Si deseas distinguir tus productos, servicios o ambos de los de otra empresa, es posible que necesites una marca o nombre comercial. Descubre qué son, en qué consiste su procedimiento de registro y qué implica.

Información sobre los plazos de presentación de solicitudes de transformación de marcas de la Unión Europea en marca nacional española. Más información


Si tienes un nuevo dispositivo, producto o procedimiento que resuelva un problema técnico o tenga una ventaja práctica, existen distintas formas de protegerlo en España y en otros países. Descubre cómo hacerlo.

¿Tu innovación reside en la estética, la ornamentación o la apariencia de tu producto? Protégela mediante un diseño industrial. Descubre qué derechos confiere el registro y cómo realizar la tramitación.

Las indicaciones geográficas protegen el nombre de un producto originario de una zona geográfica, a la cual le debe una determinada calidad, reputación u otra característica. Descubre qué son, en qué consiste su procedimiento de registro y qué beneficios conceden.

Las patentes publicadas en todo el mundo son una valiosa fuente de información científica, técnica y comercial.

Si eres emprendedor/a o una empresa y quieres potenciar y mejorar la rentabilidad de tu negocio protegiendo de forma adecuada los activos intangibles de tu organización, en este espacio encontrarás lo necesario.



 74
resultados
74
resultados
 Última actualización
01/05/2026 [08:07:00]
Última actualización
01/05/2026 [08:07:00]



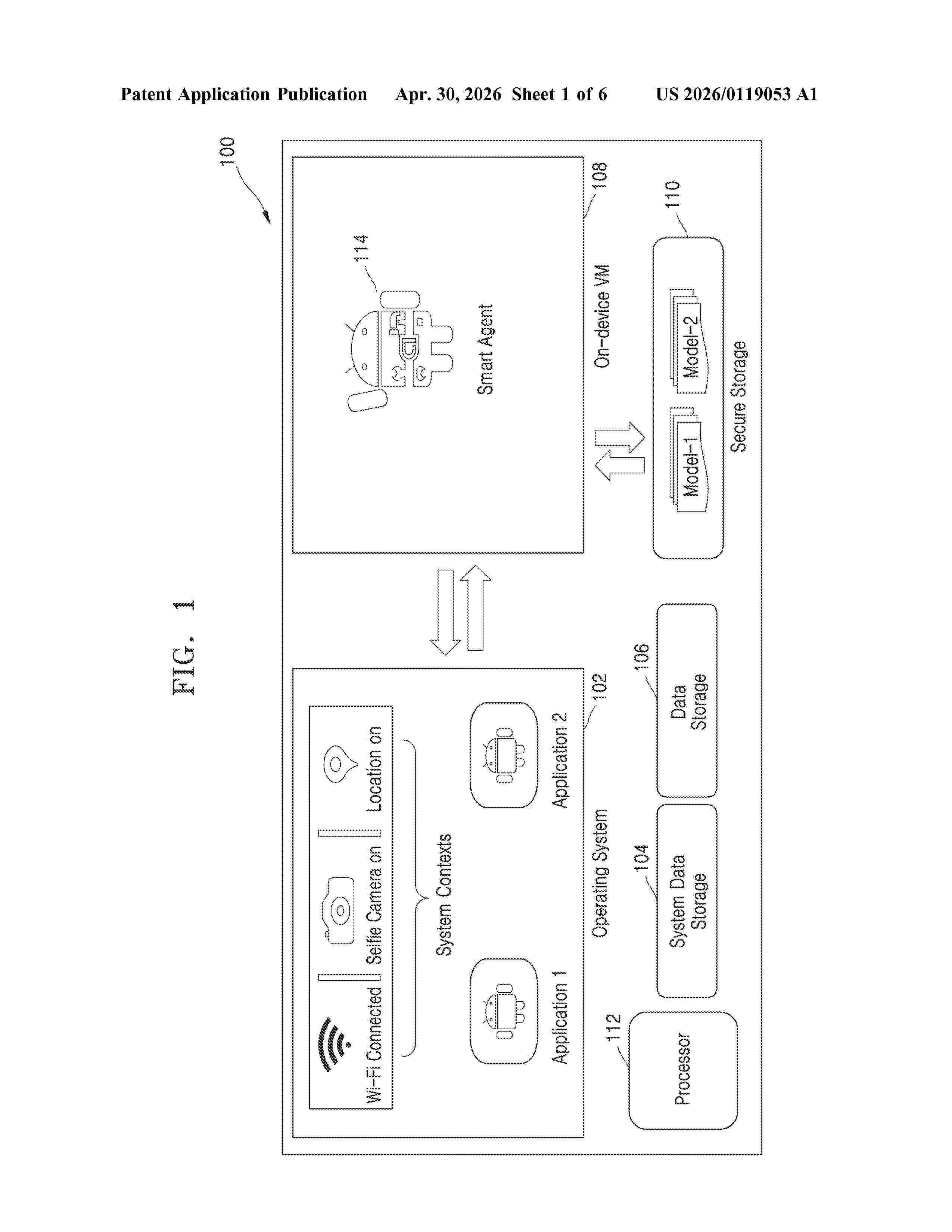
Resumen de: US20260119053A1
A method for performing an inference includes: detecting a context among at least one context associated with at least one application; triggering a model execution command to a smart agent of an electronic device, based on the detected context; loading a machine learning (ML) model into a secure storage of the electronic device, based on the detected context and the triggered model execution command; generating, using the loaded ML model, an inference, based on data associated with the detected context; and sharing the generated inference with each application of the at least one application that is registered for the detected context.

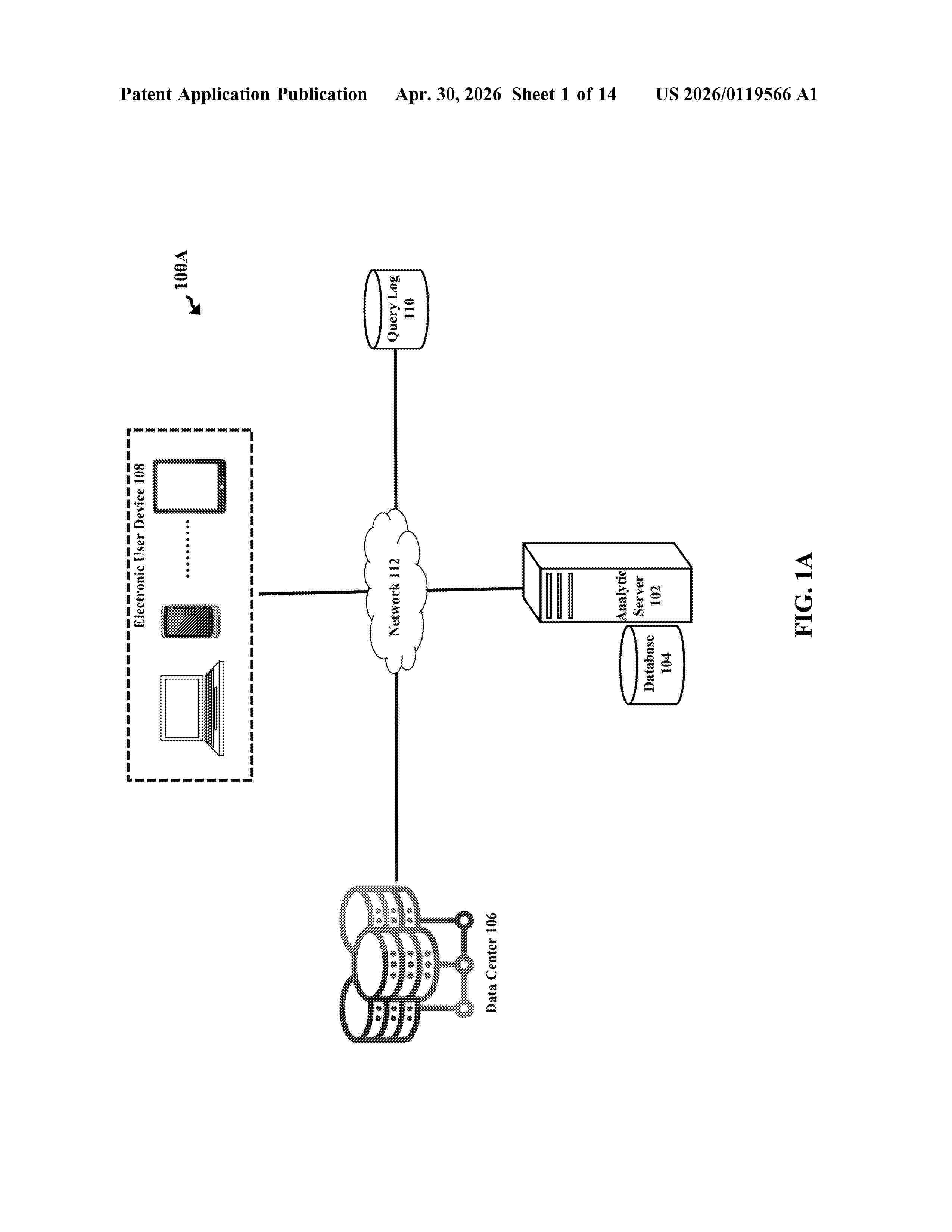
Resumen de: US20260119566A1
Disclosed herein are embodiments of systems, methods, and products comprises a server for database search and knowledge mining. The server may learn different table's semantics, relationships, and usage by parsing historical query logs and analyzing tables' metadata (e.g., table descriptions). The analytic server may generate a graph database based on the table relationships obtained from the parsing. The graph database may be a relationship graph where tables are the nodes and edges represent the relationships among tables. When the server receives a query, the server extract semantics of the query, and return a set of tables that are semantically similar to the query. The set of tables may be a list of tables whose semantic similarities with the query satisfies a threshold. The analytic server may further generate a graph including the list of tables to show the relationships of these tables.
