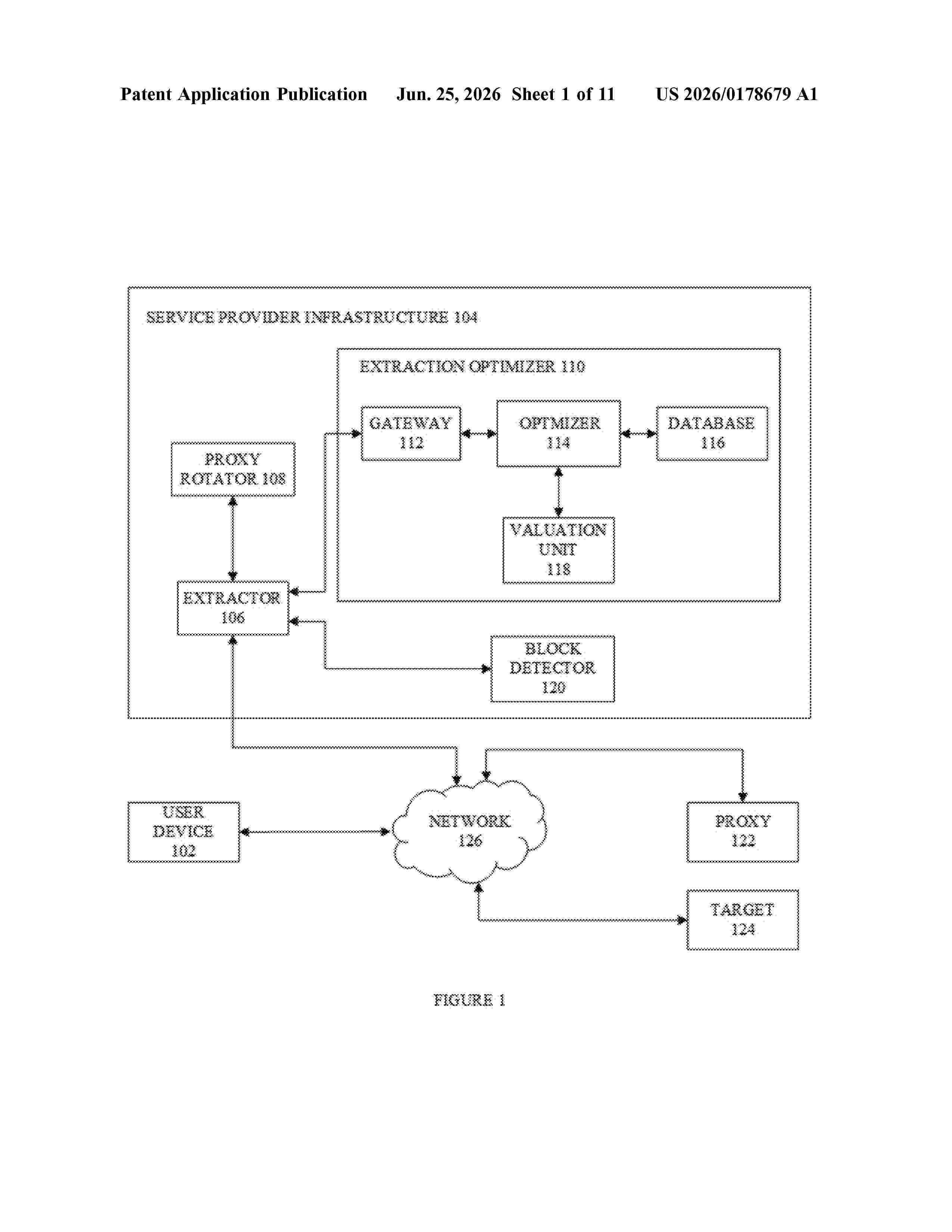
Resumen de: US20260178679A1
Systems and methods to intelligently optimize data collection requests are disclosed. In one embodiment, systems are configured to identify and select a complete set of suitable parameters to execute the data collection requests. In another embodiment, systems are configured to identify and select a partial set of suitable parameters to execute the data collection requests. The present embodiments can implement machine learning algorithms to identify and select the suitable parameters according to the nature of the data collection requests and the targets. Moreover, the embodiments provide systems and methods to generate feedback data based upon the effectiveness of the data collection parameters. Furthermore, the embodiments provide systems and methods to score the set of suitable parameters based on the feedback data and the overall cost, which are then stored in an internal database.
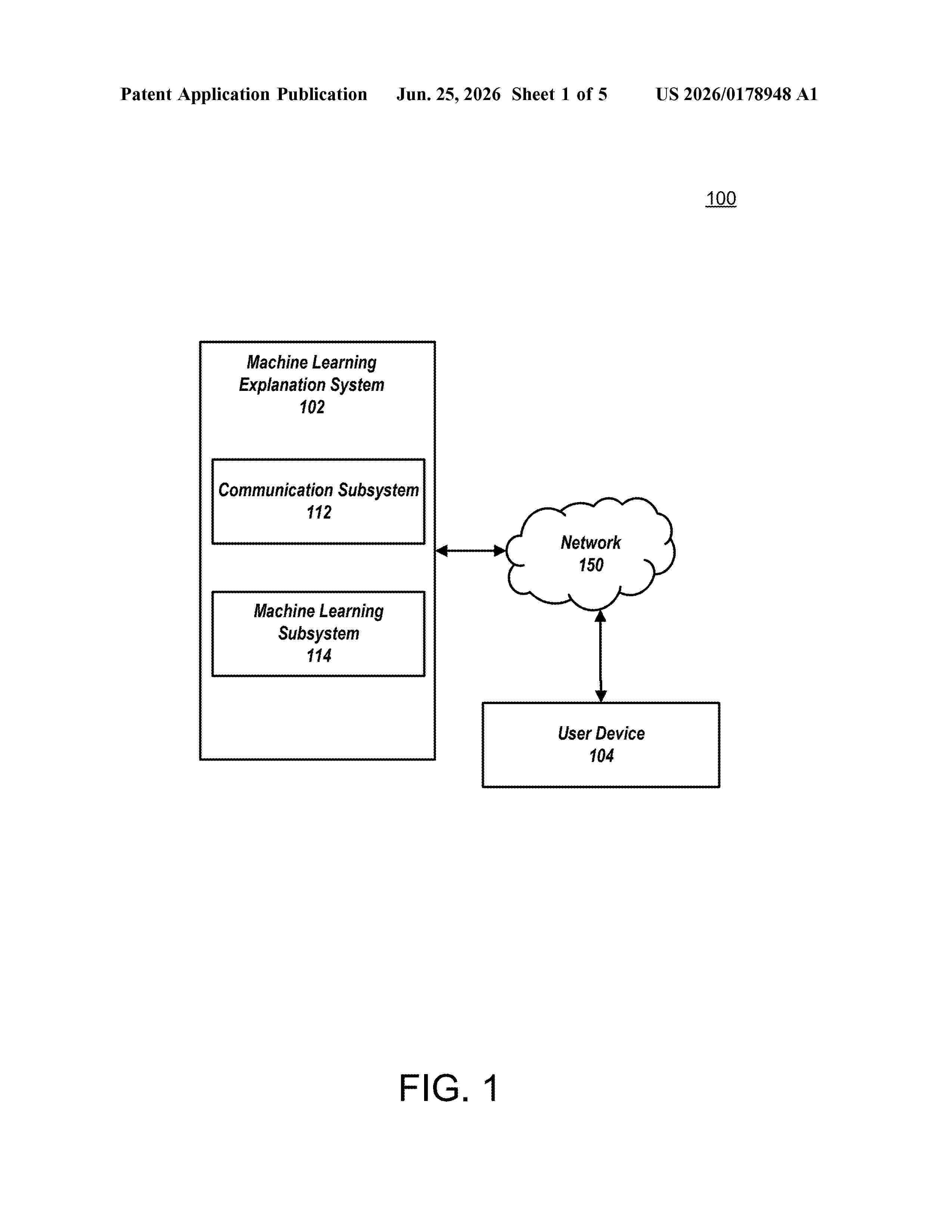
Resumen de: US20260178948A1
In some embodiments, a computing system may generate a first set of importance metrics (e.g., scores or values) for a model. The importance metrics may be generated using an explainable artificial intelligence technique, and an individual importance metric may indicate how influential a corresponding feature is for a decision made by a model. The computing system may determine an important feature and create a modified dataset by removing the important feature from the dataset. The computing system may train the model on the modified dataset and evaluate the performance of the model to determine the effect of removing the feature (e.g., which may indicate how important the feature is to output generated by the model). This process may be repeated for additional features and additional performance metrics may be obtained.