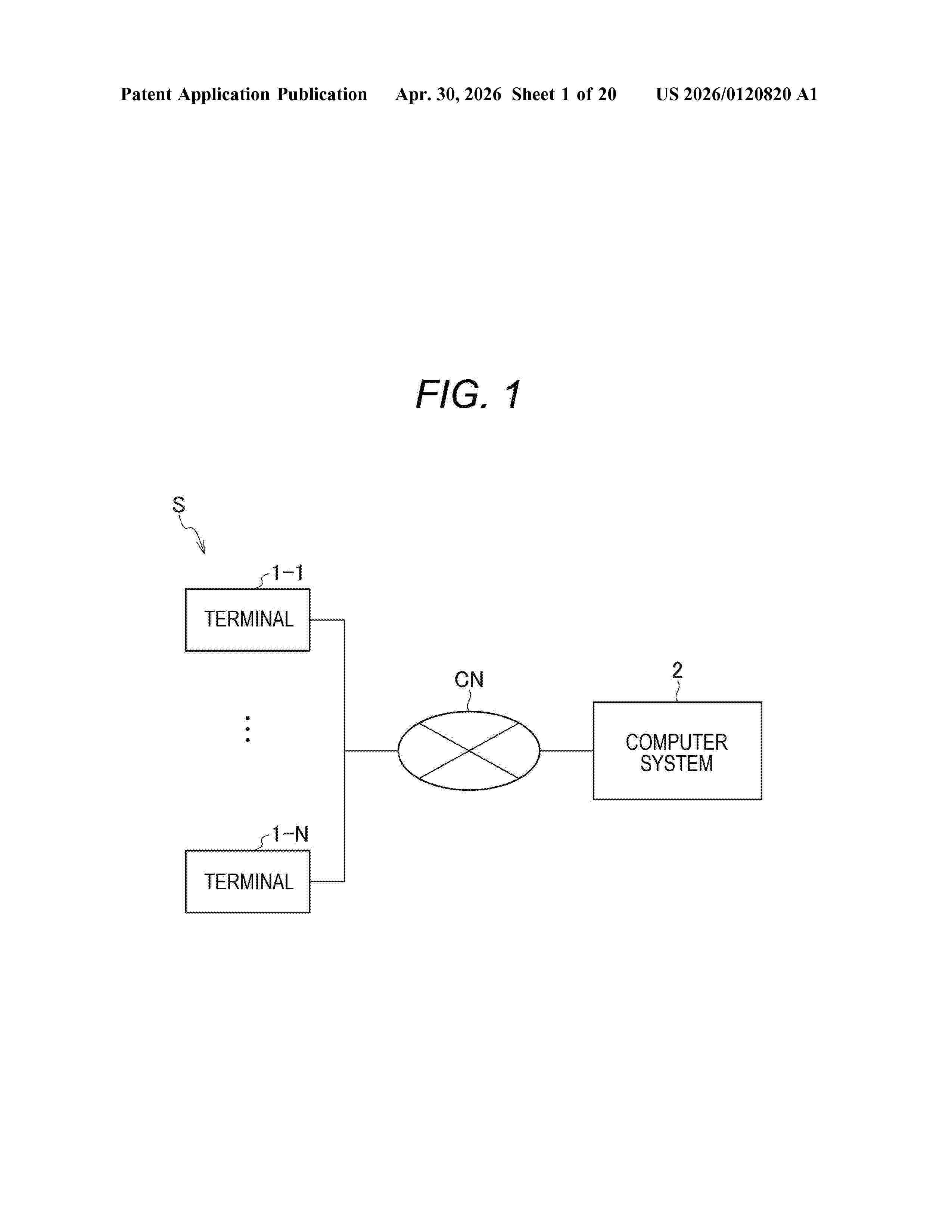
Resumen de: US20260120820A1
A machine learning model includes a processor obtaining information identifying each of the raw materials received from the user and the amount of each of the raw materials, and obtaining a predicted value of a physical property of the property name to be predicted for a composition comprising each of the raw materials by inputting into a first machine learning model at least one of the chemical fingerprints, SMILES strings or chemical graph structure data or product name or substance name corresponding to each of the raw materials and the amount of each of the raw materials, or by inputting into a second machine learning model a set of values based on at least one of the chemical fingerprints, SMILES strings or chemical graph structure data or product name or substance name corresponding to each of the raw materials and the amount of each of the raw materials.
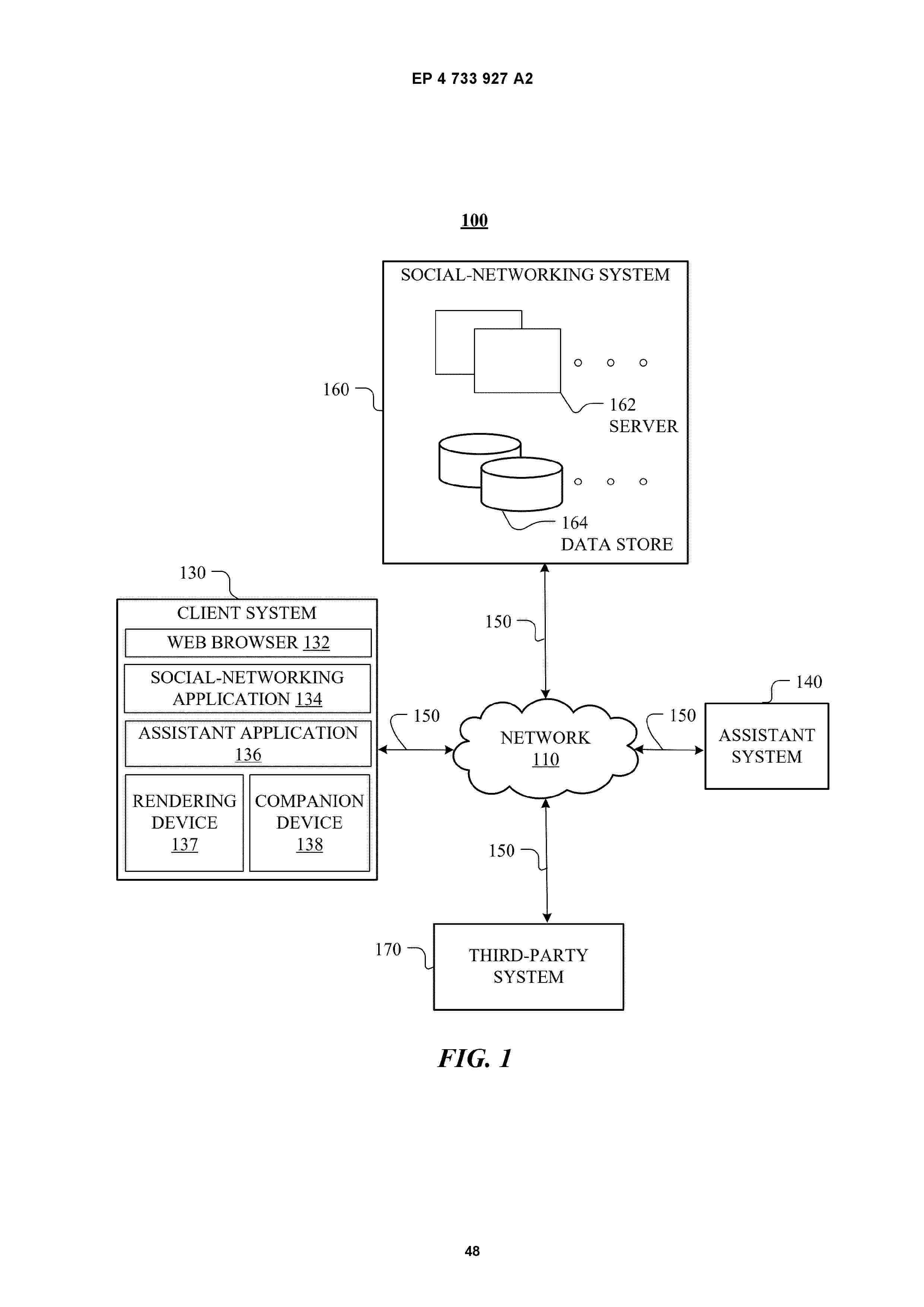
Resumen de: EP4733927A2
In one embodiment, a method includes receiving, at a microphone of the headset associated with a first user, a user request to record an activity associated with the first user; determining a trigger condition based on the user request; accessing, from the headset, one or more sensor signals captured by one or more sensors comprising a camera and the microphone; detecting, based on one or more machine learning models and using at least one of the one or more sensor signals, a change in a context associated with the activity of the first user, wherein the change in the context satisfies the trigger condition associated with the activity; and automatically capturing, responsive to the detected change in the context, visual data by the camera.
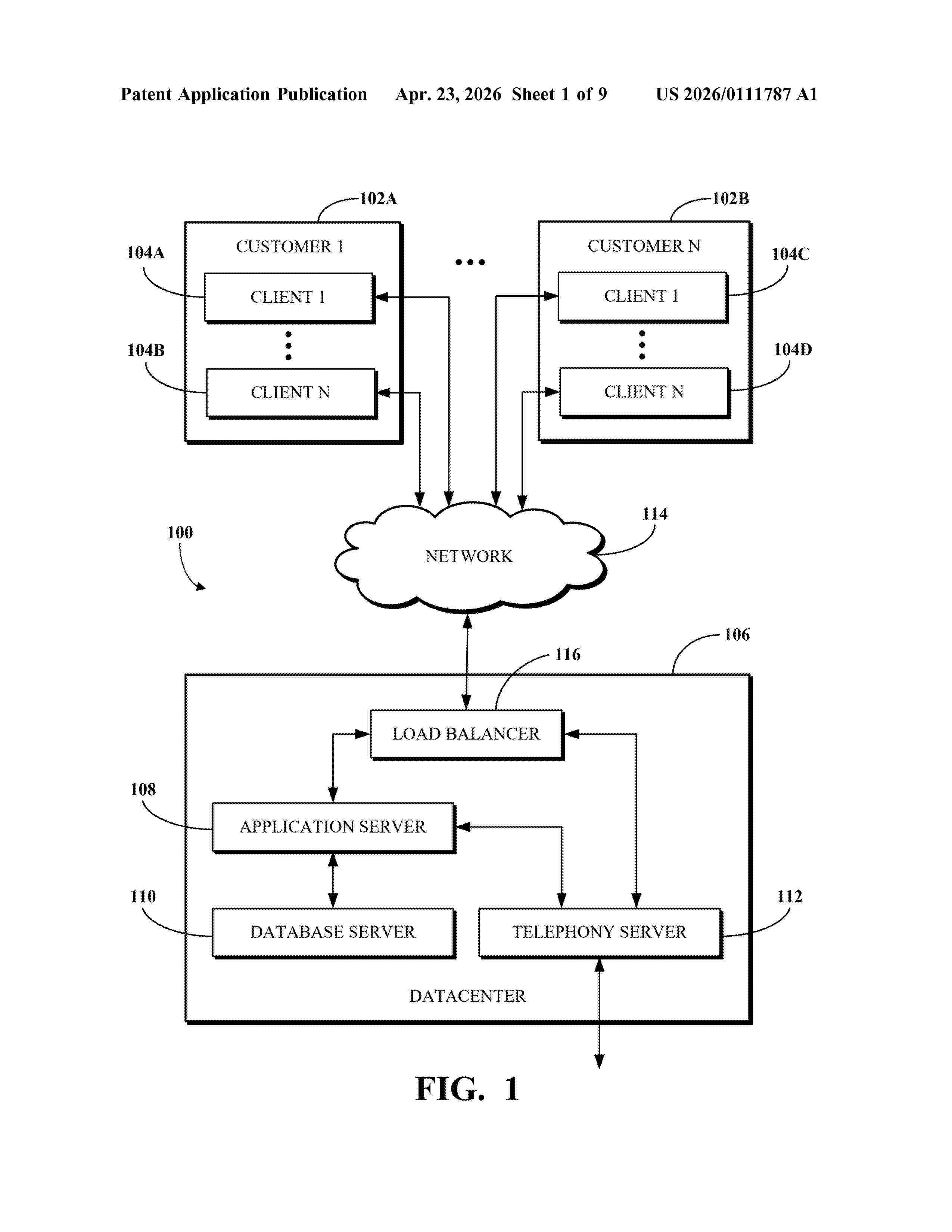
Resumen de: US20260111787A1
Machine learning models trained using personal data are automatically retrained upon deletion of the personal data. A system identifies a first data set including personal data and used to train a machine learning model. The system deletes the personal data from a data store associated with the machine learning model. The system also automatically retrains, based on deleting the personal data, the machine learning model using a second data set that excludes the personal data.
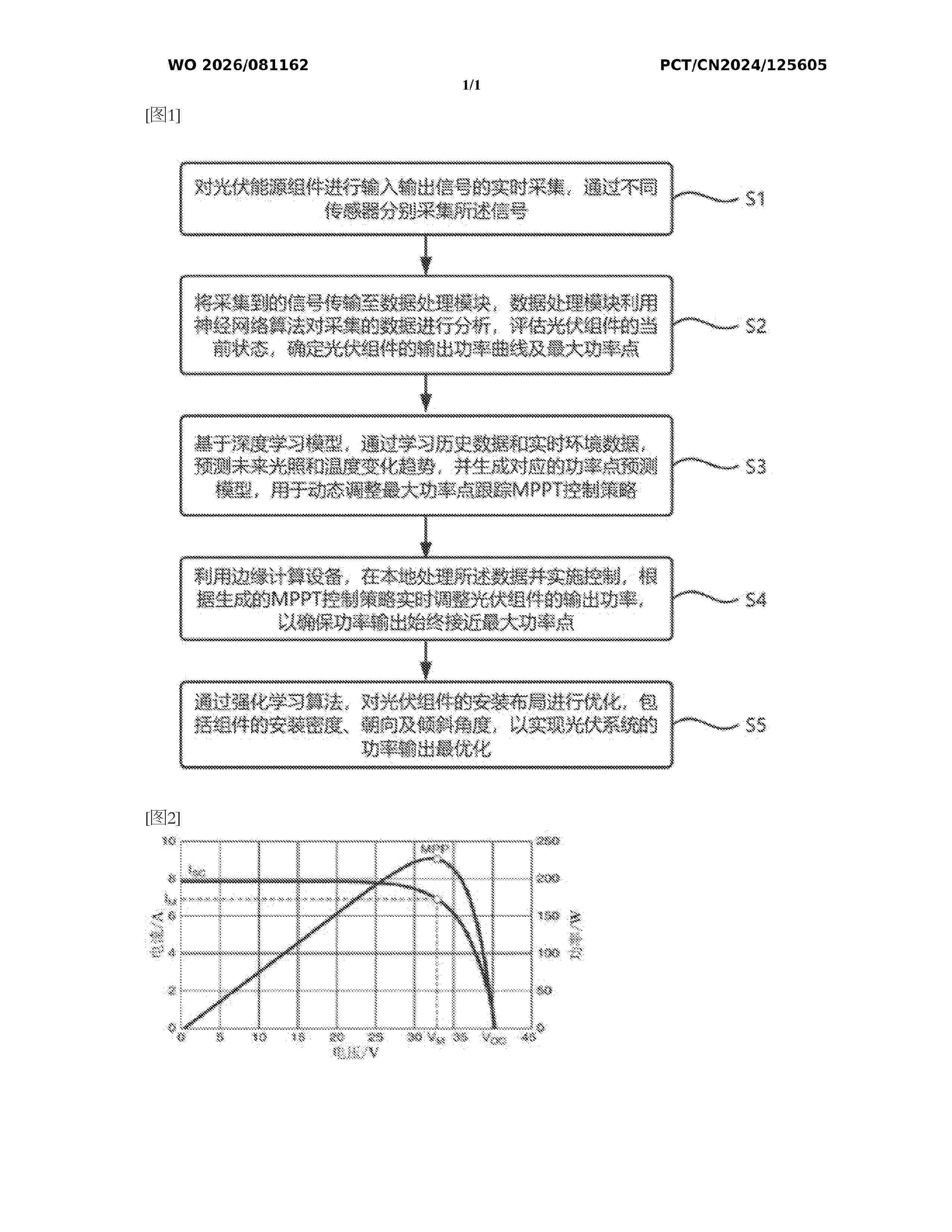
Resumen de: WO2026081162A1
An MPPT photovoltaic power optimization method based on photovoltaic modules, and a system, which relate to the technical field of photovoltaic power optimization. The method comprises: collecting photovoltaic signals, and analyzing the collected signals; on the basis of a deep learning algorithm, learning historical data and real-time environmental data to predict future illumination and temperature change trends, and generating a corresponding power point prediction model; using an edge computing device to locally process the data and implement control, and adjusting the output power of a photovoltaic module in real time on the basis of a generated MPPT control strategy; and by means of a reinforcement learning algorithm, optimizing an installation layout of photovoltaic modules. By means of introducing a deep learning model combined with dynamic step size adjustment and perturb-and-observe strategies, accurate and efficient tracking of a maximum power point for a photovoltaic system in a complex environment is realized, thus effectively improving the stability and response speed of power output. Power fluctuations and losses are reduced, thereby significantly improving the overall energy efficiency of a photovoltaic power generation system.
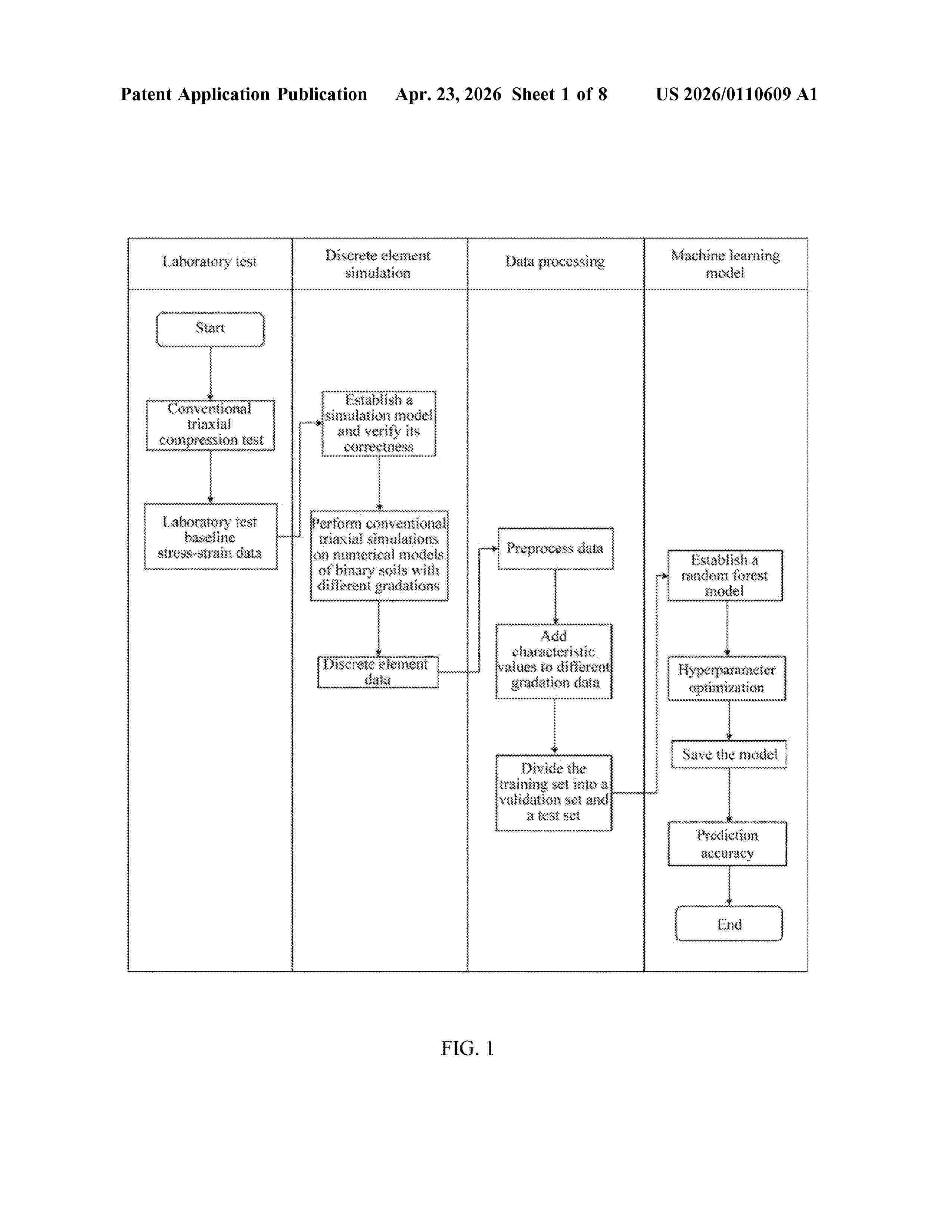
Resumen de: US20260110609A1
0000 The present disclosure relates to stress-strain prediction method for gap-graded soils based on coupling of the discrete element method and machine learning. The method includes the following steps: S1. obtaining baseline stress-strain data; S2. establishing and verifying a discrete element model; S3. establishing discrete element specimens of gap-graded soils with different gradations; S4. obtaining stress-strain data of the different gap-graded soils; S5. establishing a raw database; S6. partition the raw database; S7. establishing a random forest model; S8. training the random forest model to obtain a stress prediction model; S9. evaluating the trained random forest model; S10. predicting stress data of the gap-graded soils. This method can quickly predict the stress-strain curve of a gap-graded soil directly with its particle size ratio and fines content, improving efficiency.