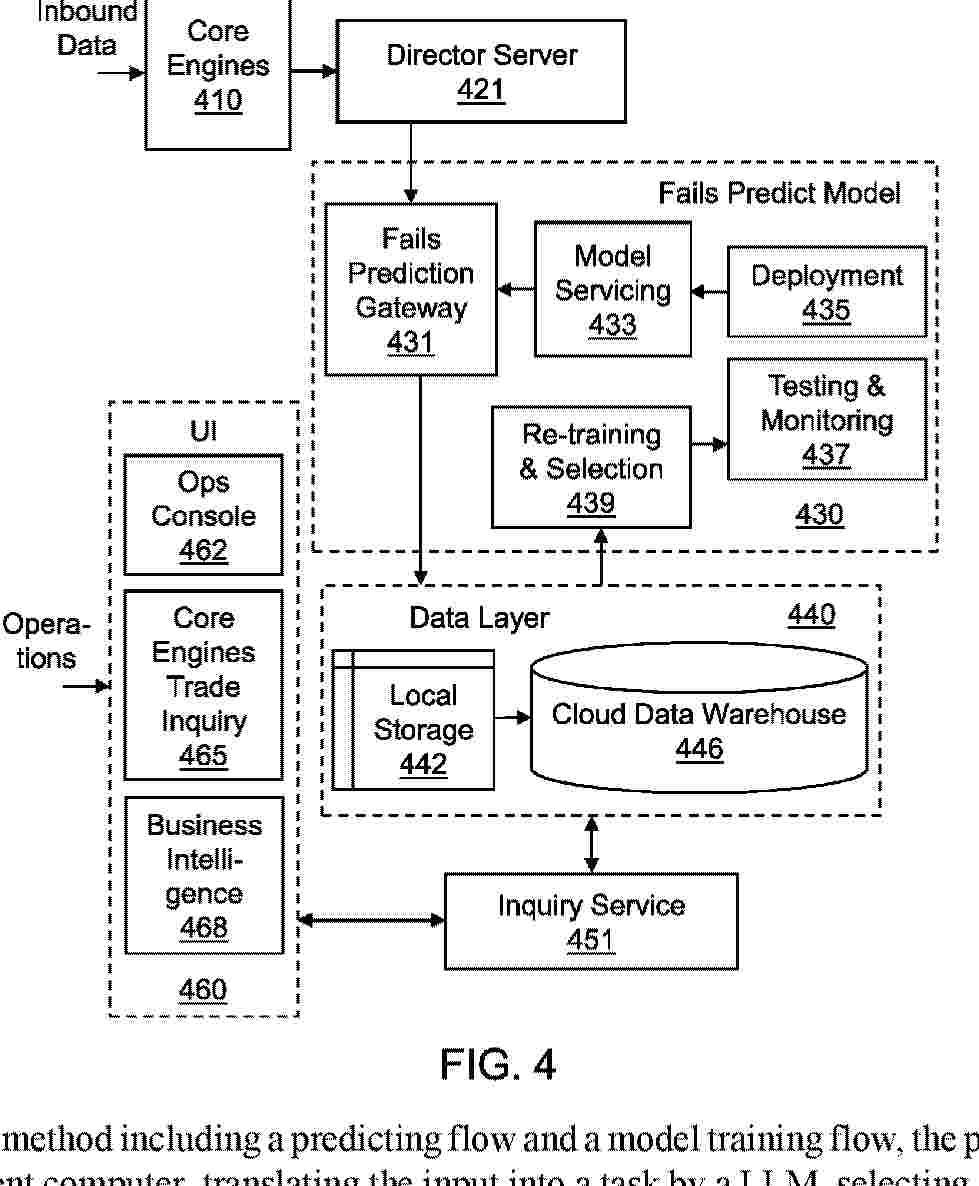
Resumen de: AU2024393160A1
A failure prediction method including a predicting flow and a model training flow, the predicting flow including receiving a natural language input from a client computer, translating the input into a task by a LLM, selecting a ML model dedicated to the task, receiving first data, converting the first data to second data of a predetermined format, immediately applying, the ML model on the second data for predicting an output and providing a corresponding explanation, storing the second data and the output into historical data in a storage layer, translating the output and the explanation into a prediction in the natural language by the LLM, and transmitting the prediction to the client computer and iterating the predicting flow for a predetermined number of time; and the model training flow including retrieving the historical data from the storage layer, and training the ML model on the historical data.
Resumen de: EP4764452A1
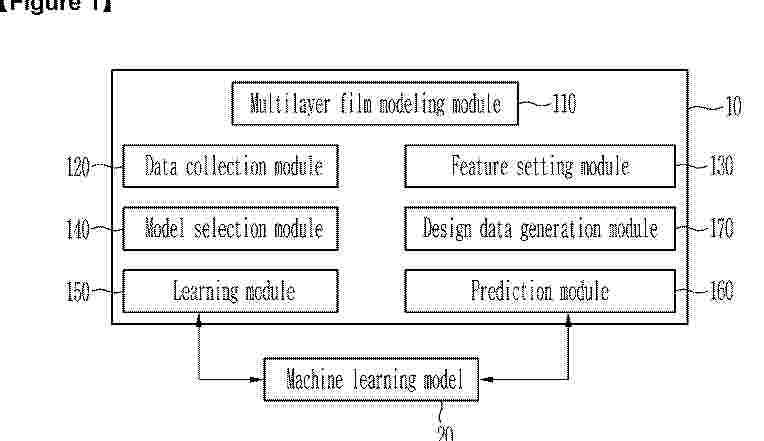
0001 An apparatus and method for designing a multilayer film is disclosed. An apparatus for designing a multilayer film may perform: modeling a lamination structure of a multilayer film to be designed, collecting stress-strain data with respect to the single-layer film forming the lamination structure, reading a value pre-stored in a storage space accessible by an apparatus for designing a multilayer film, and obtaining a feature setting mode for designating different feature setting manners depending on the read value, calculating a strain energy from a plurality of physical indicators selected from the stress-strain data, depending on the feature setting mode, and setting the strain energy as the feature, selecting at least one among a plurality of supervised learning models capable of a regression analysis as a machine learning model, predicting the dart impact strength of the multilayer film by using the machine learning model learned by taking the feature as an independent variable, and a dart impact strength of the multilayer film as a target variable, and generating design data for the multilayer film, by combining predicted values for other properties and a predicted value of the dart impact strength, so as to satisfy the design requirements of the multilayer film.
Resumen de: EP4765027A2
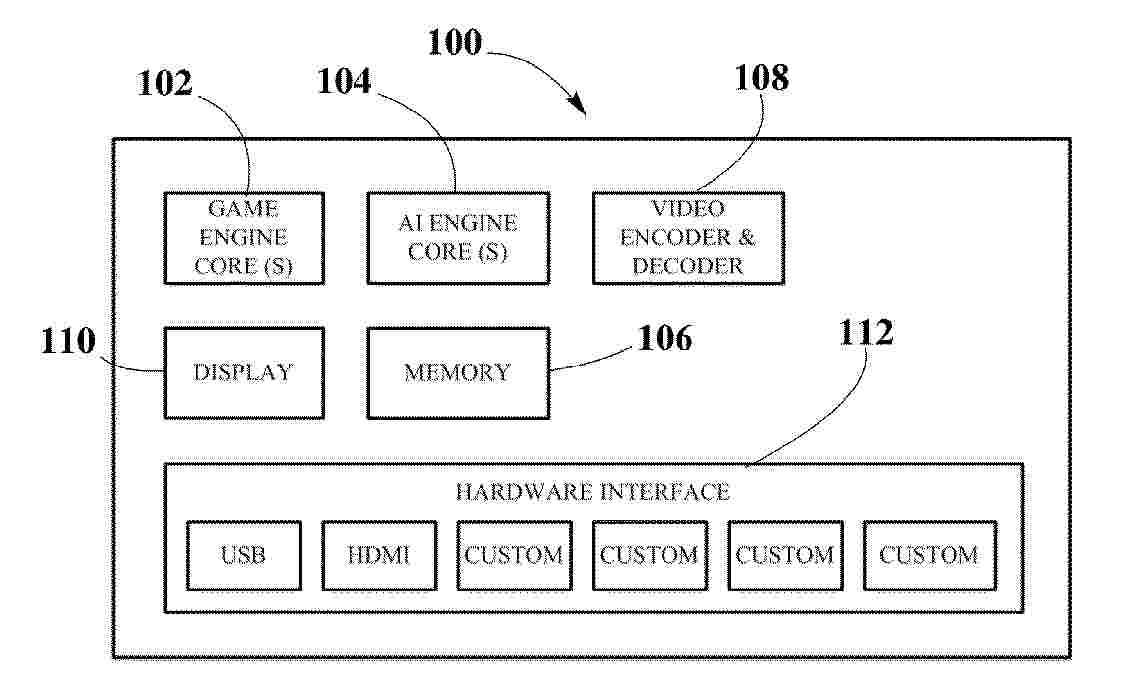
An electronic chip, a chip assembly, a computing device, and a method are described. The electronic chip comprises a plurality of processing cores and at least one hardware interface coupled to at least one of the one or more processing cores. At least one processing core implements a game engine and/or a simulation engine and at least one or more processing cores implements an artificial intelligence engine, whereby implementations are on-chip implementations in hardware by dedicated electronic circuitry. The at least one or more game and/or simulation engines performs tasks on sensory, generating data sets that are processed through machine learning algorithms by the hardwired artificial intelligence engine. The data sets processed by the hardwired artificial intelligence engine include at least contextual data and target data, wherein combining both data and processing by dedicated hardware results in enhanced machine learning processing.