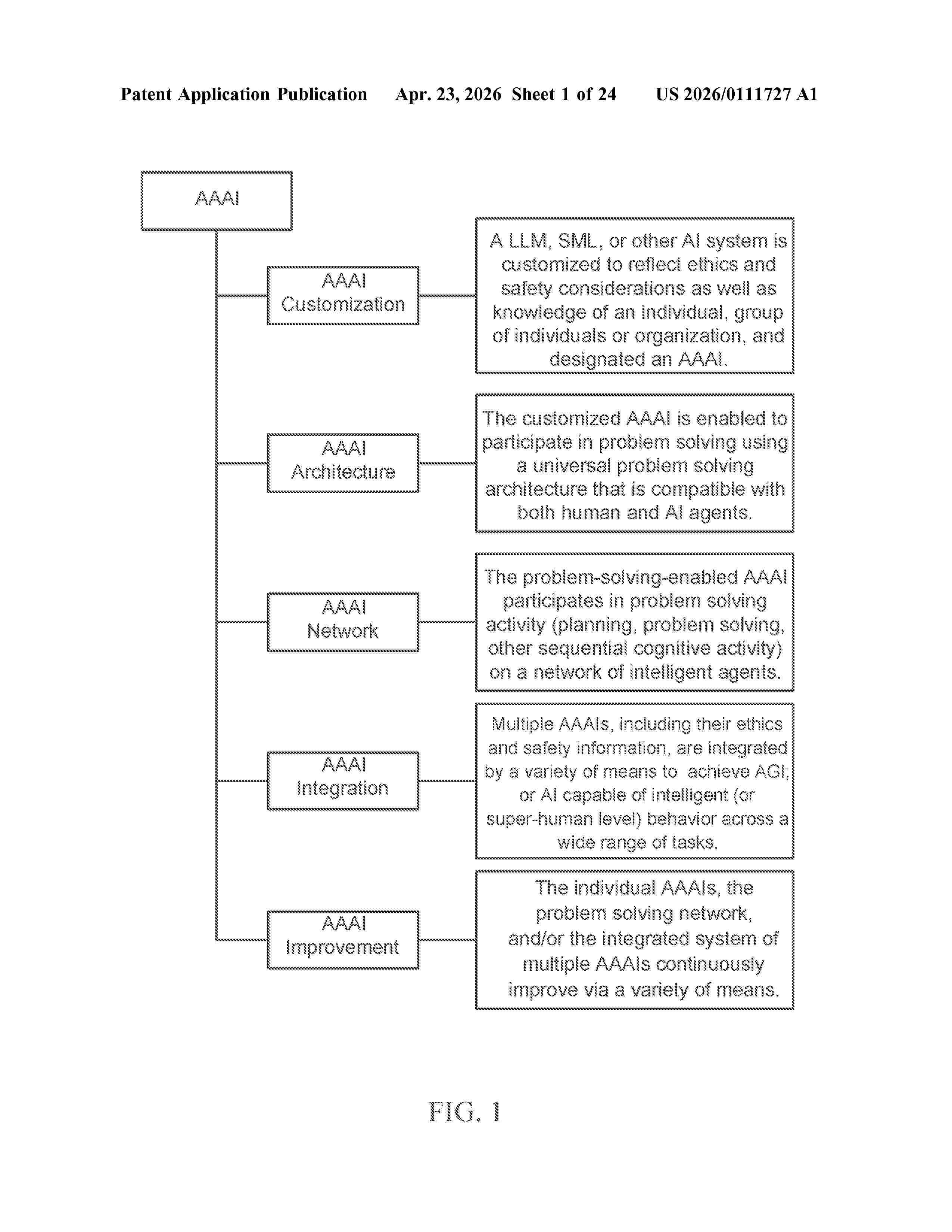
Resumen de: US20260111727A1
Data is the “fuel” that powers the machine learning “engine” for Artificial Intelligence. However, identifying high quality data that can catalyze smarter AI, AGI, and SuperIntelligent systems is becoming an increasingly challenging bottleneck for machine learning. This invention not only describes novel methods for identifying the most valuable data, but it also presents an entirely new framework for understanding the information content of AI-relevant datasets. The methods can be used by intelligent systems autonomously or in collaboration with humans. Novel methods for accelerating AI learning, and for updating the knowledge of AI systems in real-time, are also disclosed. Consistent with the view that human survival may depend on the fastest path to AGI also being the safest path, the invention describes catalysts which help maximize alignment between the values of AGI and humans. These innovative catalysts increase not only the intelligence, but also the safety, of AI systems.
Resumen de: WO2026085086A1
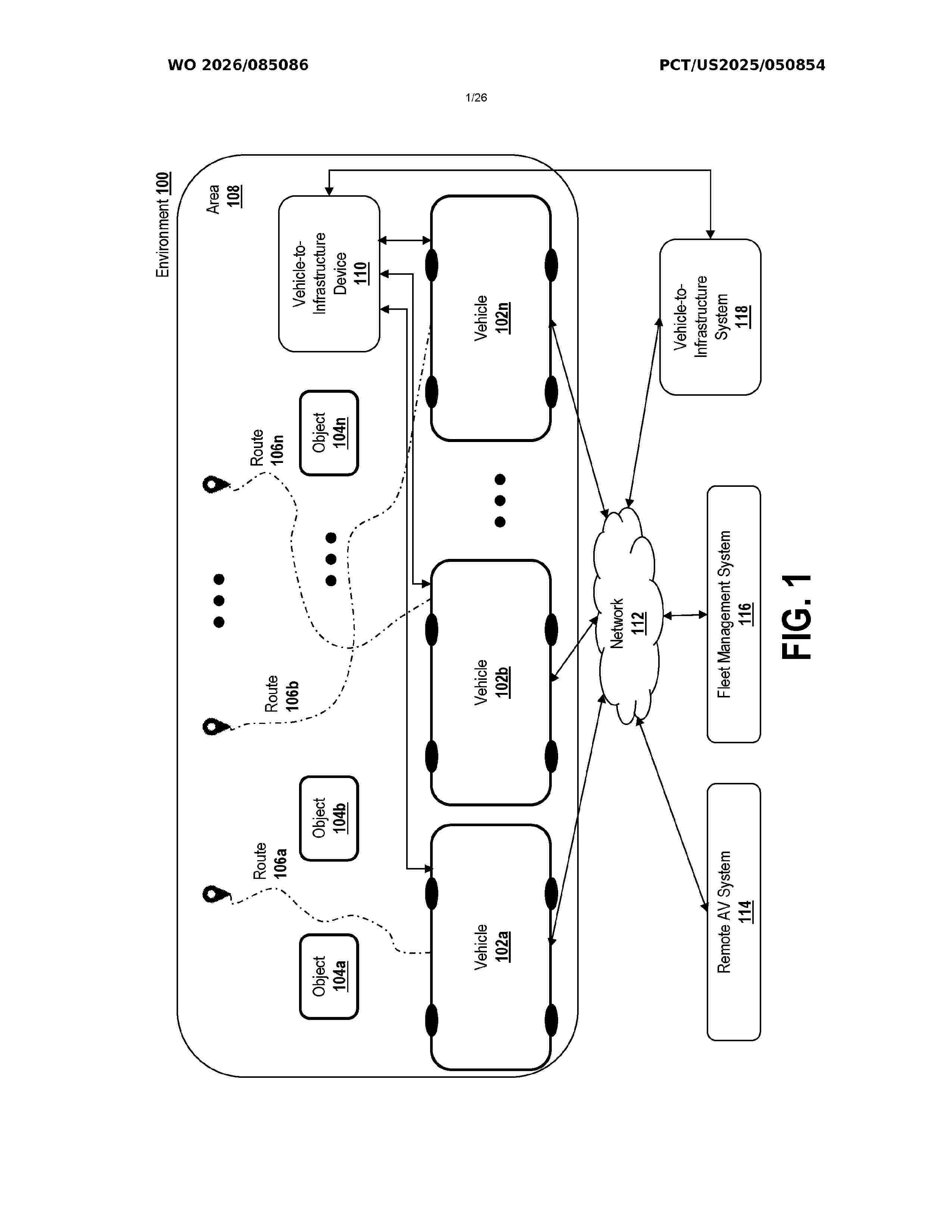
Provided are methods for an explainable deep learning system. Some methods include encoding a state and a trajectory of an autonomous vehicle into features and generating concept predictions based on the features. An explanation is generated based on the concept predictions. Systems and computer program products are also provided.