Resumen de: EP4765001A1
0001 A machine learning based (ML-based) method and system for automatically extracting and correcting financial information from documents, is disclosed. Initially, the documents are obtained from data sources and pre-processed to generate the pre-processed data associated with contents within the document. The contents are classified as potential key-value pairs corresponding to the financial information based on the system prompts and extracted using the ML model. The potential key-value pairs are corrected to obtain the corrected key-value pairs based on custom prompts, using the ML model. The corrected key-value pairs corresponding to the financial information are provided as the output to the end users on user interfaces associated with an electronic device. This technique extracts financial information regardless of structure or alignment by learning to recognize any added or removed prefixes or suffixes, enabling the prefixes or suffixes to make corrections and generate accurate key-value pairs.
Resumen de: US20260169468A1
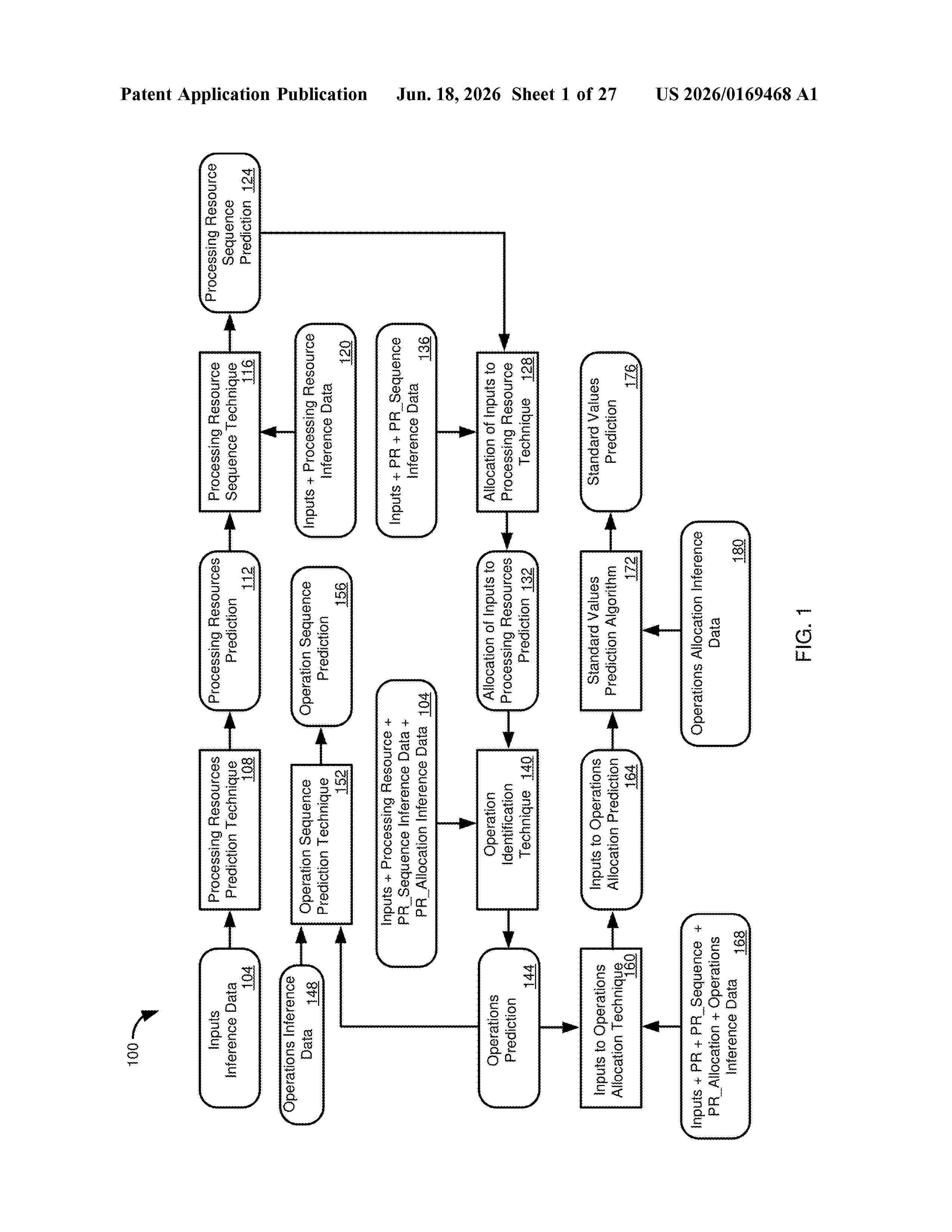
Techniques are provided for determining elements of a routing. A set of inputs is obtained, where respective inputs are associated with sets of one or more characteristics. Values for the characteristics are associated with a set of labels defining operational routing attributes and are used to train a machine learning model. Inference data including characteristic values for inputs is analyzed using the machine learning model to produce an inference result identifying predicted labels. The predicted labels are used to execute at least a portion of a routing operation including assignments of work centers, execution sequences, or resources. Updated inference data may result in different predicted labels and different routing assignments. Using characteristic values enables improved inference accuracy and allows a greater portion of available data to be used for training.
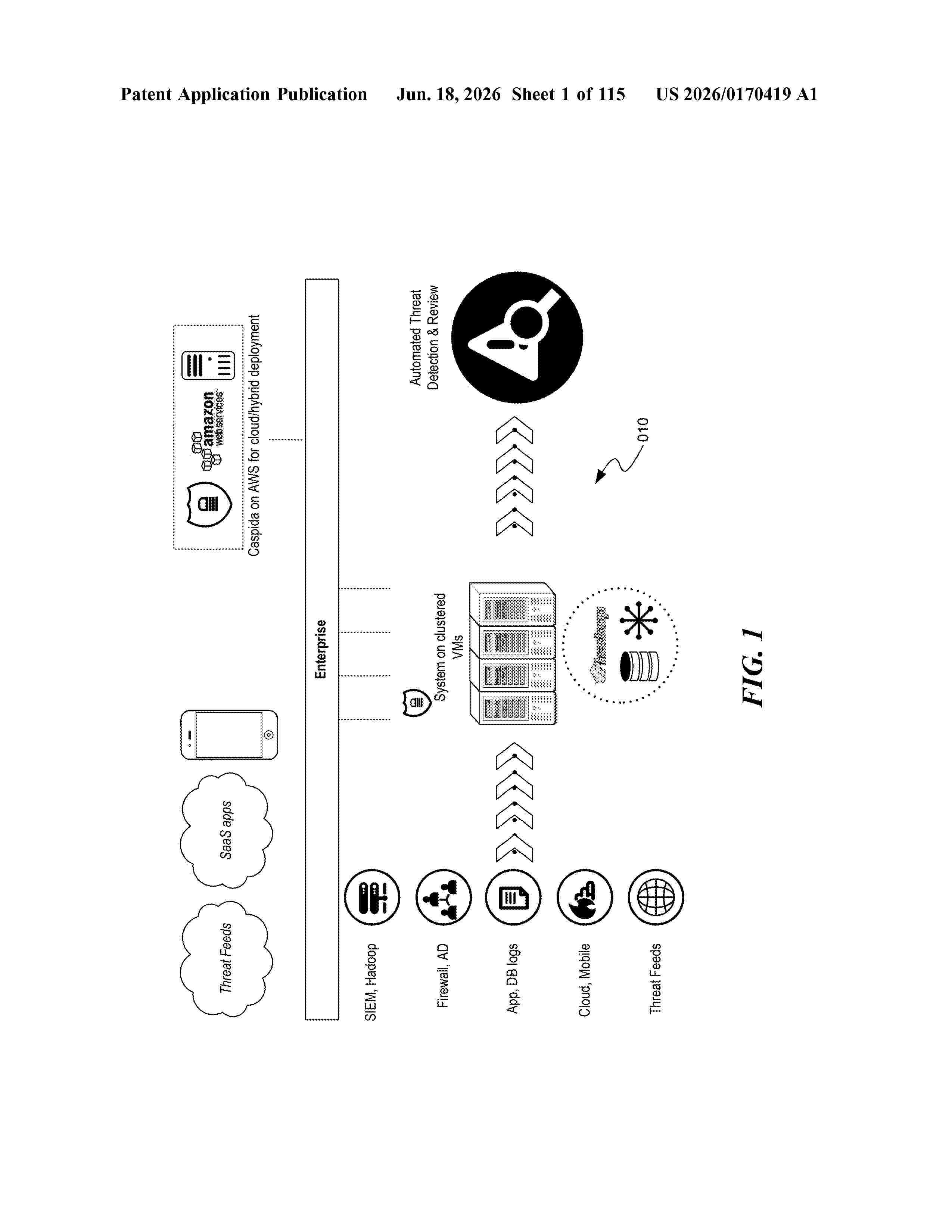
Resumen de: US20260170419A1
0000 A security platform employs a variety techniques and mechanisms to detect security related anomalies and threats in a computer network environment. The security platform is “big data” driven and employs machine learning to perform security analytics. The security platform performs user/entity behavioral analytics (UEBA) to detect the security related anomalies and threats, regardless of whether such anomalies/threats were previously known. The security platform can include both real-time and batch paths/modes for detecting anomalies and threats. By visually presenting analytical results scored with risk ratings and supporting evidence, the security platform enables network security administrators to respond to a detected anomaly or threat, and to take action promptly.
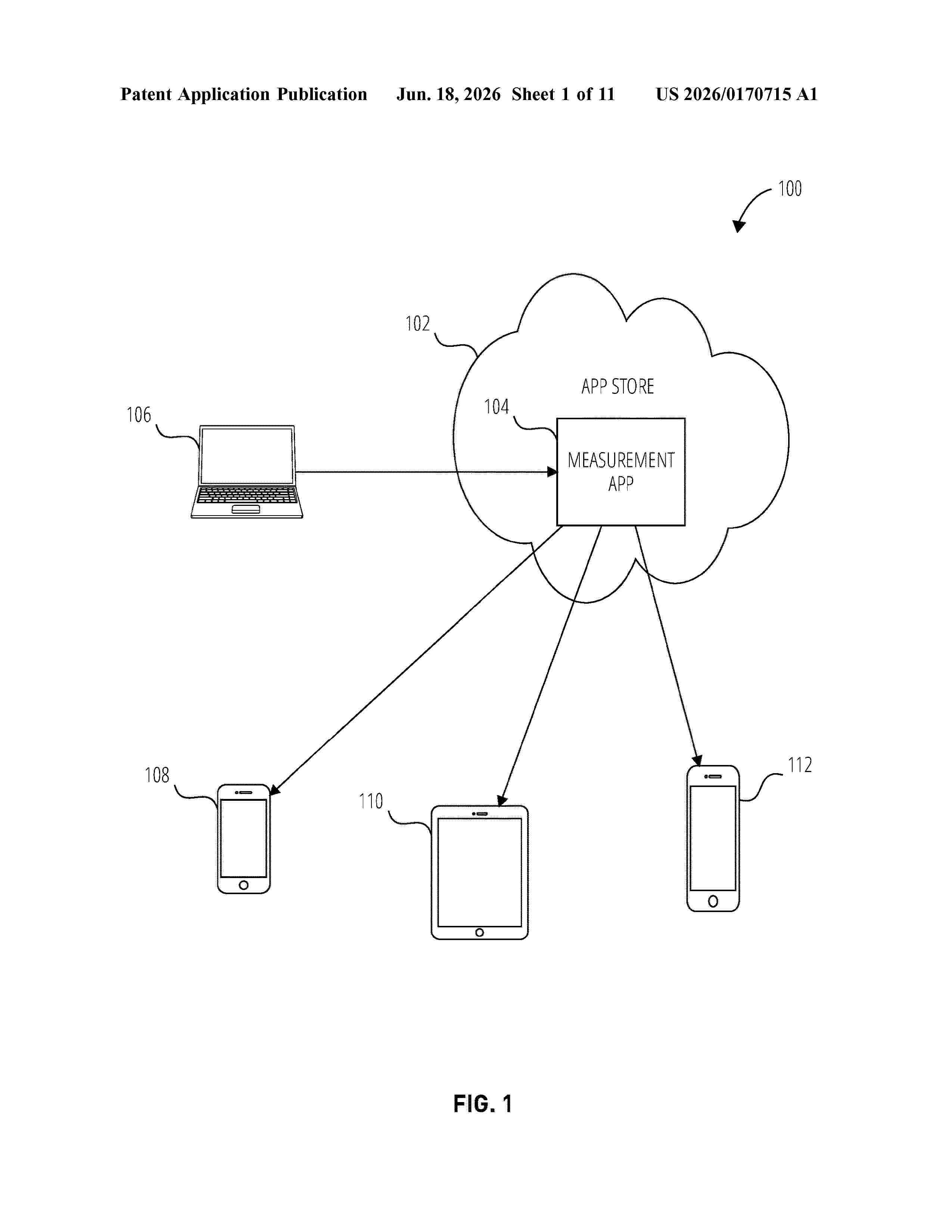
Resumen de: US20260170715A1
In some embodiments, a computer-implemented method of measuring light-emitting compounds using a smartphone is provided. The smartphone determines a transformation matrix using one or more options specified via a configuration user interface. The smartphone transforms a low-color space image that depicts at least a subject into a multispectral data cube using the transformation matrix, and determines a measurement of a light-emitting compound associated with the subject using the multispectral data cube. In some embodiments, a computer-implemented method of measuring light-emitting compounds using a smartphone is provided. The smartphone transforms the low-color space image that depicts at least a subject into a multispectral data cube using a transformation matrix. The smartphone provides values from the multispectral data cube to an ensemble of two or more machine learning models, and determines a measurement of a light-emitting compound associated with the subject based on outputs of two or more machine learning models.
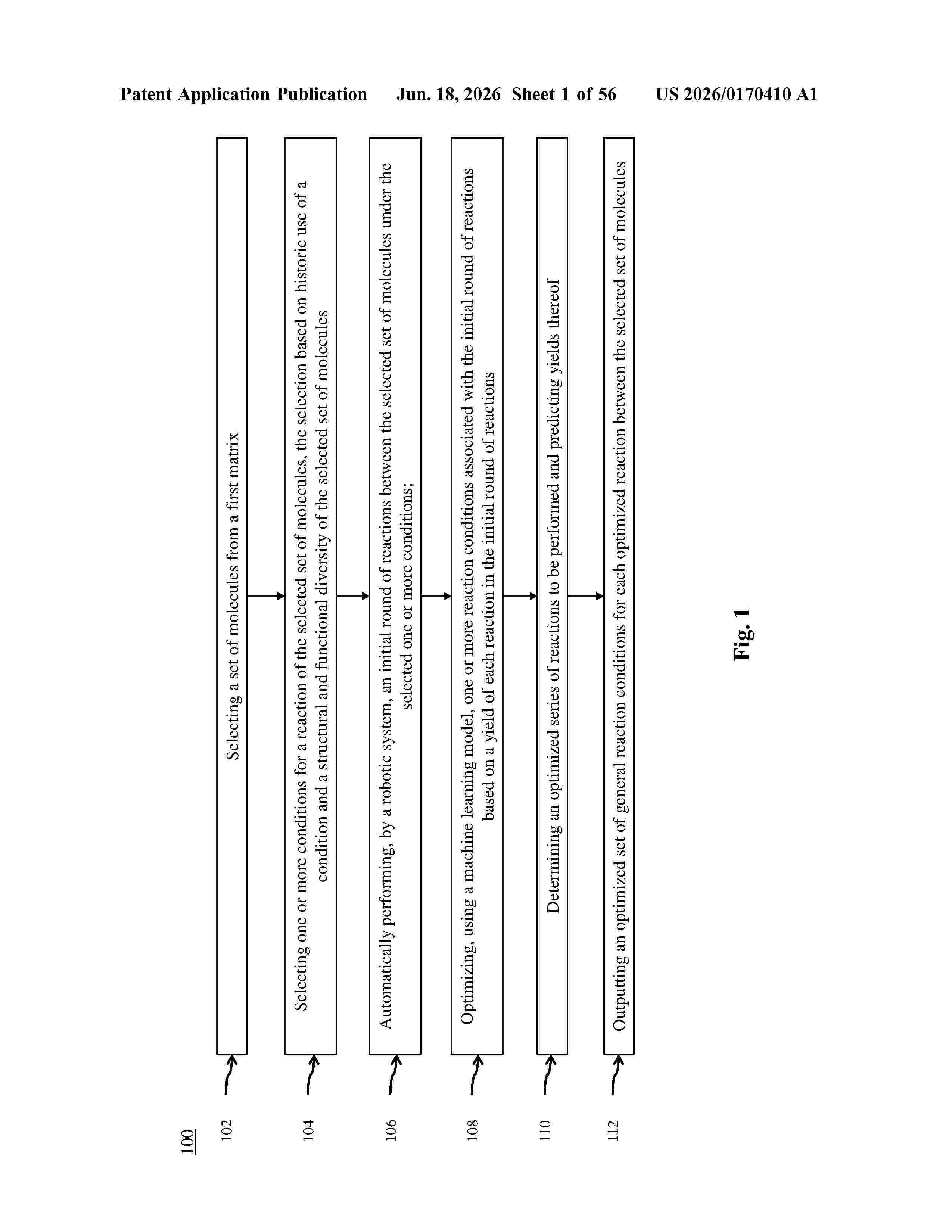
Resumen de: US20260170410A1
0000 Disclosed are systems and methods for rapidly generating general reaction conditions using a closed-loop workflow leveraging matrix down-selection, machine learning, and robotic experimentation.