Resumen de: US12592860B2
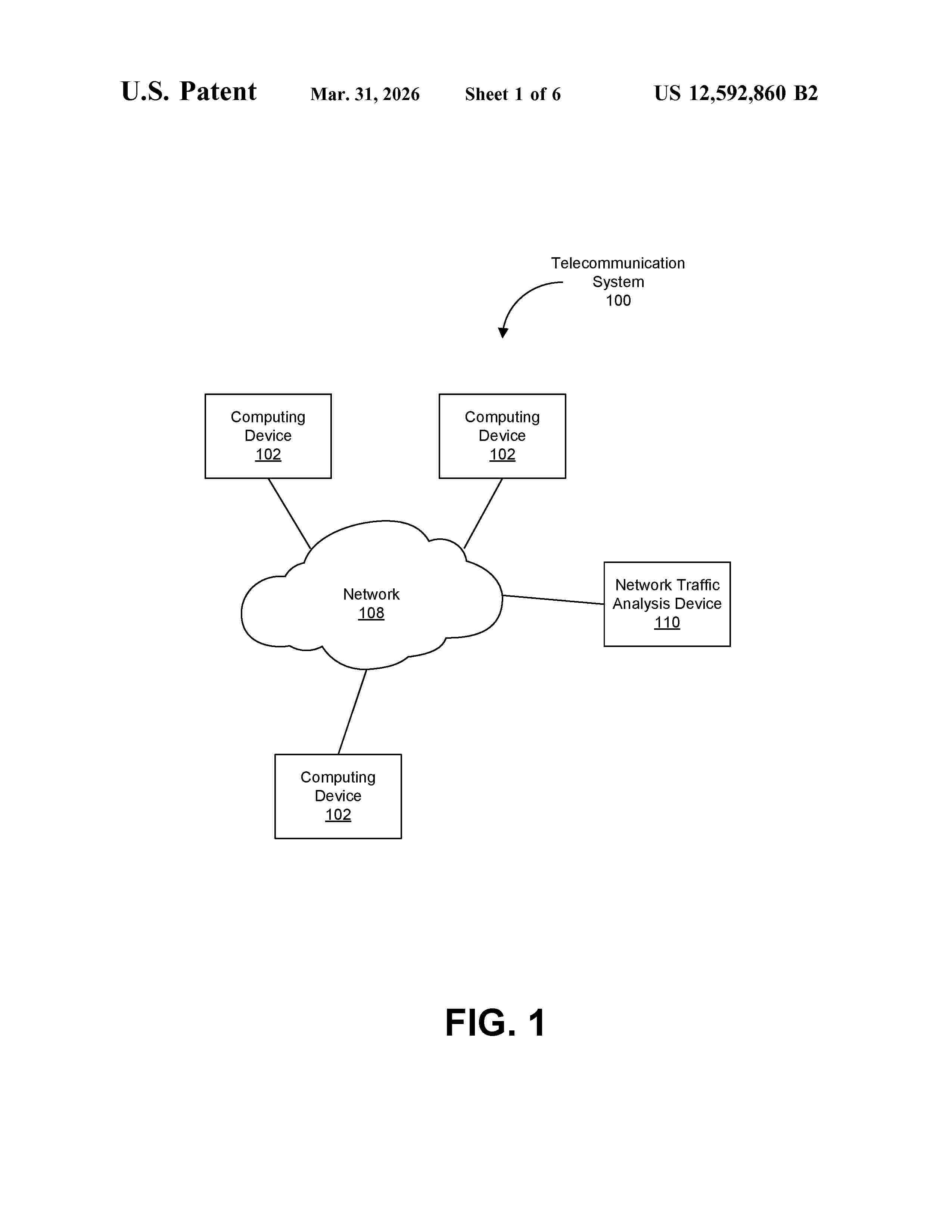
Embodiments relate to analyzing network packets in a telecommunication networks using machine learning models. The network packets are correlated and then labeled to indicate successes or failures in a subtask of communication flow. Features are extracted based on the labels and correlated network packets. The extracted features are applied to a machine learning model to predict or infer success or failure of the entire communication flow. The result from the machine learning model may again be applied to subsequent machine learning models to predict root cause of a failure or to predict or infer the type of success. In this way, more accurate diagnosis of network issues in the telecommunication networks may be made in a more expedient manner.
Resumen de: WO2024258464A1
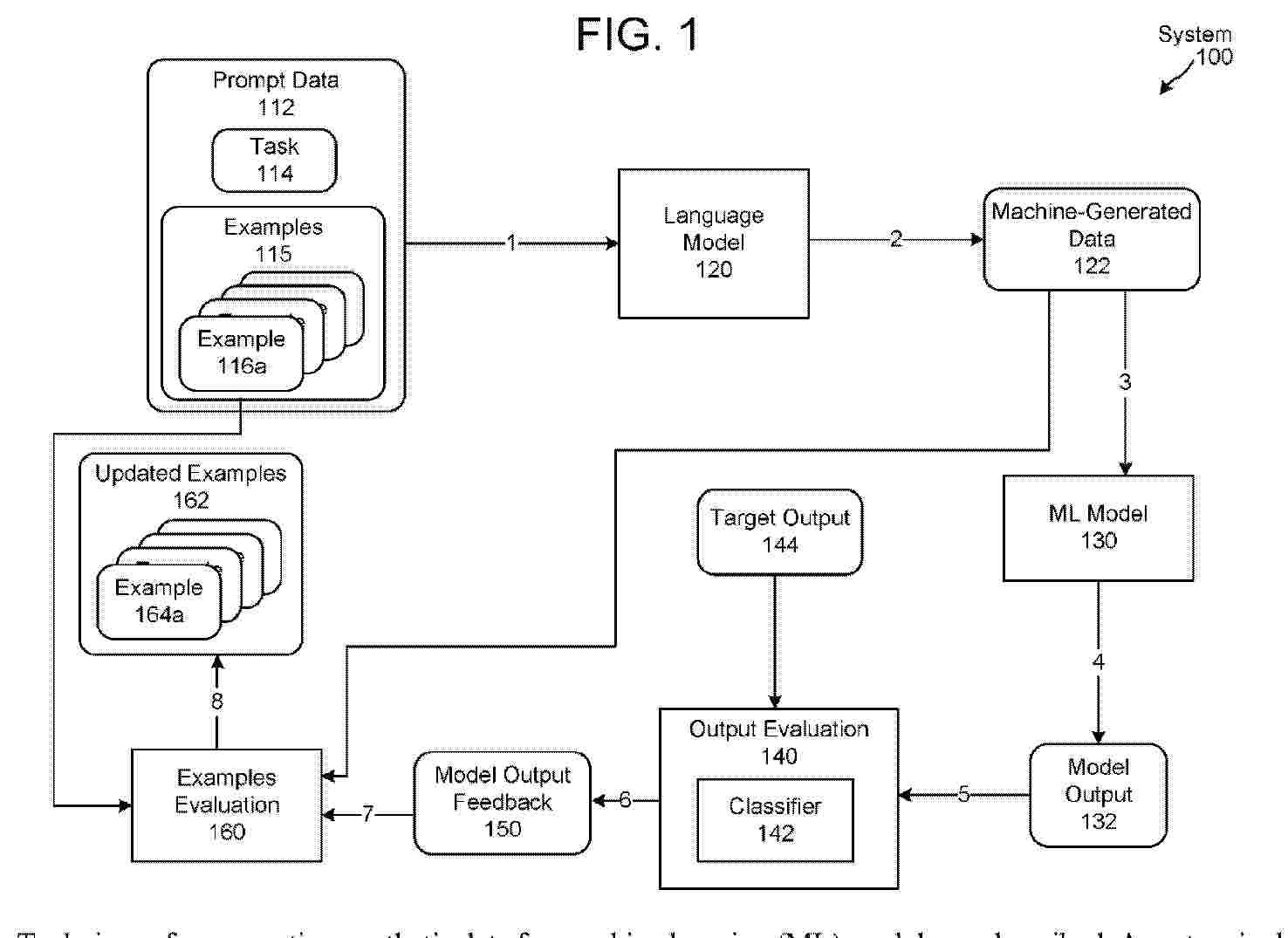
Techniques for generating synthetic data for machine learning (ML) models are described. A system includes a language model that processes a task and a corresponding set of example inputs to generate another input, referred to herein as a machine-generated data. The machine-generated data is processed using a ML model (that data is being generated for) to determine a model output, and the model output is analyzed to determine whether it corresponds to a target output. If the model output corresponds to the target output, then the machine-generated data is added to the set of example inputs and one of the original example inputs is removed to generate an updated set of example inputs. The updated set can be used for various training techniques.
Resumen de: EP4730132A1
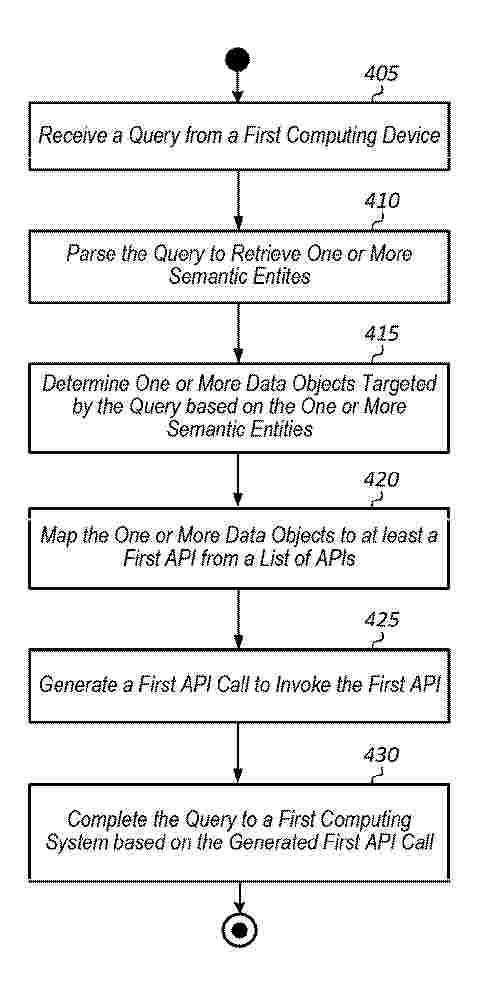
0001 A received query is parsed by a first machine learning (ML) model to retrieve one or more semantic entities. Next, a second ML model is trained with a list of application programming interfaces (APIs) and corresponding first data to generate a second trained ML model which receives the one or more semantic entities as inputs. Based on these inputs, the second trained ML model selects a given API from the list of APIs. Then, a third ML model is trained with the given API and corresponding second metadata to generate a third trained ML model. Next, the third trained ML model receives the one or more semantic entities as inputs and generates a given API call for invoking the given API. Then, the given API call is executed and the query is completed to a first computing system based on invoking the given API.
Resumen de: EP4730710A1
0001 Systems and methods are disclosed for responding to a data incident. One or more processors receive one or more indicators of a data leak occurring at one or more nodes of a network. One or more processors causes an identification, by a machine-learning model, of one or more compromised nodes within the network based on the one or more indicators of a data leak. One or more processors may receive from the machine-learning model the identification of the one or more compromised nodes. One or more processors modify access permissions at one or more identified compromised nodes based on a user permission schema or pre-determined access rules, in response to the data leak. One or more processors cause a generation of a notification regarding the data leak and the modifications of access permissions to one or more users associated with the network.
Resumen de: WO2024255997A1
A data processing apparatus (10) for enhancing, in particular optimizing a machine learning, ML, model for parallelized operation on a plurality of processing devices (20) is disclosed, wherein each processing device (20) comprises a plurality of processing elements, PEs, (21a- d) configured to perform one or more of a plurality of ML model tasks. The data processing apparatus (10) is configured to generate based on the ML model a computational graph, CG, representation (30) of the ML model, wherein the CG representation (30) comprises a plurality of nodes (31) and a plurality of edges (32), wherein each of the plurality of nodes (31) is associated with one or more of the plurality of ML model tasks and wherein the plurality of edges (32) define a plurality of dependencies of the plurality of nodes (32) of the CG representation (30). Furthermore, the data processing apparatus (10) is configured to generate an enhanced CG representation of the ML model by adding to the CG representation (30) of the ML model one or more further dependencies of the plurality of nodes (31) of the CG representation (30) of the ML model. The data processing apparatus (10) is further configured to compile the enhanced CG representation of the ML model for generating code for each of the plurality of processing devices (20).