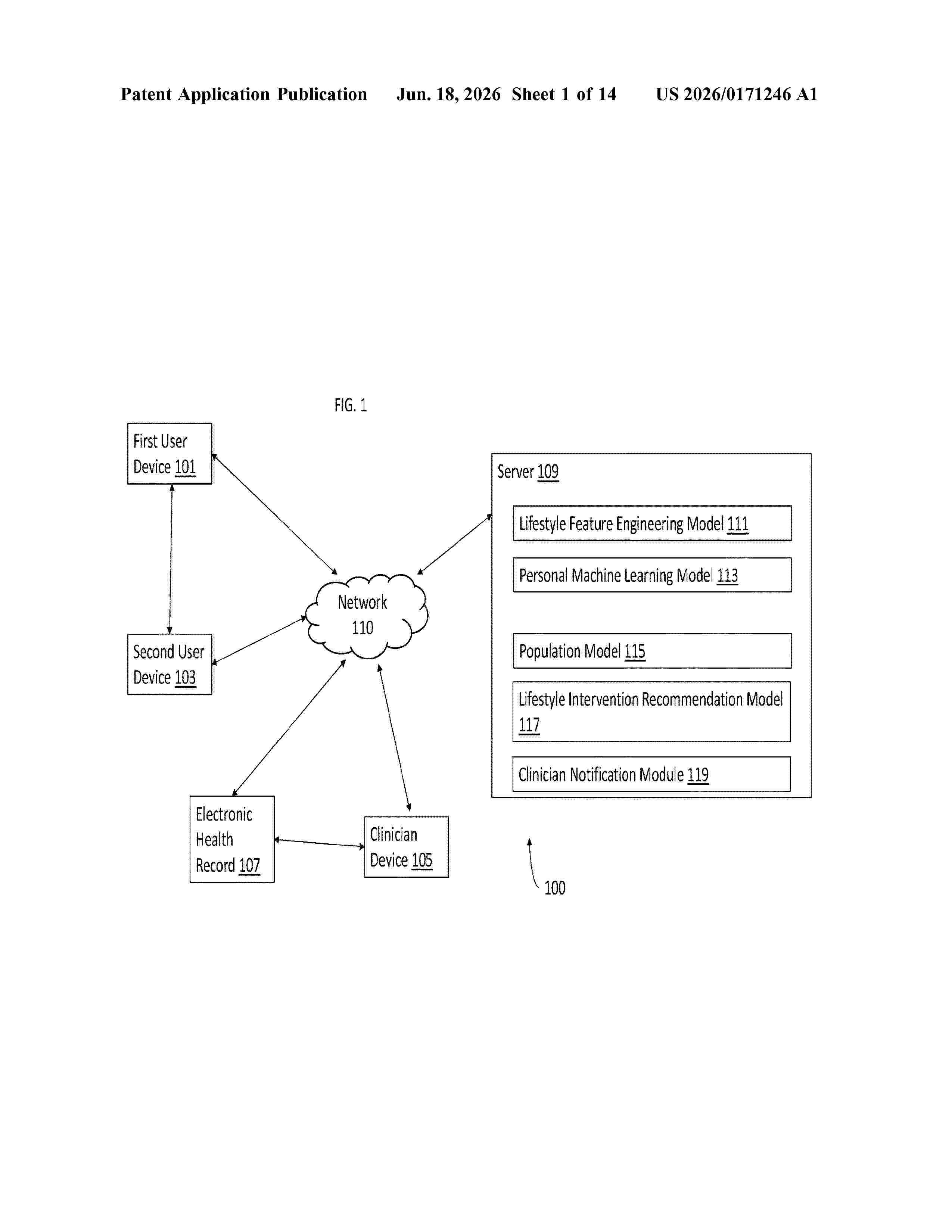
Resumen de: US20260171246A1
0000 Systems and methods for a digital lifestyle intervention system using machine learning and remote monitoring devices is described herein. The disclosed systems can include a processor configured to train, based on historical user data, a personal machine learning model to generate an output indicative of a blood pressure prediction and lifestyle feature impact on blood pressure prediction. The trained personal machine learning model can be further configured to receive user data including blood pressure data for the user and generate output including lifestyle feature impact and a blood pressure prediction by applying the trained personal machine learning model to the received user data. At least one lifestyle recommendation can be generated based on the output of the trained personal machine learning model and/or output from a population model applied to the received user data. The at least one lifestyle recommendation can be provided to a user via a user interface.
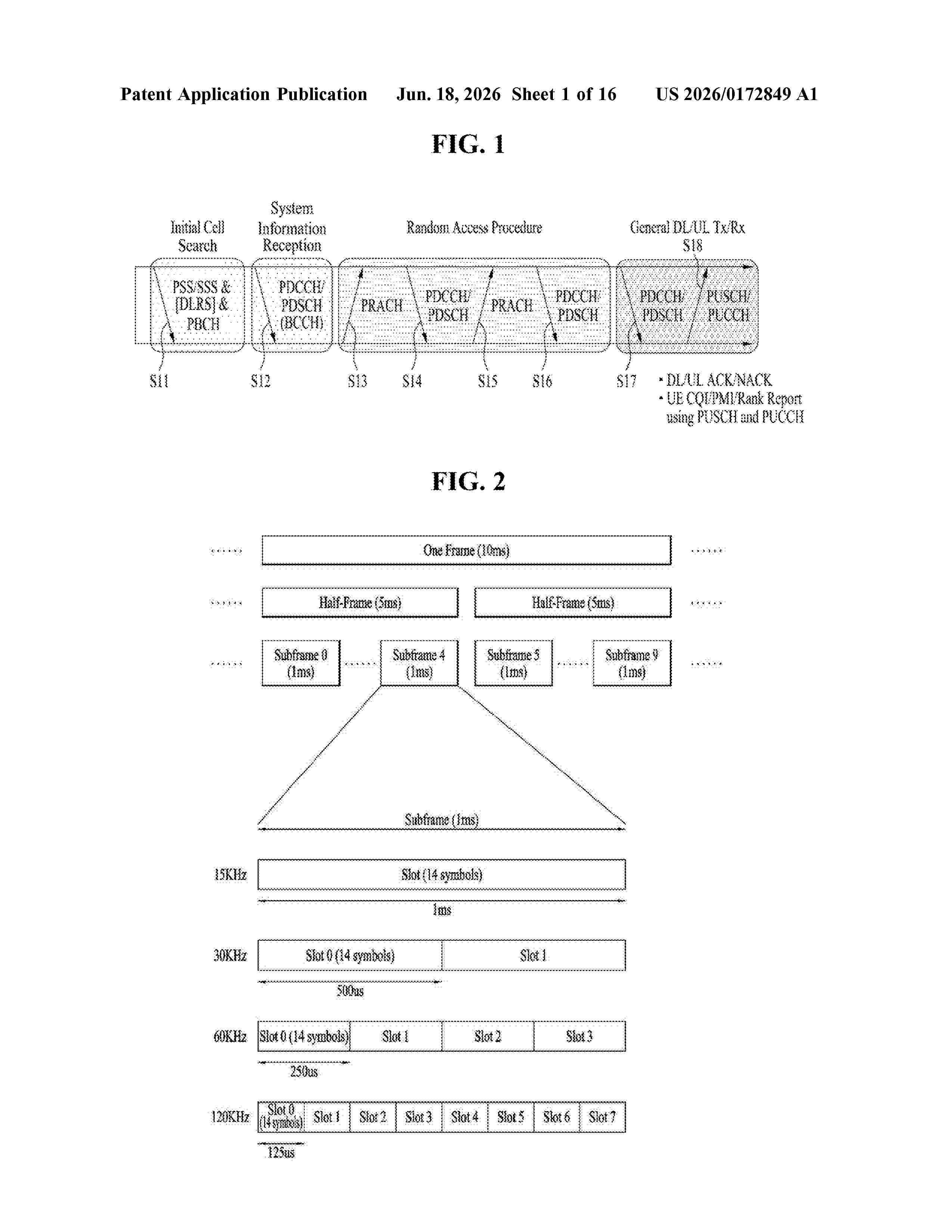
Resumen de: US20260172849A1
A method performed by a terminal in a wireless communication system according to at least one of the embodiments disclosed herein may include configuring at least one artificial intelligence/machine learning (AI/ML) model related to multiple transmissions and receptions (TRPs), monitoring the at least one AI/ML model, and performing, based on a performance of the monitored at least one AI/ML model, AI/ML model management to maintain or at least partially change the at least one AI/ML model, wherein the performance of the at least one AI/ML model may be determined based on a first multi-TRP data set related to training of the at least one AI/ML model and a second multi-TRP data set related to monitoring of the at least one AI/ML model.
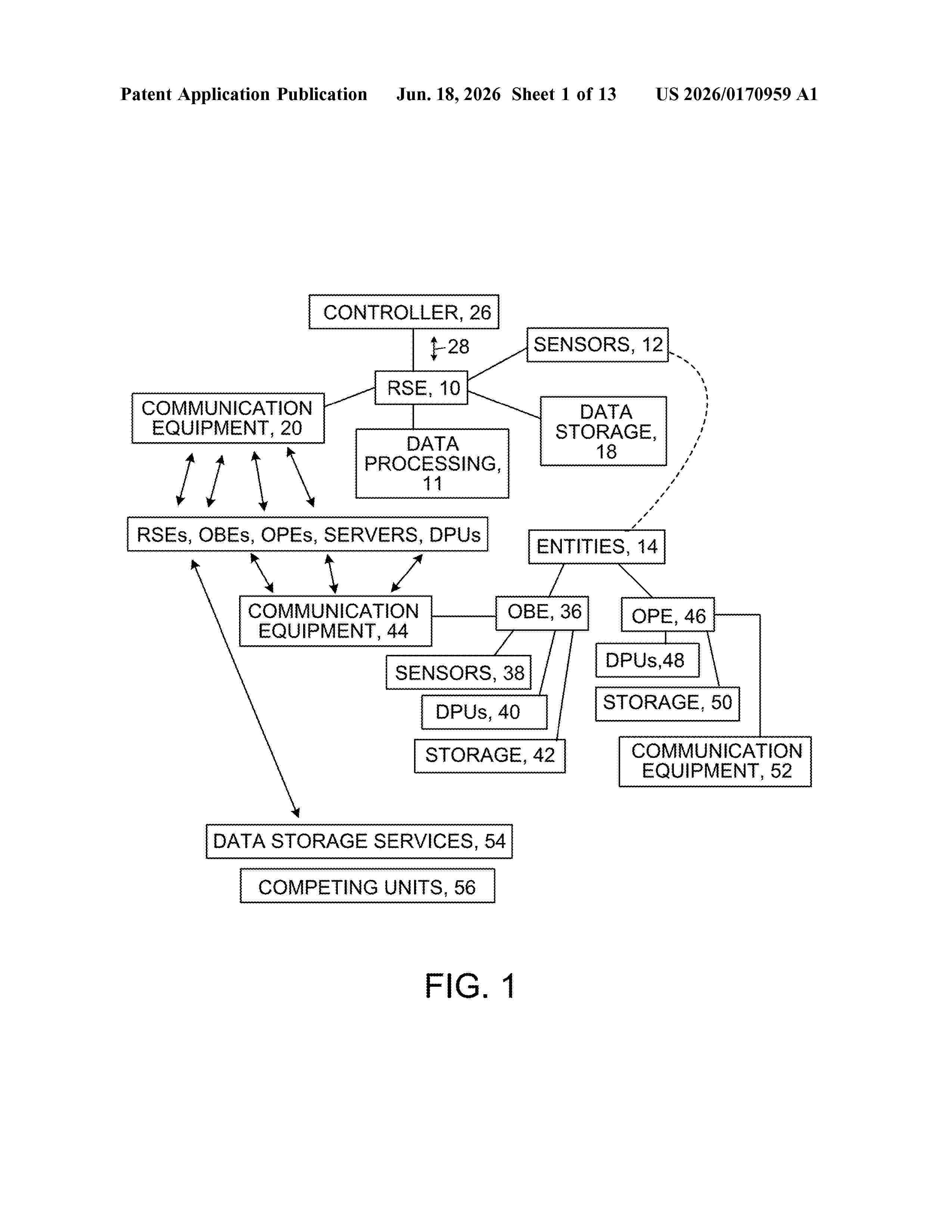
Resumen de: US20260170959A1
Among other things, equipment is located at an intersection of a transportation network. The equipment includes an input to receive data from a sensor oriented to monitor ground transportation entities at or near the intersection. A wireless communication device sends to a device of one of the ground transportation entities, a warning about a dangerous situation at or near the intersection, there is a processor and a storage for instructions executable by the processor to perform actions including the following. A machine learning model is stored that can predict behavior of ground transportation entities at or near the intersection at a current time. The machine learning model is based on training data about previous motion and related behavior of ground transportation entities at or near the intersection. Current motion data received from the sensor about ground transportation entities at or near the intersection is applied to the machine learning model to predict imminent behaviors of the ground transportation entities. An imminent dangerous situation for one or more of the ground transportation entities at or near the intersection is inferred from the predicted imminent behaviors. The wireless communication device sends the warning about the dangerous situation to the device of one of the ground transportation entities.
Resumen de: US20260169714A1
Various embodiments of the present disclosure provide hallucination mitigation techniques for text-to-code conversions that improves the functionality of a computer in various aspects. The techniques comprise receiving a text-based file that defines a set of standards for a prediction domain; generating, using a machine learning model, a decision tree based on (i) the text-based file and (ii) a decisioning prompt for the text-based file; generating, using the machine learning model, computer programmable code for the set of standards based on the decision tree and a code conversion prompt for the decision tree; and providing the computer programmable code to implement an automated task for the prediction domain.
Resumen de: US20260170420A1
0000 A machine learning model evaluation method, a data processing method, and a related device are disclosed. The method can be applied to the autonomous driving field of artificial intelligence. The method includes: processing a plurality of pieces of segmented data in an evaluation sample using a machine learning model, to generate a plurality of prediction labels, and determining a parameter value of at least one evaluation indicator. The evaluation sample includes description data of a traffic scene within a first duration, the segmented data includes description data of the traffic scene within a first sub-duration of the first duration. The at least one evaluation indicator indicates stability and/or accuracy corresponding to the plurality of prediction labels, and the accuracy is obtained based on ground-truths corresponding to the plurality of pieces of segmented data.
Resumen de: WO2026124029A1
A method for measuring a spatial angle of a drag pipe of a dredger, which relates to the technical field of ship engineering. The method comprises: collecting motion data of a hull and motion data of a drag pipe in real time, and using median filtering to remove high-frequency noise; extracting features, and constructing a comprehensive feature vector; using a fuzzy inference system to decouple nonlinear influences between the shaking of the hull and the attitude of the drag pipe; correcting an attitude estimation result on the basis of real-time error feedback; dynamically optimizing the estimation result by means of Bayesian estimation and particle filtering algorithms; and correcting a system deviation. Therefore, the measurement precision is improved. A system further evaluates the overall measurement accuracy on the basis of a machine learning model, and automatically adjusts measurement parameters and processes, so as to improve the adaptability and robustness of the system; and for an inaccurate measurement result, the system can analyze the cause and re-perform spatial angle measurement, thereby ensuring long-term stable operation.