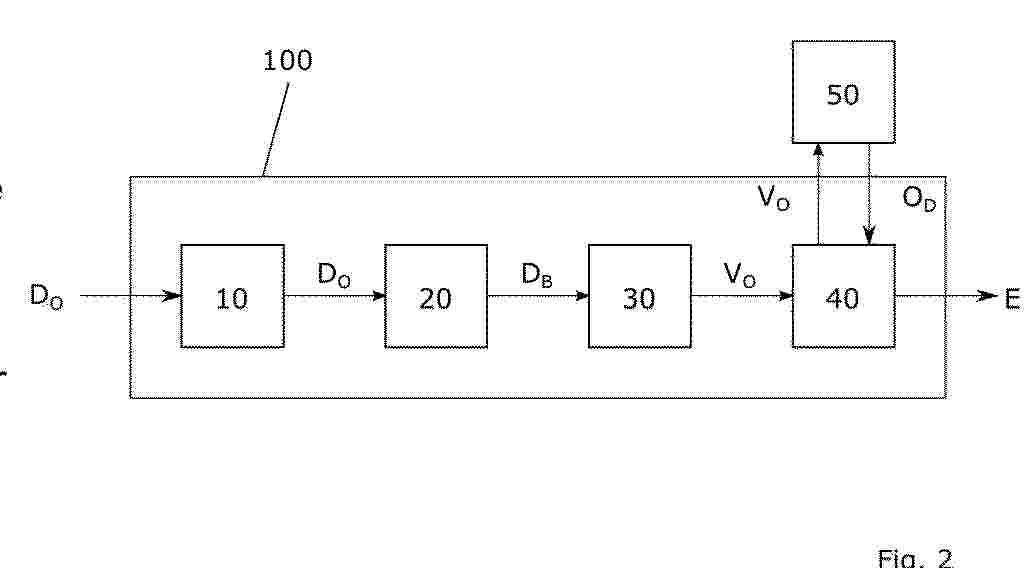
Resumen de: BE1032955A1
Die Erfindung betrifft ein computerimplementiertes Verfahren zum Suchen von Datenbankobjekten in einer Datenbank 50, umfassend die Schritte: Empfangen (S1), durch eine Eingangsschnittstelle (10), von Objektdaten (DO) eines Suchobjekts. Bestimmen (S2), durch ein Machine learning, ML,- Kodierungsmodul (30), einer vektoriellen Objekt-Kodierung des Suchobjekts unter Verwendung der Objektdaten (DO), wobei die vektorielle Kodierung mindestens einen Merkmalsvektor (VO) umfasst. Bestimmen (S3), durch ein Suchmodul (40), einer Ähnlichkeit des mindestens einen Merkmalsvektors (VO) zu Merkmalsvektoren der Datenbankobjekte (OD). Bestimmen (S4), durch das Suchmodul (40), eines Suchergebnisses (E) aus Datenbankobjekten (OD) abhängig von der bestimmten Ähnlichkeit.
Resumen de: US20260105383A1
An approach is provided for prediction-guided machine learning model ensembling. Label groupings within an output range of a base machine learning model are determined. Accuracies of the base model across the label groupings are evaluated. One or more of the label groupings are identified whose respective evaluated accuracy does not satisfy end user-defined criteria. Using a reduced training set, a specialized machine learning model for a given label grouping included in the identified one or more label groupings is trained. A majority of samples of the reduced training set are from the given label grouping. During inference, it is determined that an initial prediction by the base model is within an output range specified by the given label grouping. A weighting for an ensembling using the base model and the specialized model is determined. Using the ensembling, the initial prediction is refined to generate a final prediction.
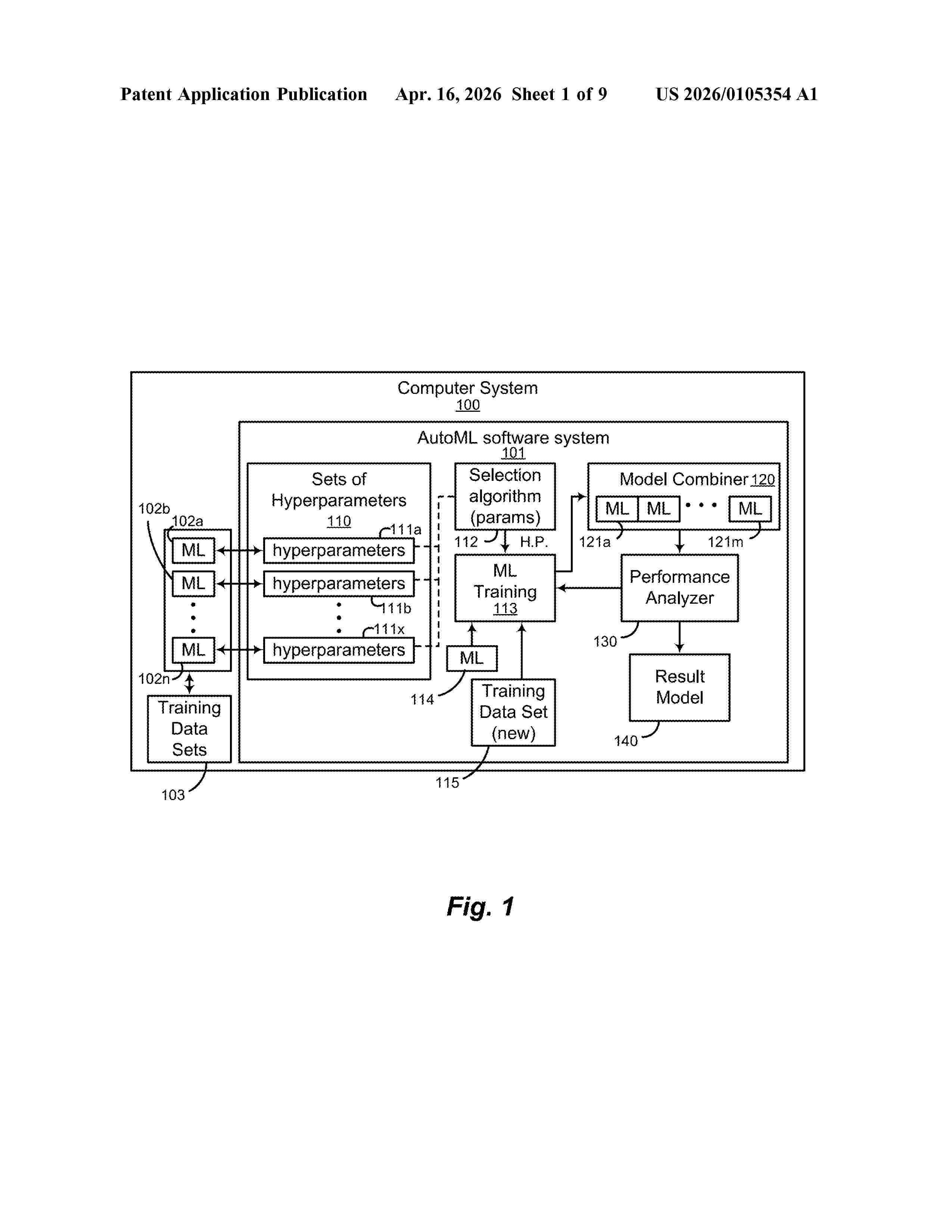
Resumen de: US20260105354A1
Embodiments of the present disclosure include techniques for automatically generating machine learning models. In one embodiment, sets of hyperparameters corresponding to machine learning models trained on one training data set are provided as an input. The hyperparameters are iteratively selected using an algorithm, such as a bandit algorithm, and used to train an ML model using another training data set. The performance of the trained ML model is evaluated on each iteration until the ML model performance is above a threshold. The resulting model may be used to train a resulting model. In some embodiments, ML models are combined across iterations to improve performance.
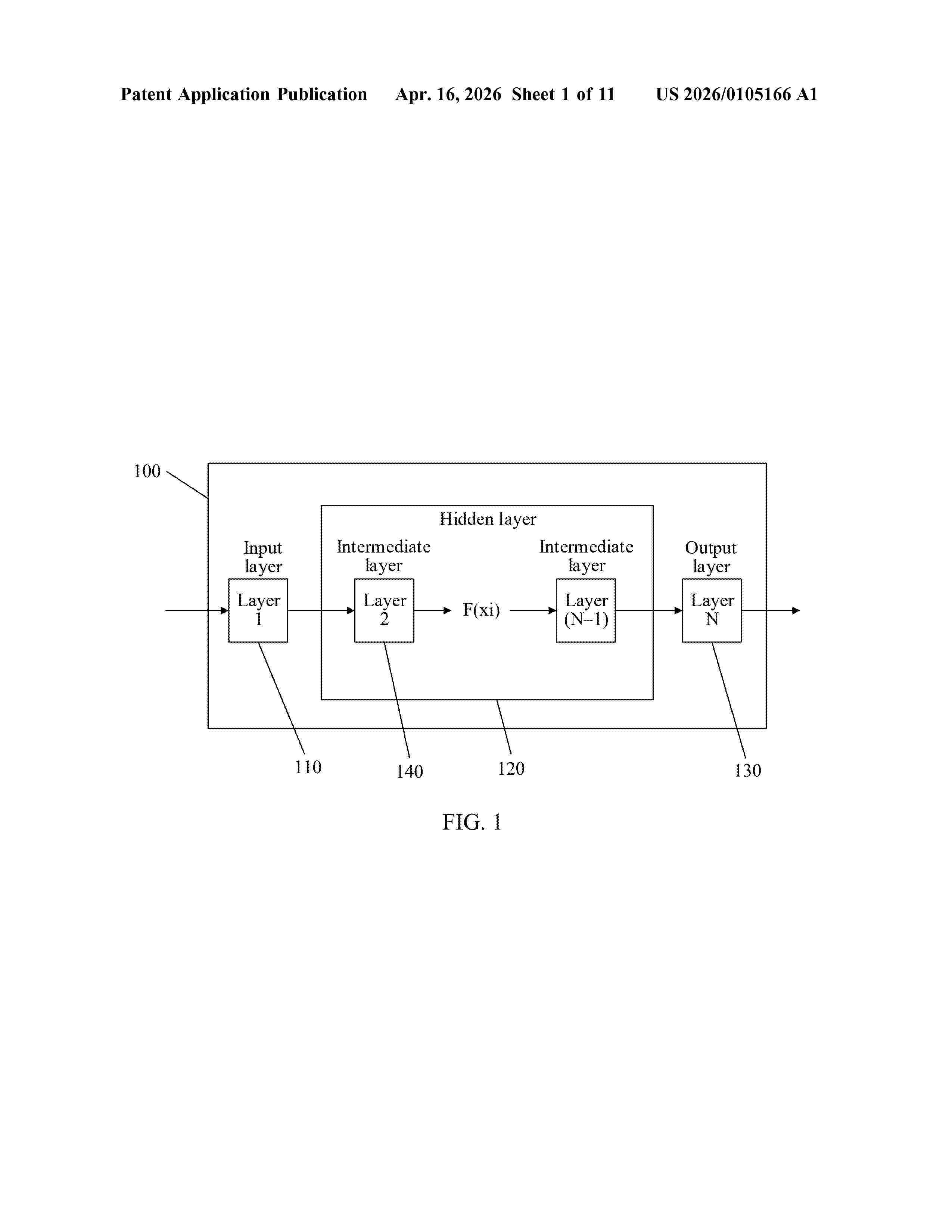
Resumen de: US20260105166A1
A model inference method and apparatus are disclosed, and relates to the field of machine learning technologies. A client and a server use respective deployed models to process different parts of user data, to obtain respective output results. In addition, the client obtains the output result of the server, and obtains an inference result based on the output results of the server and the client. Compared with a case in which the server needs to obtain all the user data in an inference process, in this application, the server obtains only a part of the user data. As the server cannot obtain, based on the part of the user data, all content included in the user data, security of the user data is ensured.