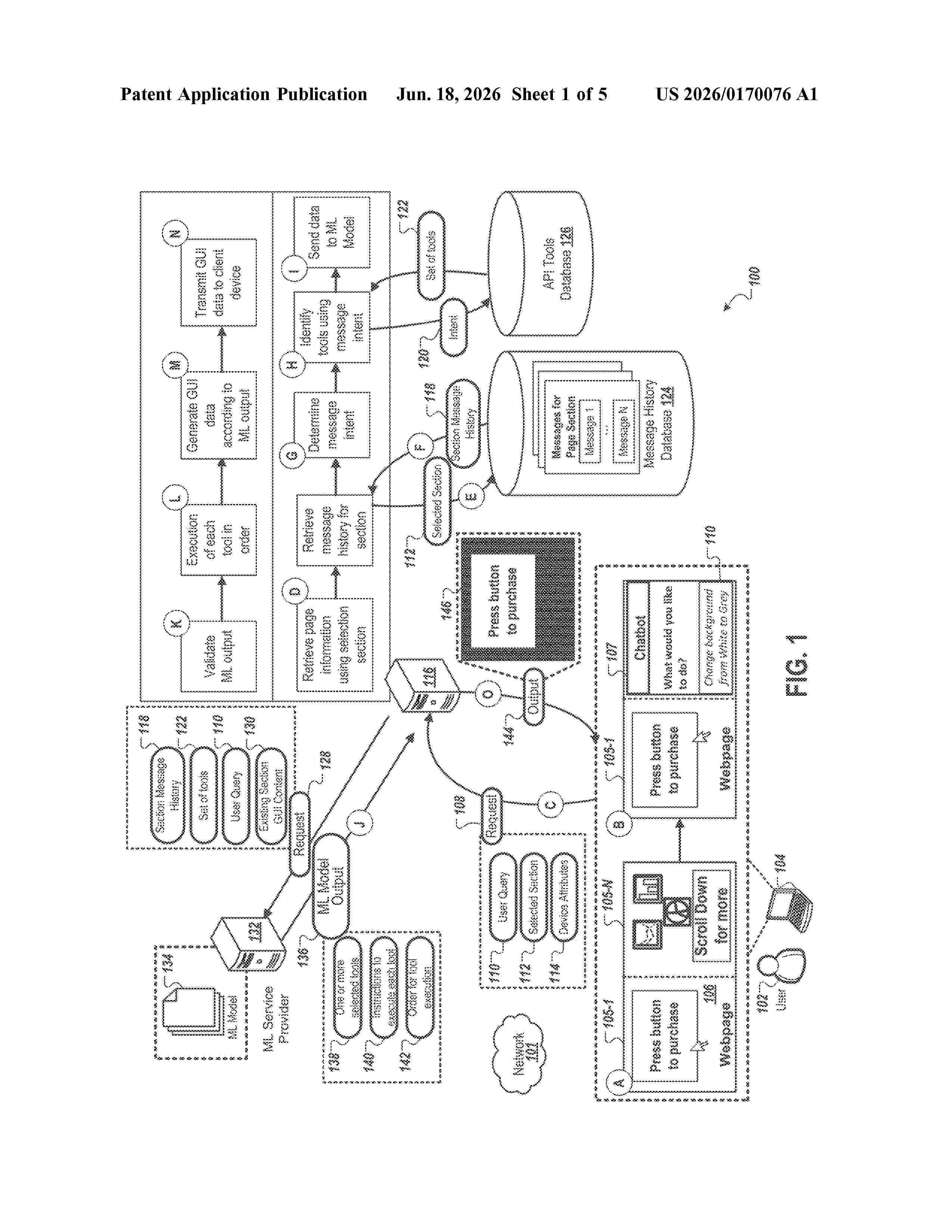
Resumen de: US20260170076A1
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for dynamically performing website creation. In some implementations, a server receives request data specifying a natural language description of a webpage modification. The server determines web development tasks corresponding to the webpage modification. The server determines web development tools configured to execute the web development tasks. The server generates prompt data for trained machine learning models. The prompt data includes instructions for generating a code update segment for the webpage modification. The server obtains from the trained ML models output data for the code update segment. The code update segment causes the web development tools to execute the tasks. The server generates a deployment artifact by executing the code update segment. The server provides an instruction that causes the computing device to display a representation of a modified webpage based on the deployment artifact.
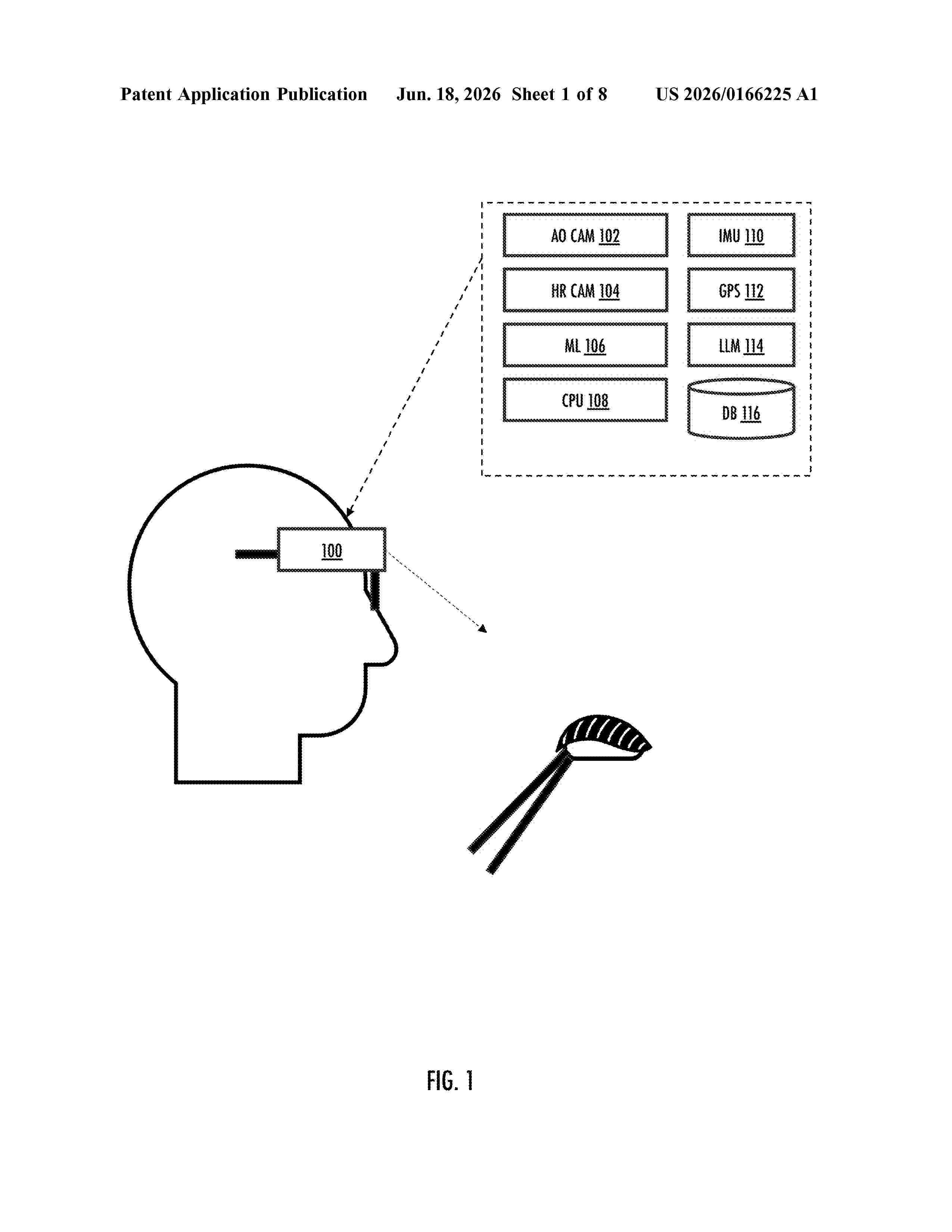
Resumen de: US20260166225A1
0000 Systems, computer programs, devices, and methods that enable coordination across multiple devices of the mobile ecosystem. In one embodiment, smart glasses detect when a user is about to eat food or take a drink and capture the consumable and portion. The data is recorded in a “morsel track” for health activity analysis. Low-fidelity captures provide preliminary recognition, while higher-fidelity captures are selectively invoked for definitive classification. Machine-learning logic generates predicted metabolic responses, such as real-time glucose trends, based on the recorded events. Predicted responses may dynamically adjust the operation of continuous glucose monitors, heart-rate sensors, or other biomedical devices. In some embodiments, the system triggers a pharmaceutical dispenser, such as an insulin pump, inhaler, or transdermal patch, to provide closed-loop therapeutic intervention in real time.