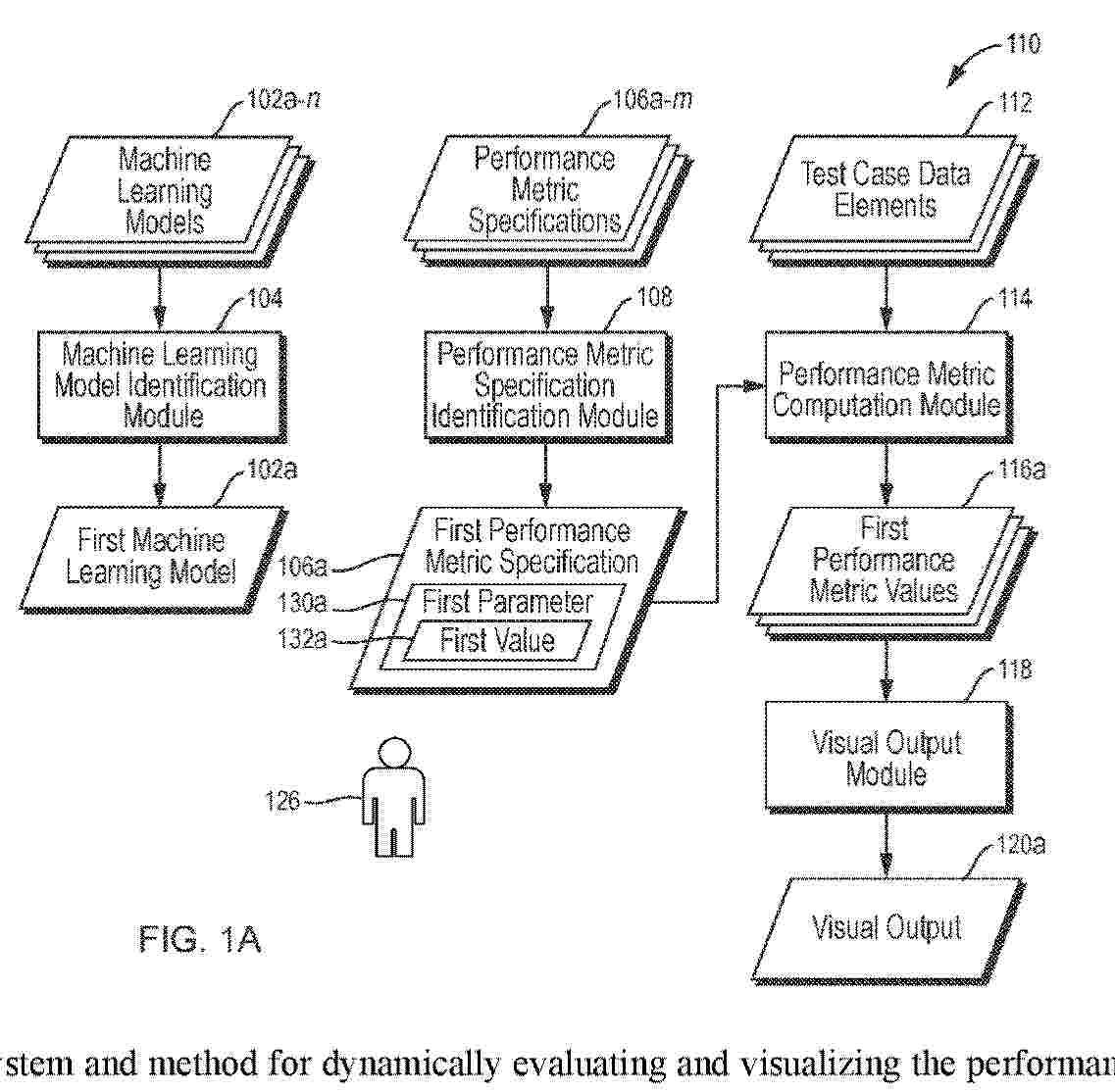
Resumen de: AU2024359770A1
A universal system and method for dynamically evaluating and visualizing the performance of any predictive model, including machine learning models. The system and method compute performance metrics based on test set data and display visual representations in real-time, allowing users to interactively explore model performance by adjusting parameters that reflect model-deployment scenarios. Key features include model-agnostic design, support for both technical and business metrics, and the ability to compare multiple models. The system and method's extensible architecture enables custom metrics and visualizations, making them scalable across various modeling use cases and industries. By providing intuitive, real-time visual feedback, embodiments of the invention empower both technical and non-technical stakeholders to gain deeper insights into model behavior, leading to more informed decisions about deployment and optimization.
Resumen de: AU2026202443A1
Computerized systems and methods are disclosed for automating Configure to Order (CTO) and Quote to Order (QTO) processes. Methods include receiving user inputs for desired product configurations, retrieving corresponding data from a bill of materials database, and calculating optimized pricing through intelligent rules based on real-time market data. Automated quotes are generated and transferred to orders in a vendor system, selected based on pre-set criteria like vendor reputation and delivery time. Validation steps reduce errors, and real-time reports are generated. The system integrates a Real-Time Data Mesh for data aggregation, a Single Pane of Glass User Interface for user interactions, and Advanced Analytics and Machine Learning Modules for implementing rule-based and learning algorithms. The system is accessible across various devices and standardizes data for uniform consumption, while also employing machine learning models to continually optimize processes. Notifications are sent to users upon successful execution of orders or completion of quotes. ar a r
Resumen de: WO2026079735A1
A method for a user equipment comprises the steps of: receiving, from a base station, configuration information about the number Nt (where Nt is a natural number of 1 or more) of a plurality of time instances; receiving, from the base station, configuration information about the number Nb (where Nb is a natural number of 1 or more) of beams to be reported for each of the plurality of time instances; generating an inference result report comprising inference results for Nt*Nb beams; and transmitting the inference result report to the base station, wherein the inference result report comprises one or more reporting units, each of the one or more reporting units comprises inference results for K (where K is a natural number of 1 or more) or less beams, the number of the one or more reporting units is M*Nt, and M may be defined as M=ceiling (Nb/K).
Resumen de: WO2026079733A1
This method of a terminal may comprise the steps of: identifying, from inference result reporting for a plurality of time instances, a candidate set related to the number of beams to be included in a reporting unit for differential reporting; receiving, from a base station, information indicating a first number belonging to the candidate set; and transmitting, to the base station, an inference result report including the reporting unit that includes inference results for the number of beams corresponding to the first number.
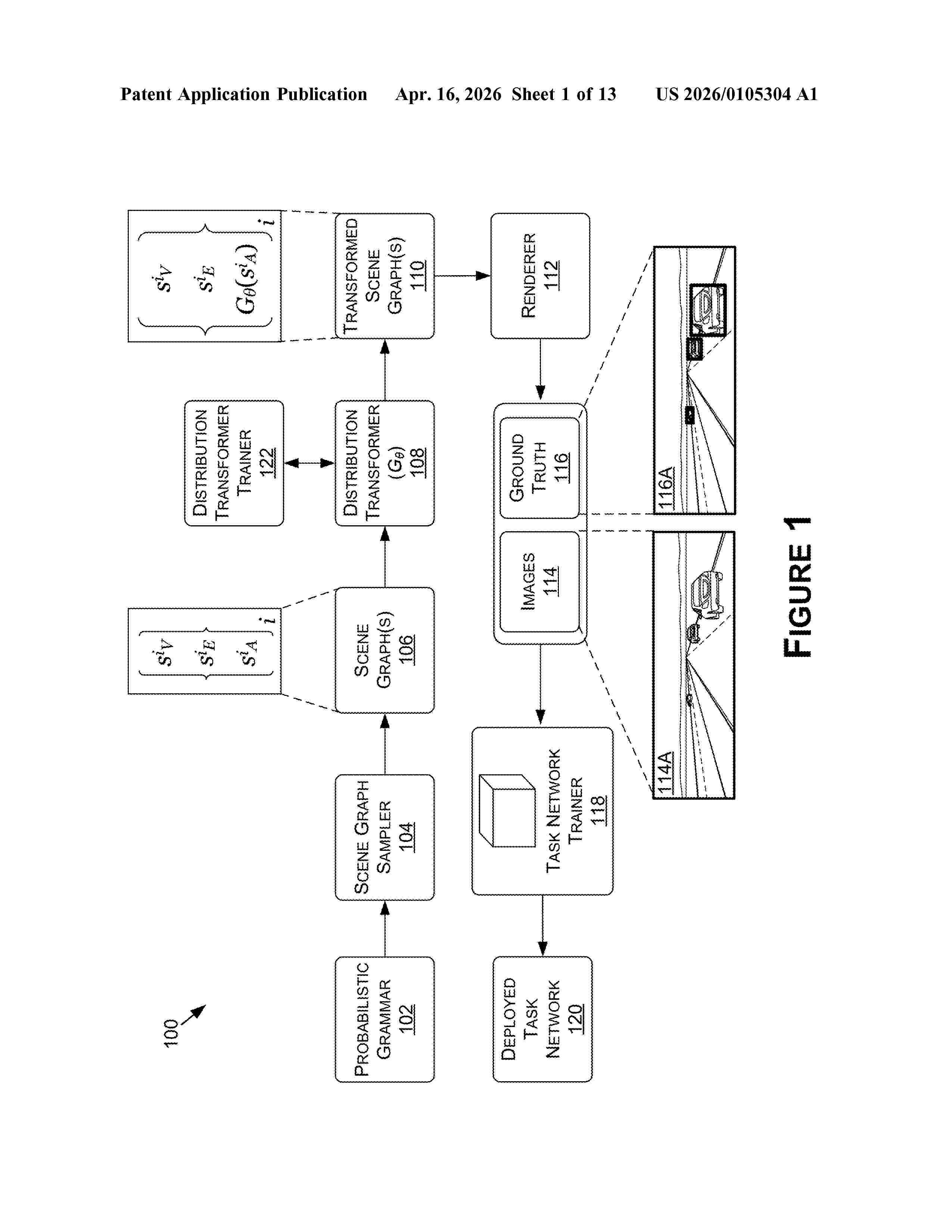
Resumen de: US20260105304A1
In various examples, a generative model is used to synthesize datasets for use in training a downstream machine learning model to perform an associated task. The synthesized datasets may be generated by sampling a scene graph from a scene grammar—such as a probabilistic grammar—and applying the scene graph to the generative model to compute updated scene graphs more representative of object attribute distributions of real-world datasets. The downstream machine learning model may be validated against a real-world validation dataset, and the performance of the model on the real-world validation dataset may be used as an additional factor in further training or fine-tuning the generative model for generating the synthesized datasets specific to the task of the downstream machine learning model.
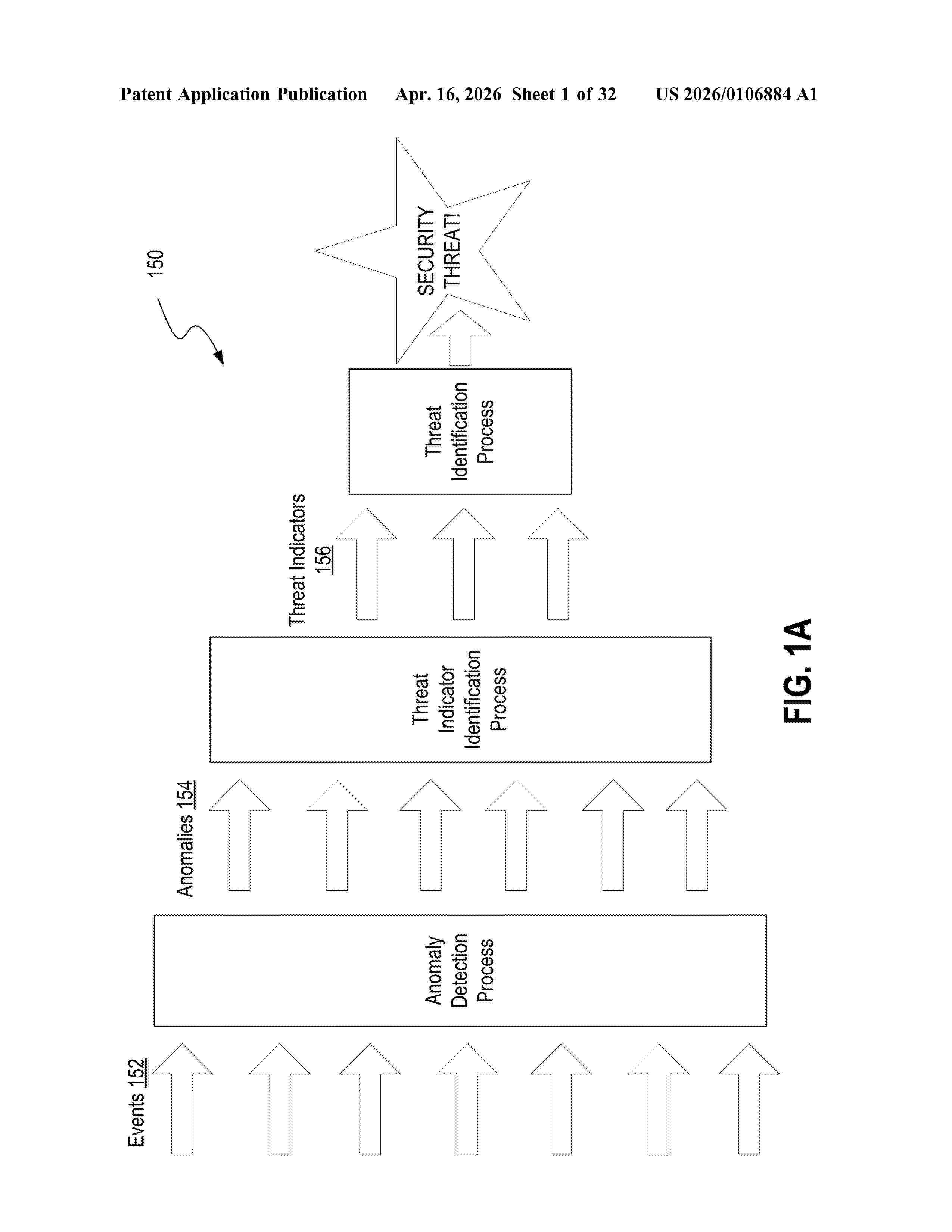
Resumen de: US20260106884A1
First event data, indicative of a first activity on a computer network and second event data indicative of a second activity on the computer network, is received. A first machine learning anomaly detection model is applied to the first event data, by a real-time analysis engine operated by the threat indicator detection system in real time, to detect first anomaly data. A second machine learning anomaly detection model is applied to the first anomaly data and the second event data, by a batch analysis engine operated by the threat indicator detection system in a batch mode, to detect second anomaly data. A third anomaly is detected using an anomaly detection rule. The threat indictor system processes the first anomaly data, the second anomaly data, and the third anomaly data using a threat indicator model to identify a threat indicator associated with a potential security threat to the computer network.
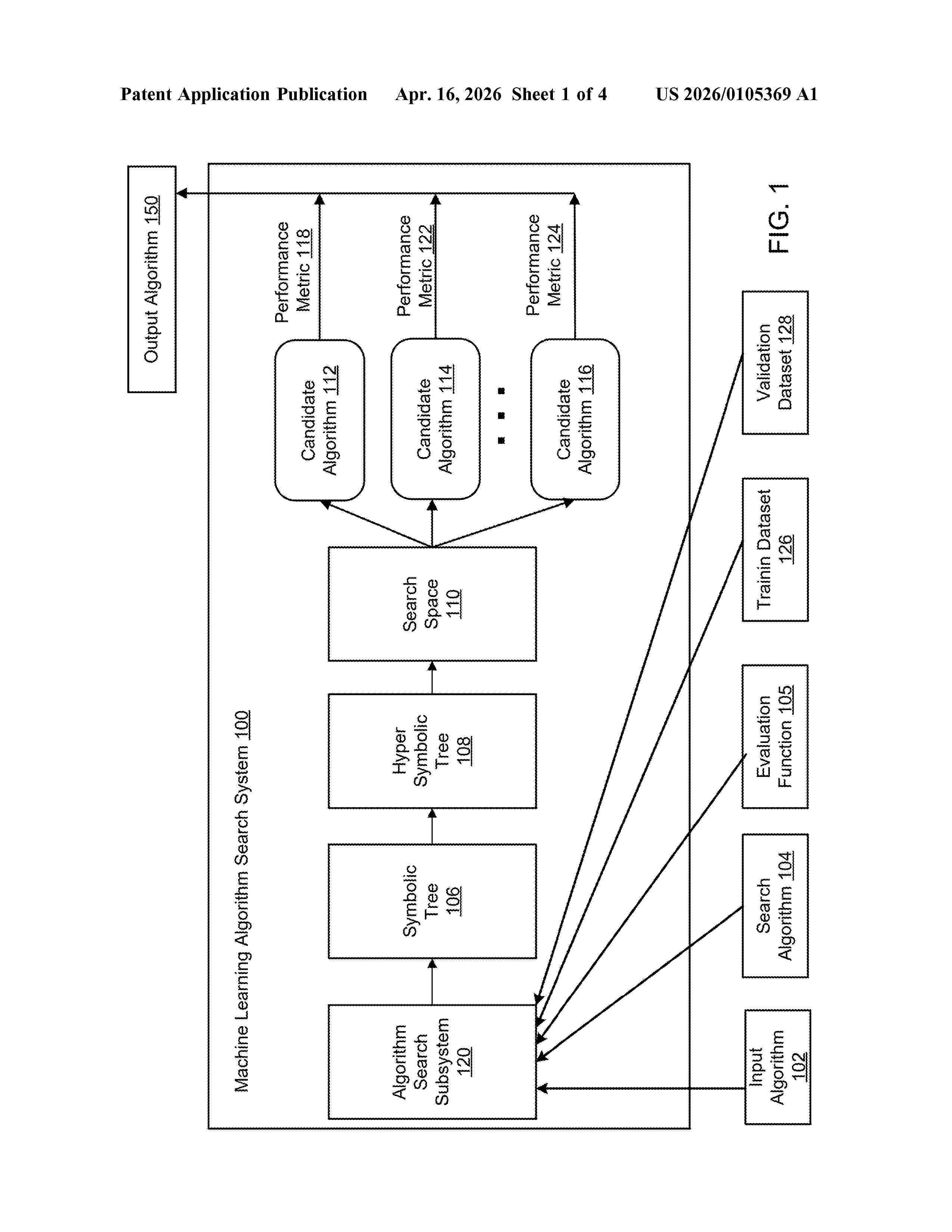
Nº publicación: US20260105369A1 16/04/2026
Solicitante:
GOOGLE LLC [US]
Resumen de: US20260105369A1
A method for searching for an output machine learning (ML) algorithm to perform an ML task is described. The method comprising: receiving data specifying an input ML algorithm; receiving data specifying a search algorithm that searches for candidate ML algorithms and an evaluation function that evaluates the performance of candidate ML algorithms; generating data representing a symbolic tree from the input ML algorithm; generating data representing a hyper symbolic tree from the symbolic tree; searching an algorithm search space that defines a set of possible concrete symbolic trees from the hyper symbolic tree for candidate ML algorithms and training the candidate ML algorithms to determine a respective performance metric for each candidate ML algorithm; and selecting one or more trained candidate ML algorithms among the trained candidate ML algorithms based on the determined performance metrics.
 BOPI
BOPI
 Sede Electrónica
Sede Electrónica