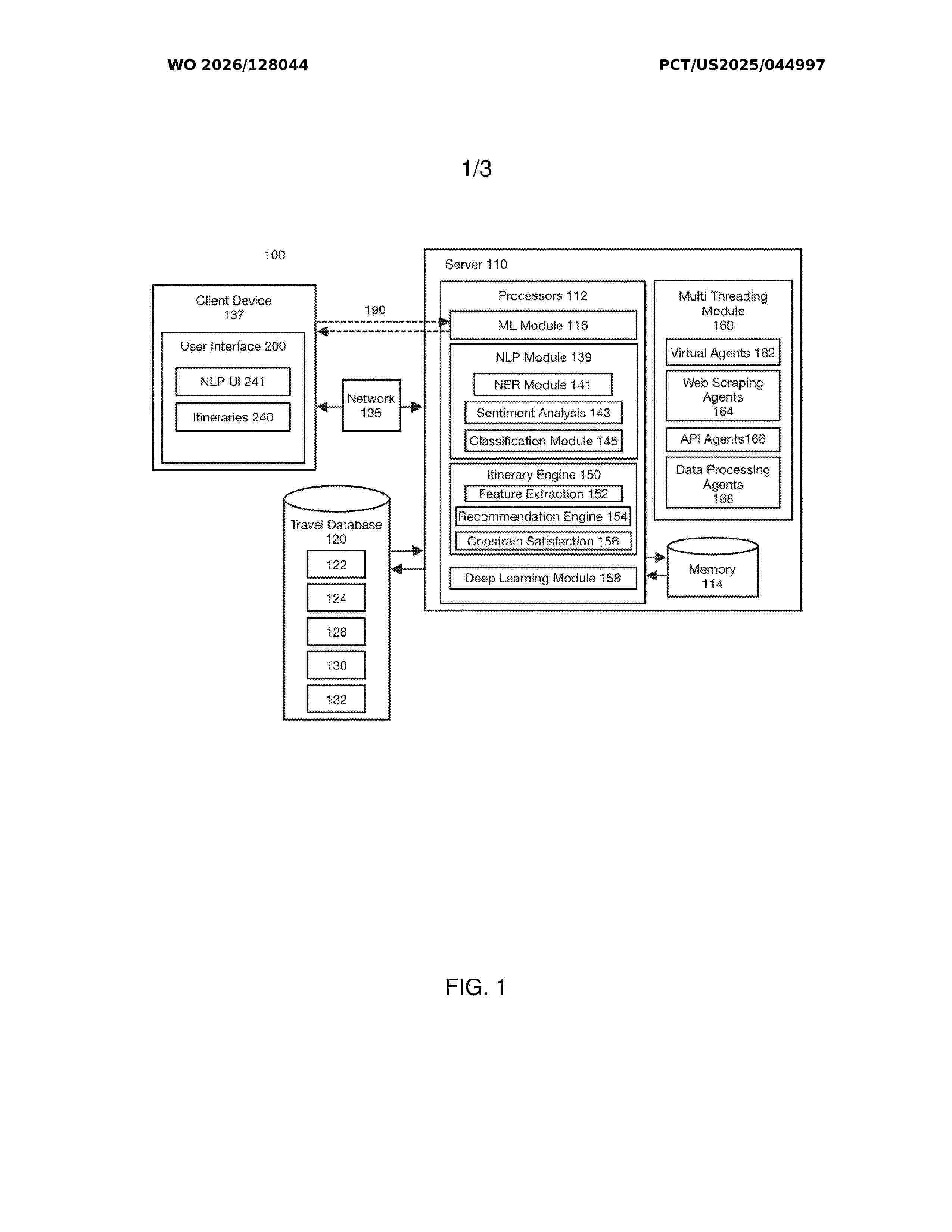
Resumen de: WO2026128044A1
The present invention relates to an automated travel planning data processing system and method that leverages advanced artificial intelligence (Al) and machine learning (ML) algorithms to generate personalized travel itineraries in real-time. The system comprises a central server with one or more processors, memory, and a machine learning module, as well as a travel database that stores aggregated data from multiple sources. Users interact with the system through a natural language processing-based user interface, which receives inputs comprising travel dates, destinations, and preferences. An Al-powered itinerary generation engine processes user inputs and aggregated data to create personalized travel plans, utilizing a multithreading module for simultaneous data retrieval and processing. The machine learning module continuously optimizes the itinerary generation process by analyzing user preferences and travel data patterns. The invention also provides a method for automated travel itinerary planning using the data processing system.
Nº publicación: US20260170453A1 18/06/2026
Solicitante:
MAPLEBEAR INC [US]
Maplebear Inc.
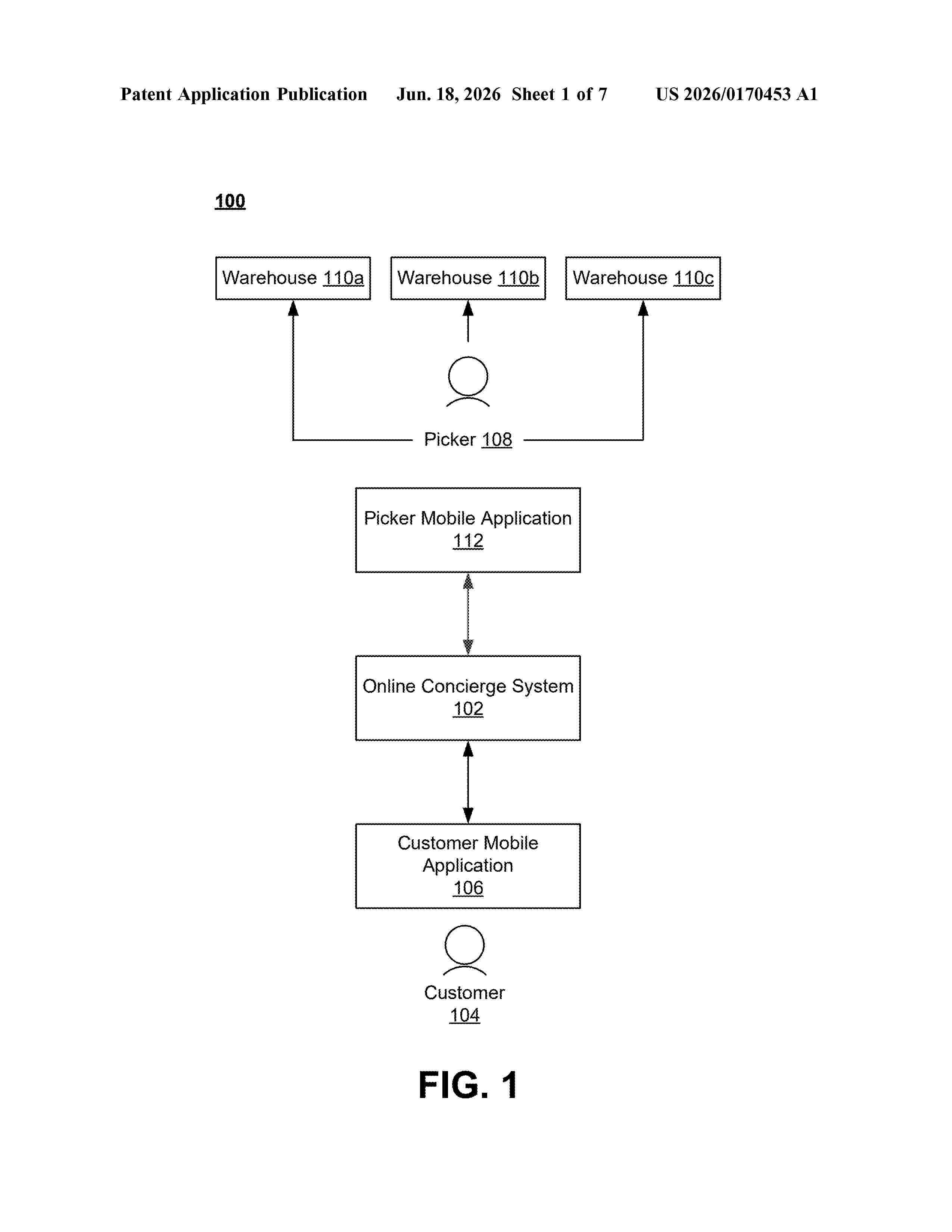
Resumen de: US20260170453A1
A method for predicting inventory availability, involving receiving a delivery order including a plurality of items and a delivery location, and identifying a warehouse for picking the plurality of items. The method retrieves a machine-learned model that predicts a probability that an item is available at the warehouse. The machine-learned model is trained, using machine learning, based in part on a plurality of datasets. The plurality of datasets include data describing items included in previous delivery orders, whether each item in each previous delivery order was picked, a warehouse associated with each previous delivery order, and a plurality of characteristics associated with each of the items. The method predicts the probability that one of the plurality of items in the delivery order is available at the warehouse, and generates an instruction to a picker based on the probability. An instruction is transmitted to a mobile device of the picker.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica